







原文链接
A Closer Look at Few-shot Classification Again
摘要
这篇文章主要探讨了在少样本图像分类问题中,training algorithm 和 adaptation algorithm的相关性问题。给出了training algorithm和adaptation algorithm是完全不想关的,这意味着我们在设计少样本学习算法时,可以分别设计模型的training阶段和adaptation阶段。同时文章也在训练集规模、监督学习和自监督学习在少样本学习中的性能、以及标准finetune在少样本图像分类adaptation阶段对模型影响的问题。
Training 和 Adaptation 算法完全不相关
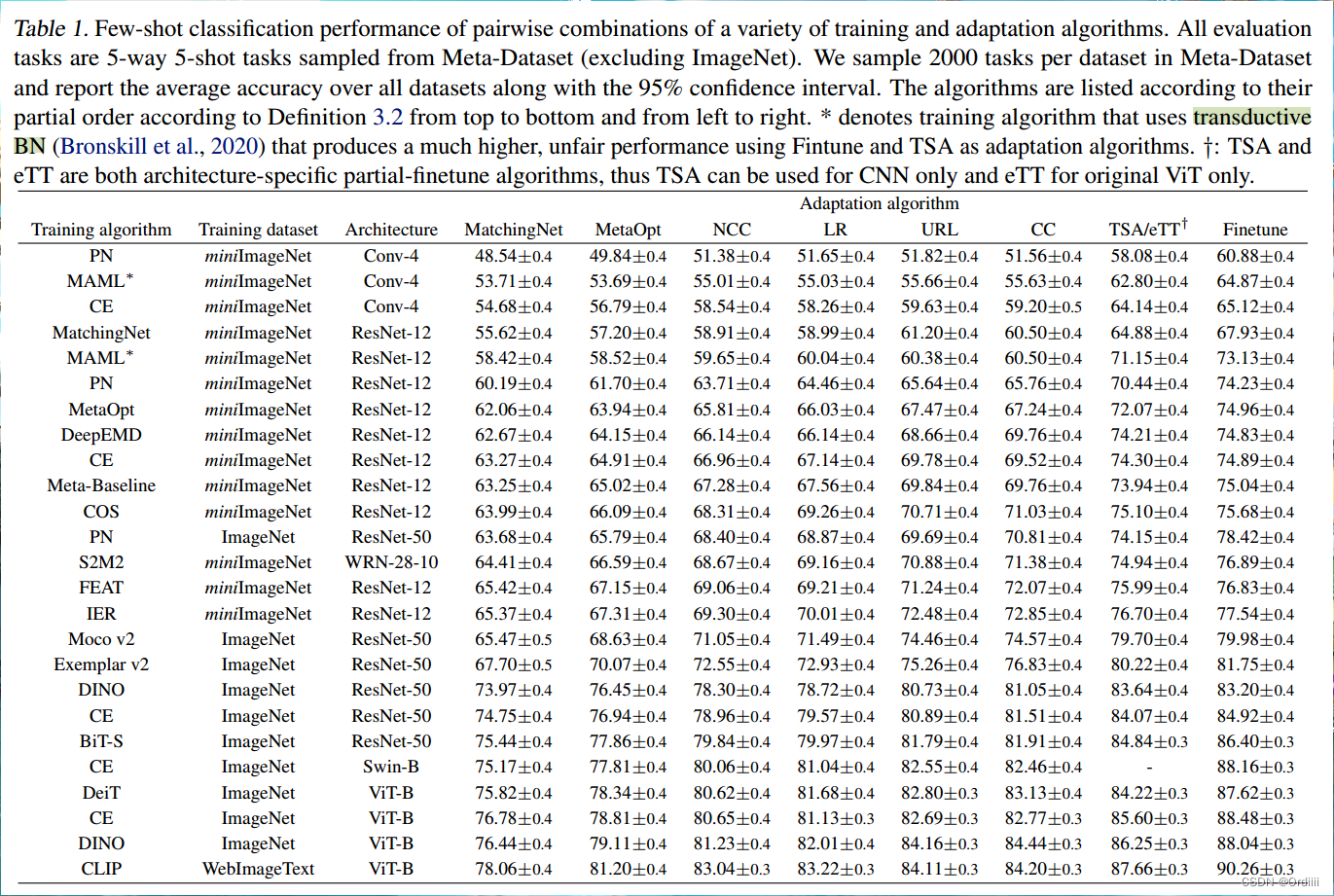
如图,行为training算法,列为adaptation算法。对于行,表示的是不论采用什么样的training算法,adaptation算法对应的性能偏序关系都是一样的;对于列,表示的是不论采用什么样的adaptation算法,training算法对于的性能偏序关系都一样。实验说明两个算法是完全不想关的,因此对于未来更优模型的研究,我们可以分别设计training和adaptation阶段的算法。
training阶段让模型“看到”更多的类使得模型更能适应新类别
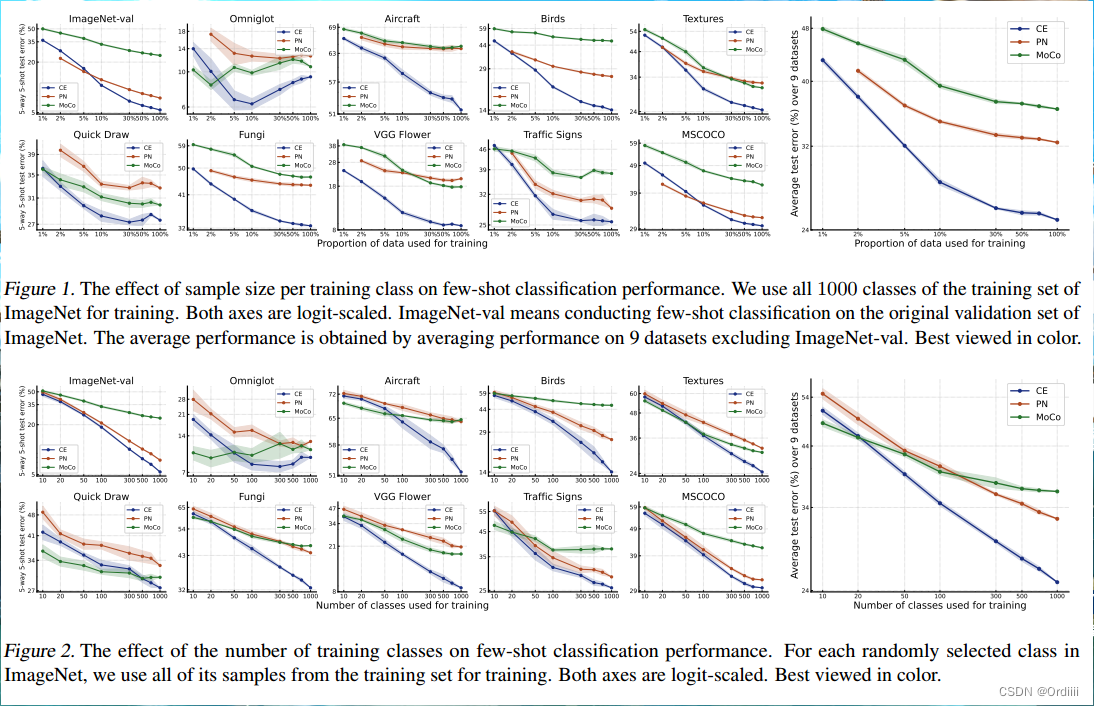
如图,在训练算法和适应算法不变的情况下,对十种不同的训练集进行adaptation。如Figure1,2所示,training阶段增加训练的class数量对性能的提升比增加sample的数量更加高效。
自监督学习在少样本图像分类中表现优于监督学习
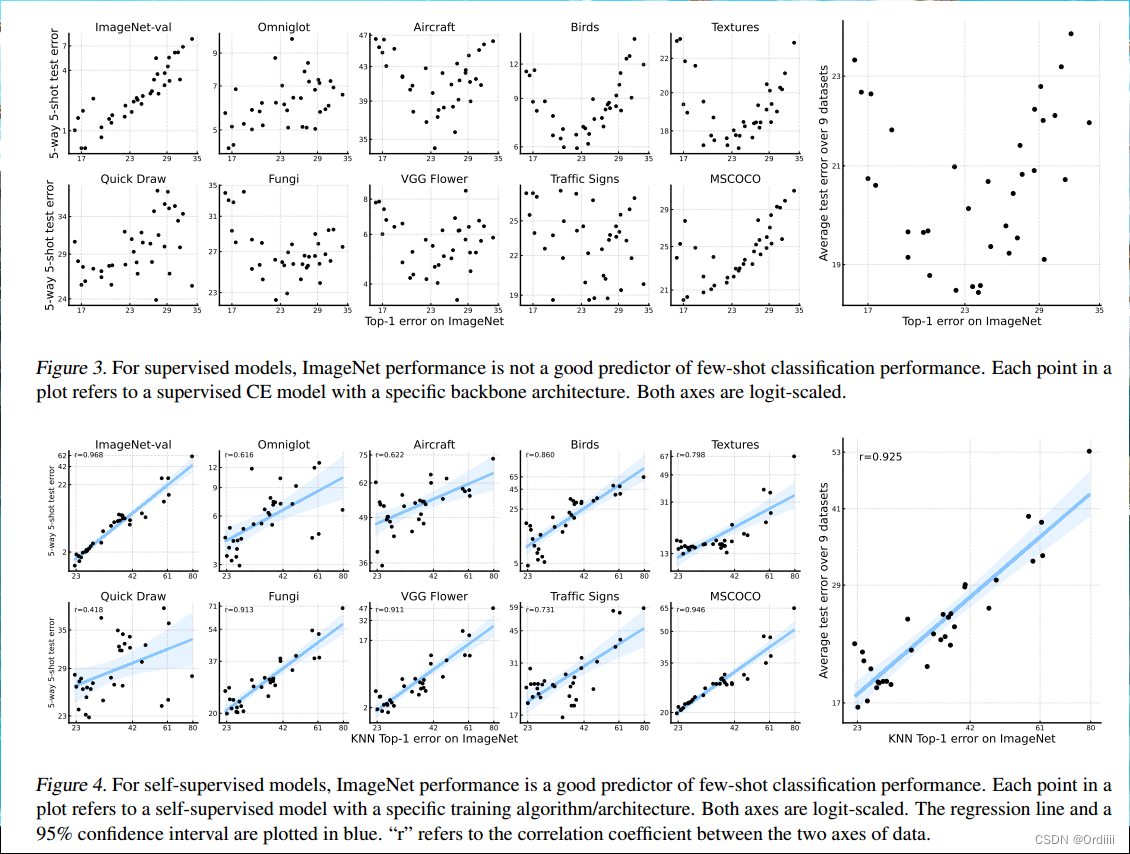
Figure3每一个点表示的是监督学习模型,Figure4每一个点表示自监督学习模型。Figure3所示,监督学习在性能更好的模型下,通过少样本的调整后,性能反而效果不佳,这说明性能更优的监督模型一定程度上在训练集上过拟合了。
反观自监督学习,自监督学习模型本身的性能和通过少样本微调过后的性能基本呈现线性关系,因此可以说在少样本图像分类问题中,将自监督学习作为backbone网络优于将监督学习作为backbone网络。
training阶段增加sample数量对性能的提升优于增加class数量
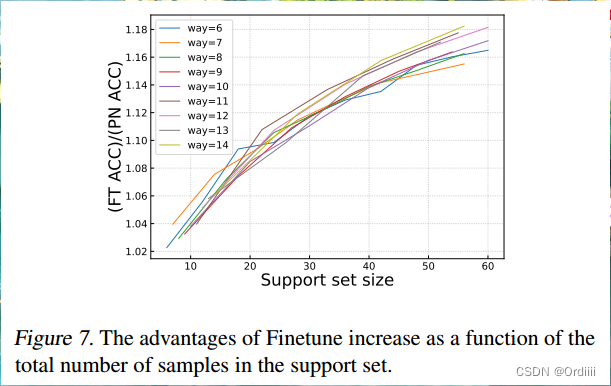
可以看到,如果固定Support set size,不同的class数量对性能的影响较小。而增加support set size对于性能的影响较大。
vanilla Finetune效果最好
与之前的一些研究得出的在少样本上Finetune会导致模型的过拟合不同,本文通过实验反而表明,Vanilla Finetune反而带来最佳性能,并且backbone和linear head采用不同的learning rate效果更优。
讨论
文章分析得出,一味的增加训练数据规模并不是一劳永逸的解决方法,我们可以多关注训练知识和调整所需的知识的对齐。如何不像finetune那样暴力的自适应算法,用一种更加精准的对模型进行微调的方法是我们未来可以研究的一点。














 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









