






一、图的存储
1、邻接矩阵
邻接矩阵,故名思意就是用一个矩阵存储图,我们可以创建一个二维数组maze,maze[x][y]可以表示x到y的边;那么该如何处理有边权和无边权呢,对于无边权问题,可以将maze全部初始化为0,然后如果从x到y有边,那就将maze[x][y]赋值为1;对于有边权问题,可以将maze全部初始化为inf,如果x到y有边,那就将maze[x][y]赋值为边权;
有向图 无边权
#include<bits/stdc++.h>
using namespace std;
const int N = 510;
int maze[501][501];
int main()
{
memset(maze,0,sizeof maze);
int n,m;
cin >> n >> m;
//n个点 m条边
while(m--)
{
int x,y;
cin >> x >> y;
maze[x][y] = 1;
}
return 0;
}有向图 有边权
#inlcude<bits/stdc++.h>
using namespace std;
const int N = 505;
int main()
{
memset(maze,0x3f,sizeof maze);
int n,m;
cin >> n >> m;
for(int i = 1;i <= n;++i)
{
maze[i][i] = 0;
//自环
}
while(m--)
{
int x,y,z;
cin >> x >> y >> z;
maze[x][y] = min(maze[x][y],z);
}
return 0;
}这里存边权保存最小的边权!
如果是无向图那就再多给maze[y][x]赋值一下就可以了;
但是这种存储方式有个缺点,一般oj题都是1s的时间,1s时间通常只能处理1e8的数据规模,但邻接矩阵是O(N^2)级别的,也就是没法处理1e5以上的数据,而且空间利用率不高,浪费很多开了但没存边的空间;这时候就要用到第二种存储方式-----邻接表
2、邻接表
邻接表的本质是链表,但是为了存储效率,这里采用数组模拟链表;
大致思路是:
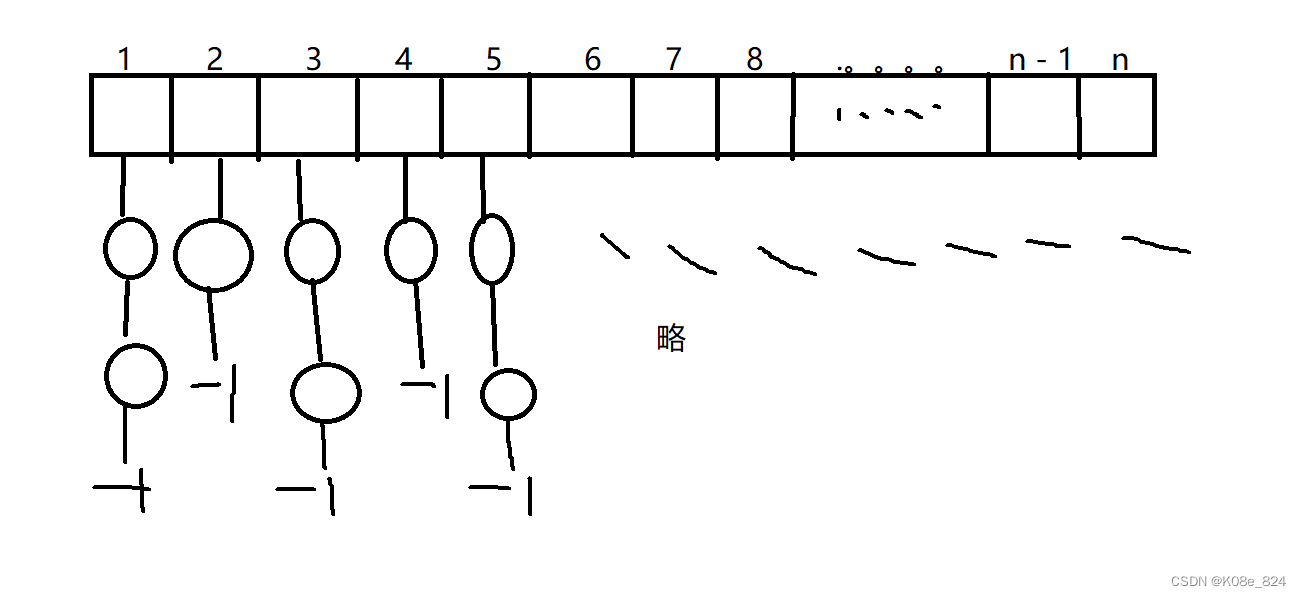
将输入的起点,作为下标,将输入的终点,连接到下标的链表上,比如图中的1后面跟着的两个节点,就是1为起点可以走到的两个节点,2后面跟着一个节点,就是2为起点可以走到的节点;以此类推。。。
如果还觉得有些抽象,可以给出一个例子:
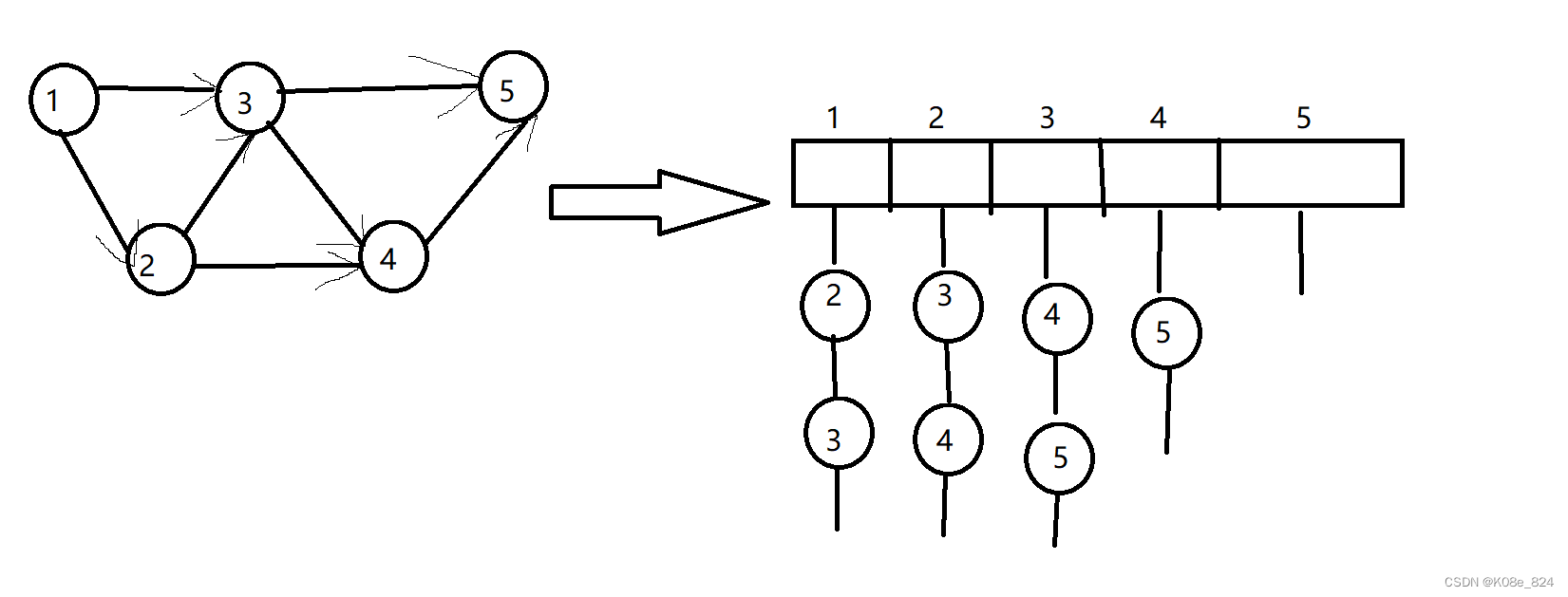
将左边的图转变成右边的邻接表就是这样。
那么如何实现对于某个节点的插入呢?
我们这里采用数组模拟链表,所以插入和链表的插入类似:
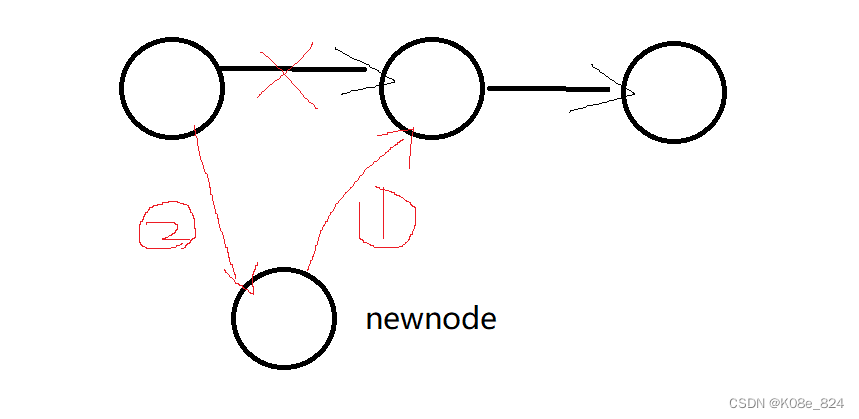
先要将节点连入链中,避免找不到插入节点的下一个节点。
而这一切的实现都是基于一个计数变量idx;
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
int head[N], e[N], ne[N], w[N], idx;
void add(int x, int y, int z)
{
e[idx] = y;
w[idx] = z;
ne[idx] = head[x];
head[x] = idx++;
}
int main()
{
int n;
cin >> n;//n张图
while (n--)
{
memset(head, -1, sizeof head);
idx = 0;
int m;
cin >> m;
while (m--)
{
int x, y, z;
cin >> x >> y >> z;
add(x, y, z);
//如果无向图,那就加上
//add(y,x,z);
}
}
return 0;
}
这里head就是上面图中的横条数组,同时还需要设置一个结束的标志,为了之后方便遍历,不然之后要遍历某个节点的边,从head数组上一路往下遍历,什么时候遍历结束呢?所以这里将-1设置为结束标志,最开始将head数组全部初始化为-1,因为最开始没有插入任何边;
e数组用来储存与x相连的点,e[x]的值表示以x为起点,ne[x]为终点的边;
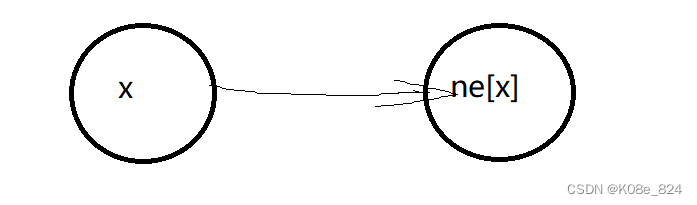
ne数组用来存储该点的下一个节点,ne[x]表示x的后一个节点是谁;
比如上图的
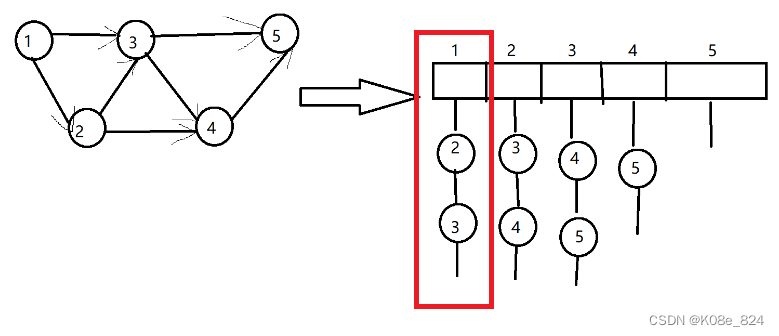
在这个框框内,ne[②]的值为3,ne[③]的值为-1,但是大家可能有疑问,这里的下标我为什么用的②而不是2,③而不是3,这是因为计数变量idx的作用:
如果这里是3不是③,那看红方框右边一格,也有个3,那ne[3]到底 保存谁呢?
所以这里用了idx这个计数变量,让每个节点都有不同的idx,从而值相同的节点可以通过idx不同保存在ne中;所以上面提到的ne[②],ne[③],这个②和③具体多少是不一定的,要看这个②和③是第几个插入的;
这里比较难以理解,可以多看几遍,代码放进编译器里面调试几遍。
二、图的遍历
1、邻接矩阵的遍历
二维数组的遍历,没什么好说的
2、邻接表的遍历
邻接表的遍历其实更像是dfs的过程,确定一个节点之后,一条路一直往下走,直到碰见结束标志。
void dfs(int u)
{
vis[u] = true;
for (int i = head[u]; i != -1; i = ne[i])
{
int j = e[i];
if (!vis[j])
{
dfs(j);
}
}
}这里先给出要遍历的head数组下标,然后从head[u]开始,只要没到-1,那就一直i = ne[i],为了避免重复遍历,所以还需要一个vis数组,打标记,如果为true就直接跳过;
完整代码:
#define _CRT_SECURE_NO_WARNINGS
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
int head[N], e[N], ne[N], w[N], idx;
bool vis[N];
void add(int x, int y, int z)
{
e[idx] = y;
w[idx] = z;
ne[idx] = head[x];
head[x] = idx++;
}
void dfs(int u)
{
vis[u] = true;
for (int i = head[u]; i != -1; i = ne[i])
{
int j = e[i];
if (!vis[j])
{
dfs(j);
}
}
}
int main()
{
int n;
cin >> n;//n张图
while (n--)
{
memset(head, -1, sizeof head);
idx = 0;
int m;
cin >> m;
while (m--)
{
int x, y, z;
cin >> x >> y >> z;
add(x, y, z);
//如果无向图,那就加上
//add(y,x,z);
}
}
return 0;
}这里再提一句,邻接表只是画出来是存储的节点,这样是为了方便理解,实际上,以head数组每一个下标为头节点存储的都是idx的值,然后通过idx找到e[idx],w[idx]















 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









