







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
Hadoop集群测试
通过UI界面查看Hadoop运行状态
Hadoop集群正常启动后,它默认开放了两个端口9870和8088,分别用于监控HDFS集群和YARN集群。通过UI界面可以方便地进行集群的管理和查看,只需要在本地操作系统的浏览器输入集群服务的IP和对应的端口号即可访问:
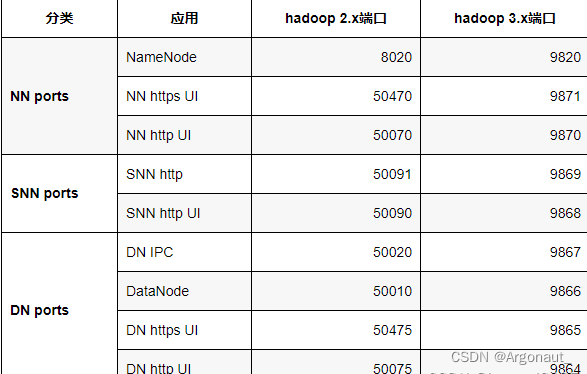
一、hadoop2和hadoop3端口区别表
2、查看HDFS集群状态
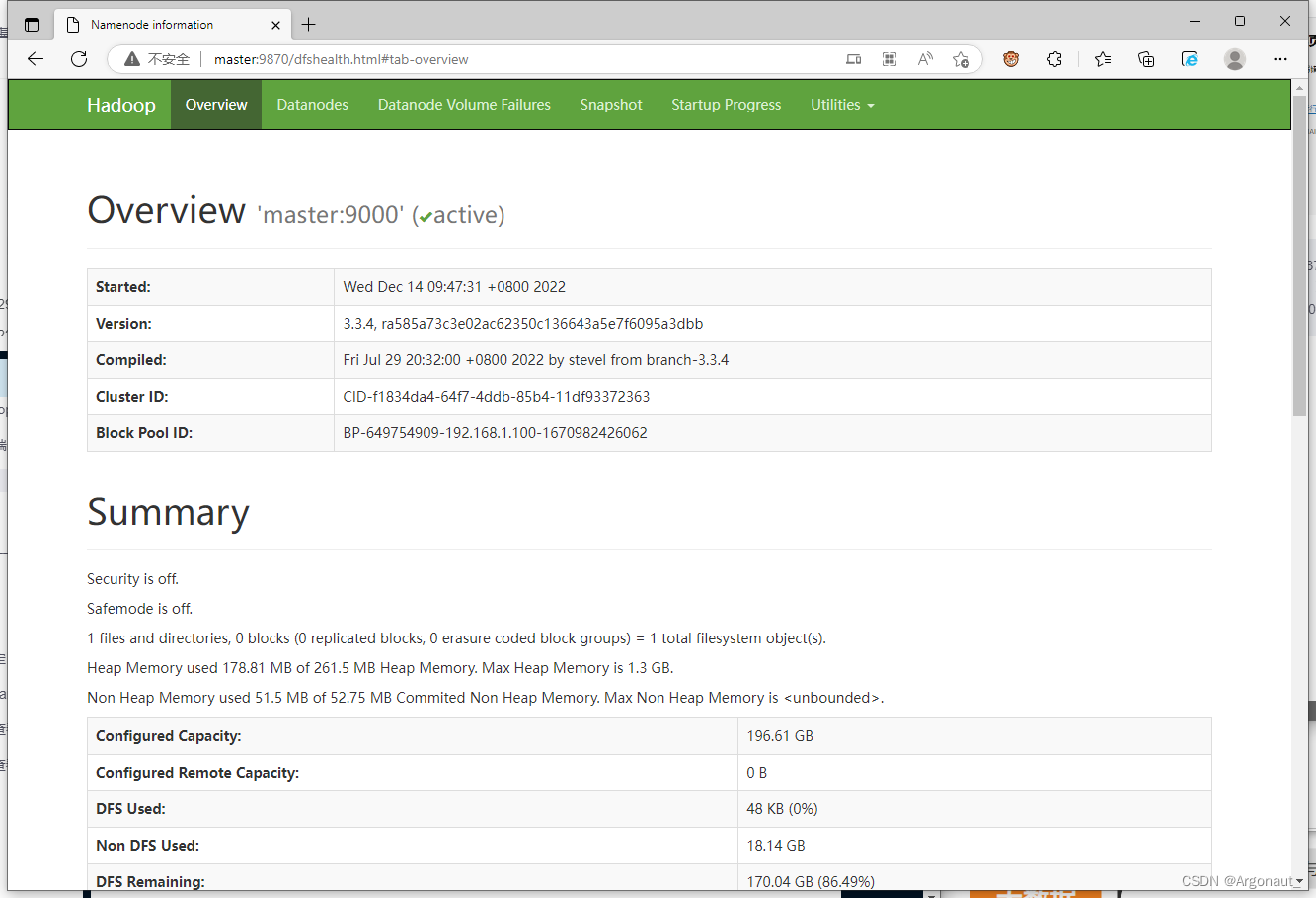
在浏览器里访问 http://master:9870
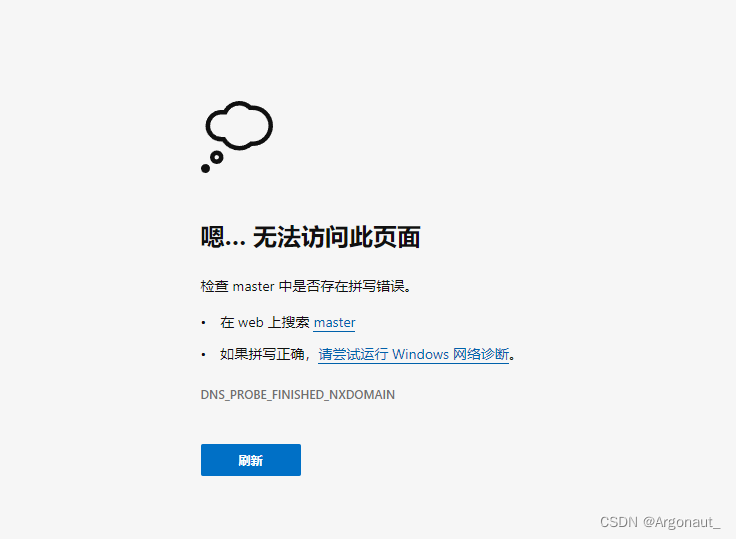
不能通过主机名master加端口9870的方式,原因在于没有在hosts文件里IP与主机名的映射,现在只能通过IP地址加端口号的方式访问:http://浮动ip:9870
-
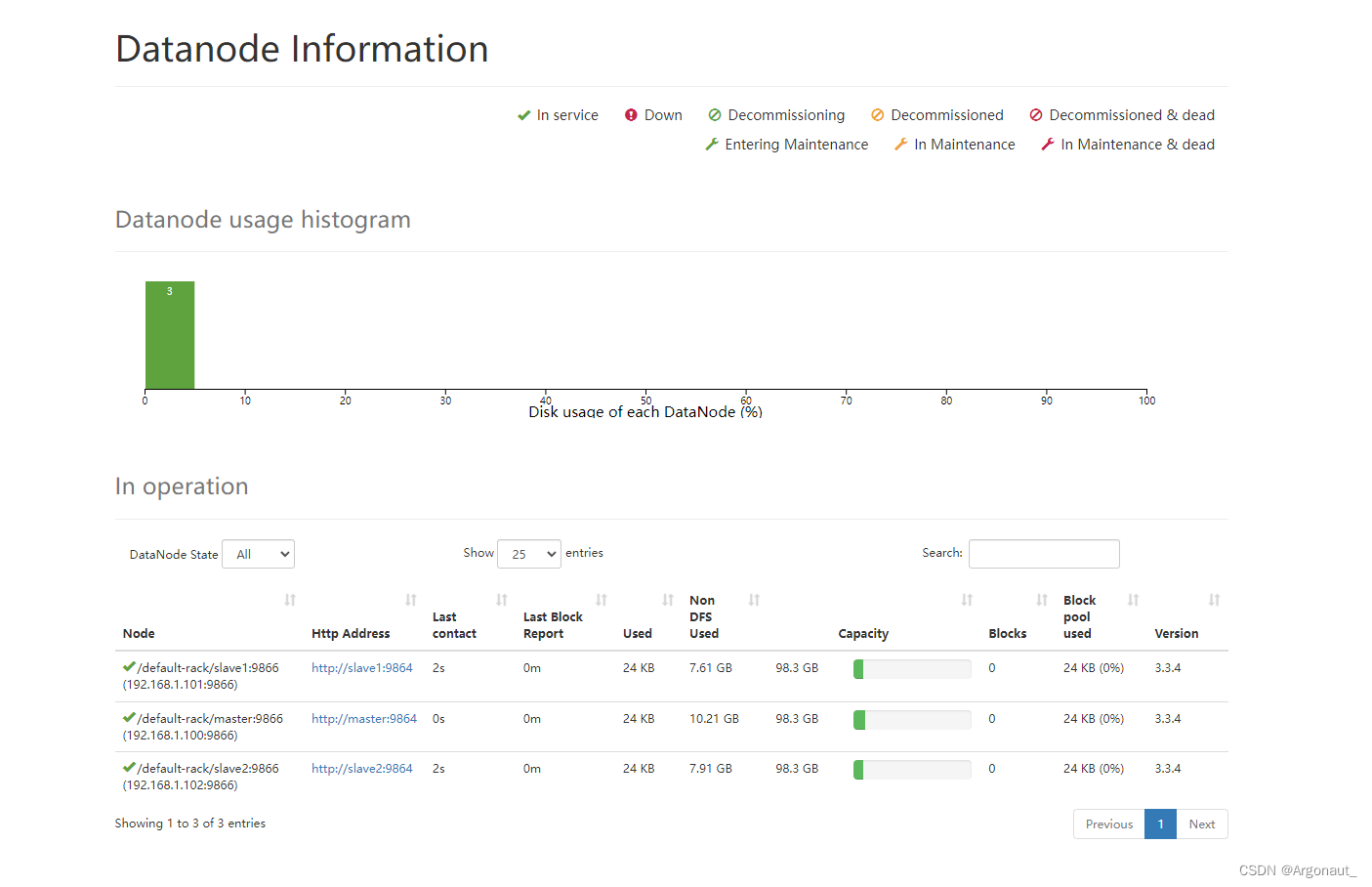
单击导航条上的【Datanodes】,查看数据节点信息
-
访问slave1的数据节点(DataNode)
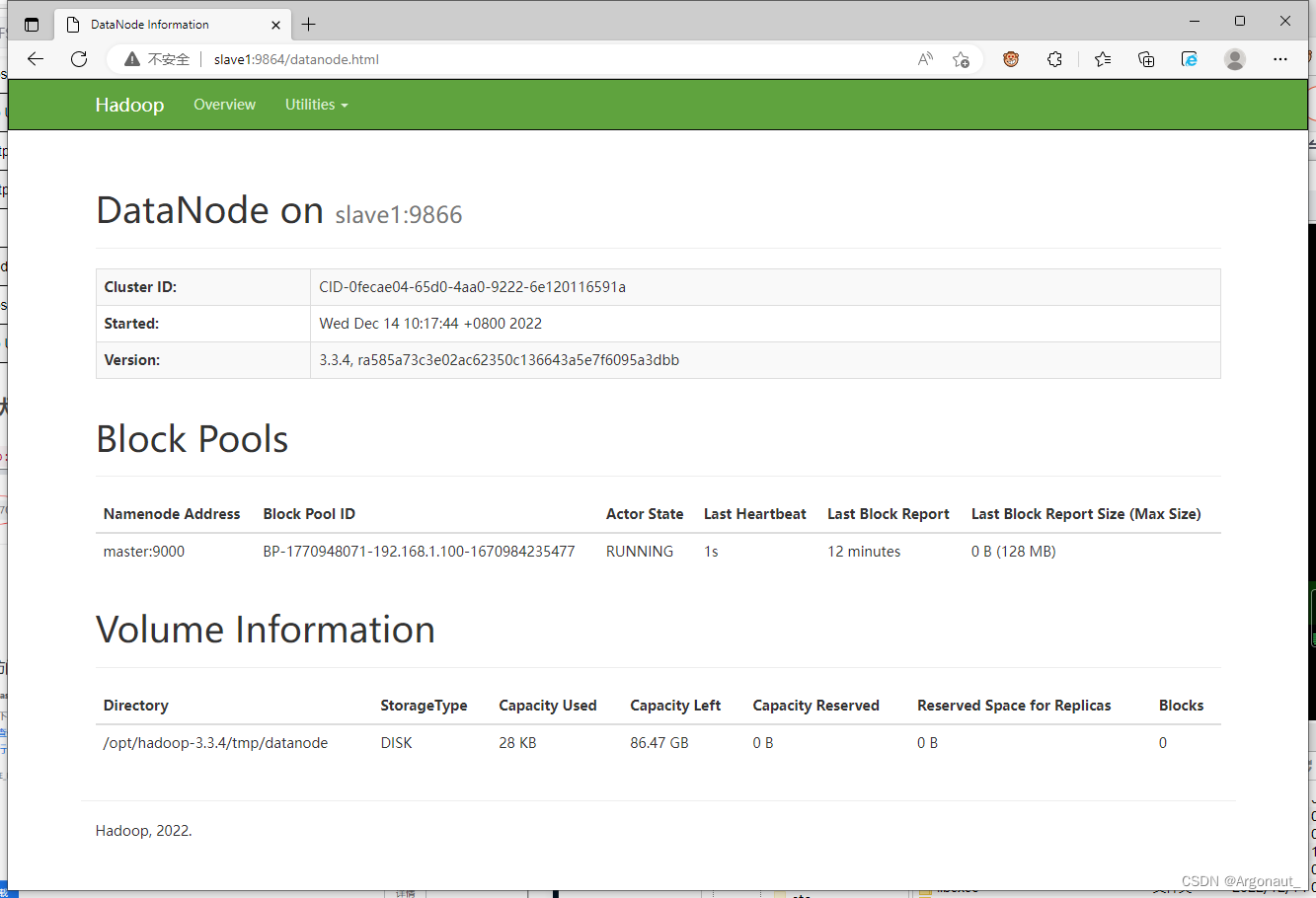
-
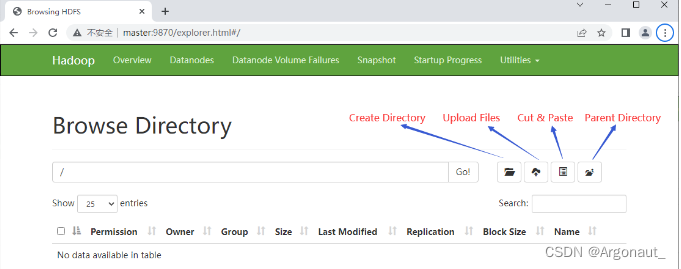
点开【Utilities - 实用工具】下拉菜单,选择【Browse the file system - 浏览文件系统】

-
此时HDFS上什么东东都木有
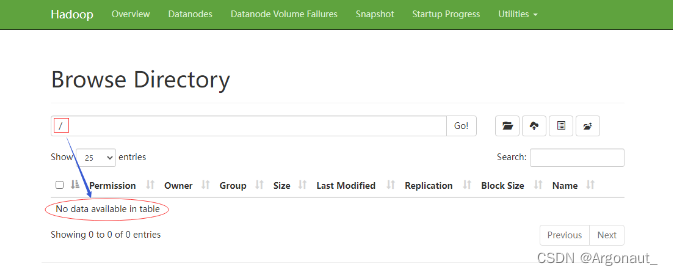
-
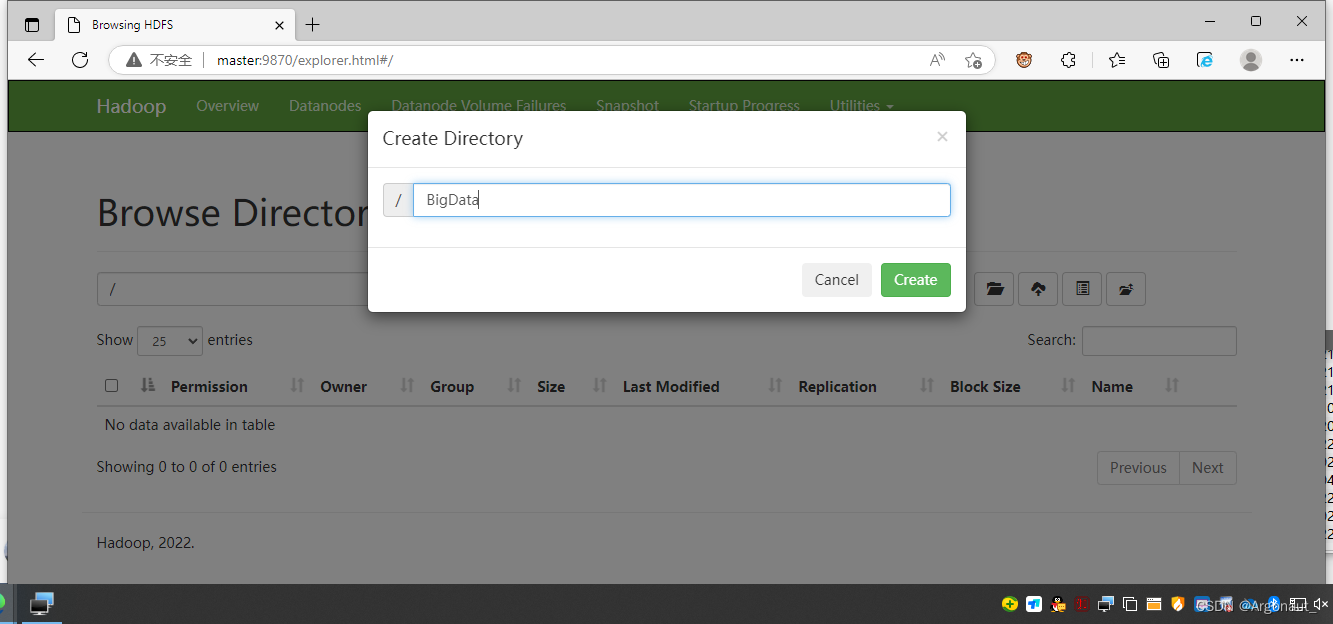
在HDFS上创建一个目录BigData,既可以在WebUI上创建,也可以通过shell命令创建
-
执行命令:hdfs dfs -mkdir /BigData

-
在Hadoop WebUI界面查看刚才创建的目录
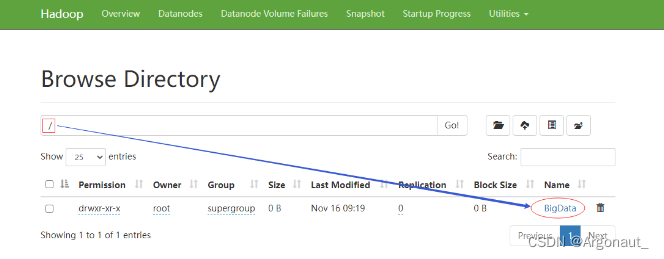
-
单击【BigData】右边的删除按钮
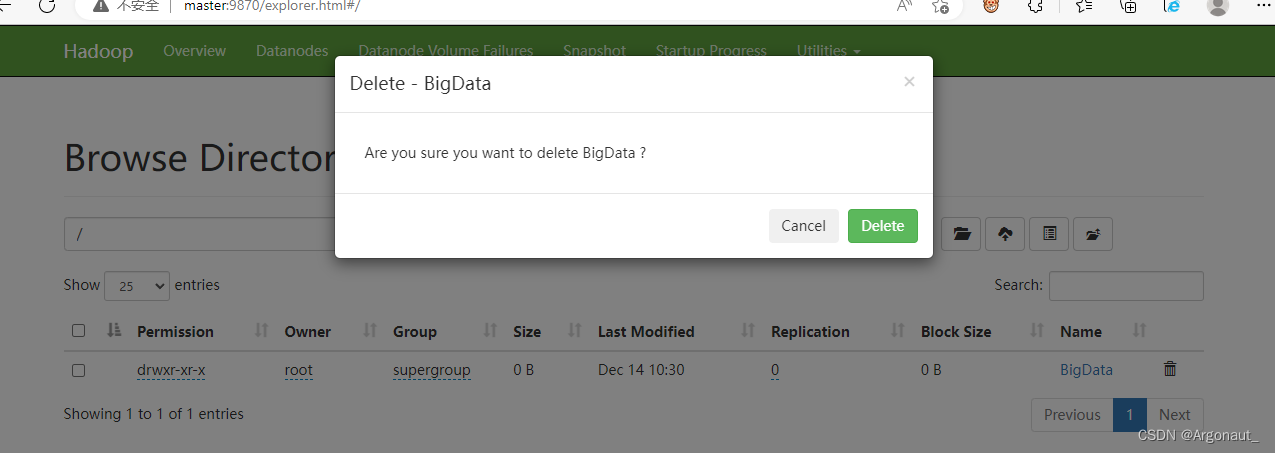
- 查看四个功能按钮
- 在Hadoop WebUI界面里创建目录
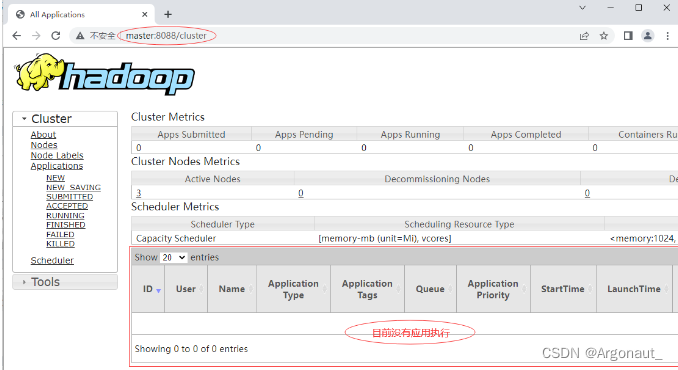
查看YARN集群状态
- 访问http://master:8088/cluster,从图中可以看出YARN集群状态显示正常
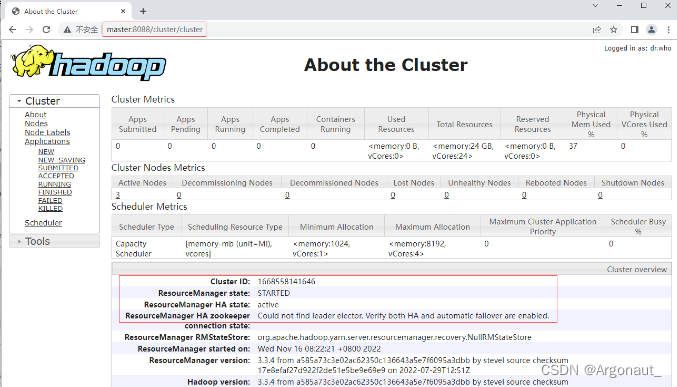
- 单击【About】链接
Hadoop集群初体验 —— 词频统计
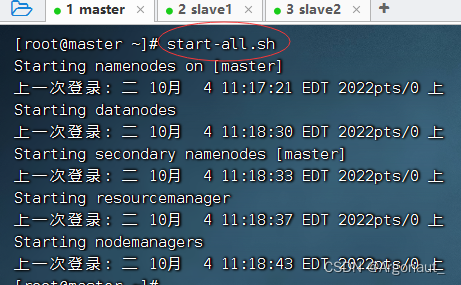
1、启动Hadoop集群
- 在master虚拟机上执行命令:start-all.sh
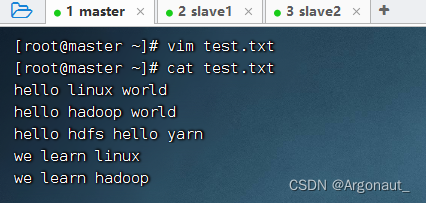
2、在虚拟机上准备文件
- 在master虚拟机上创建test.txt文件
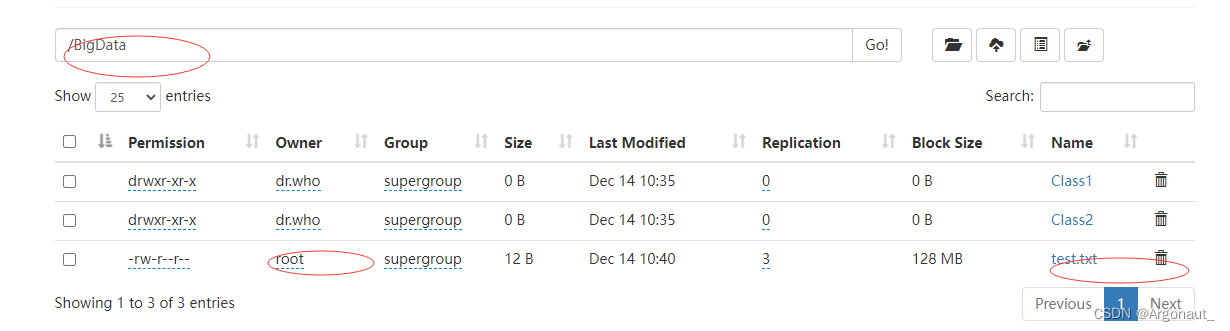
3、文件上传到HDFS指定目录
- 上传test.txt文件到HDFS的/BigData目录(如果没有就创建目录)

- 利用HDFS命令查看文件是否上传成功

- 利用Hadoop WebUI查看文件是否上传成功
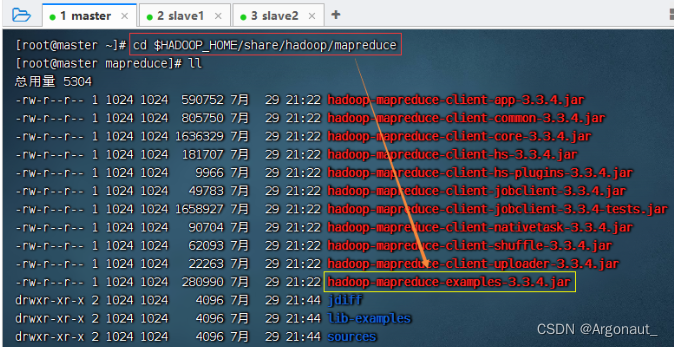
4、运行词频统计程序的jar包
- 查看Hadoop自带示例的jar包
- 执行命令:hadoop jar ./hadoop-mapreduce-examples-3.3.4.jar wordcount
/BigData/test.txt /wc_result
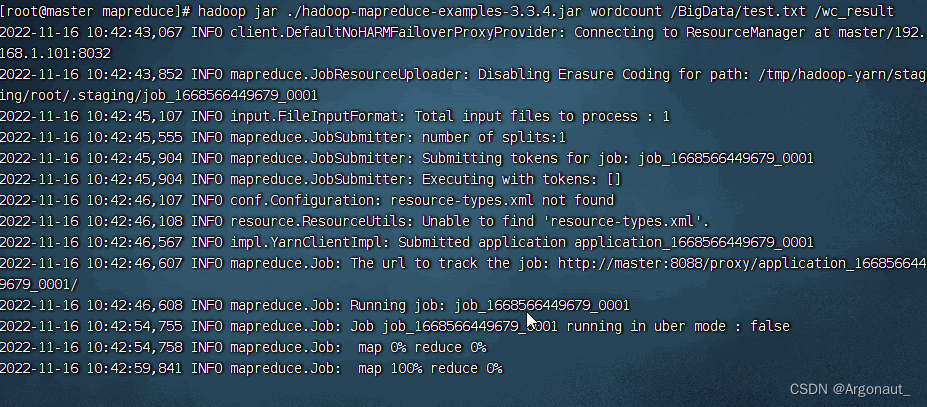
- 说明:作业编号 - job_1668566449679_0001,读取90个字节,写入60个字节
- 查看输出目录/wc_result,执行命令:hdfs dfs -ls /wc_result

- 查看词频统计结果,执行命令:hdfs dfs -cat /wc_result/*

5、在HDFS集群UI界面查看结果文件
- 在HDFS集群UI界面,查看/wc_result目录
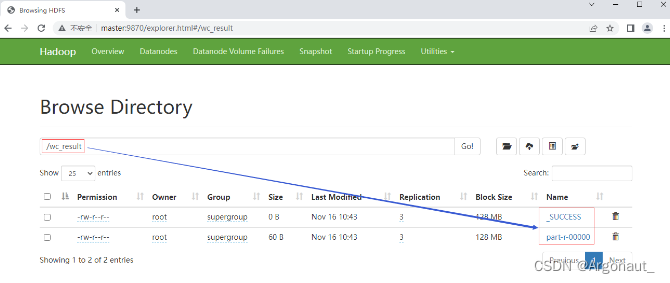
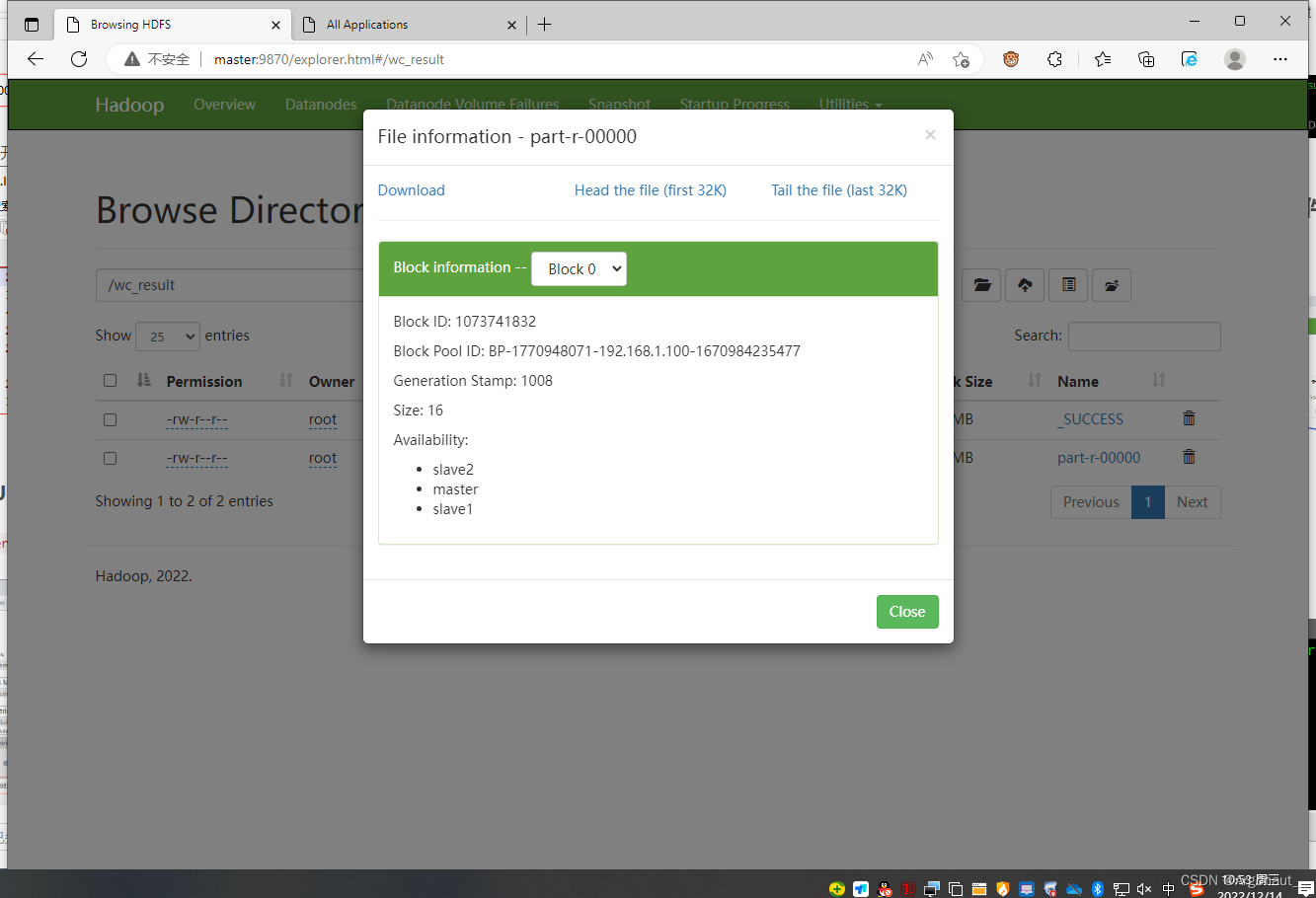
- 下载可查看
6、在YARN集群UI界面查看程序运行状态
- 访问http://master:8088,看到FINISHED和SUCCEEDED
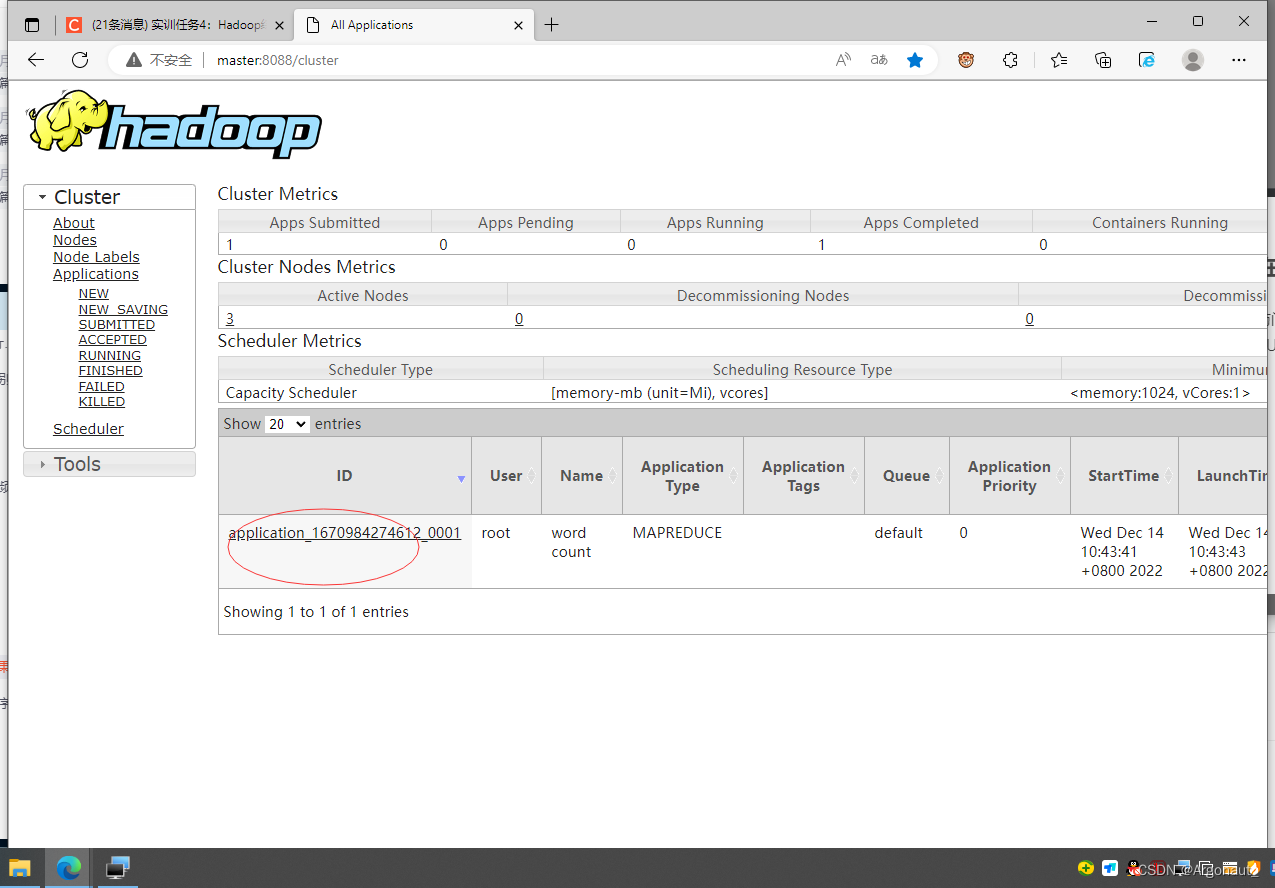
- 单击应用标识application_1668566449679_0001(注意:每次运行同一个应用,应用标识会发生变化),查看应用的运行详情
















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









