






Python的结巴(jieba)库是一个中文分词工具,主要用于对中文文本进行分词处理。它可以将输入的中文文本切分成一个个独立的词语,为后续的文本处理、分析、挖掘等任务提供基础支持。结巴库具有以下功能和特点:
-
中文分词: 将中文文本按照一定的规则和算法切分成独立的词语,方便后续的文本处理和分析。
-
支持不同分词模式: 结巴库支持精确模式、全模式和搜索引擎模式等不同的分词模式,满足不同场景下的需求。
-
支持自定义词典: 用户可以根据实际需求自定义词典,增加、删除或修改词语,提高分词的准确性。
-
高效处理: 结巴库采用了基于前缀词典的分词算法,具有较高的分词速度和效率。
-
开源免费: 结巴库是一个开源项目,可以免费获取并在各种应用中使用,广泛应用于文本处理、自然语言处理等领域。
本次将展示一个使用jieba库生成16首歌曲歌词文本关键词词云的示例,演示的形象化表达如下:

1.用jieba库进行不同模式的分词
示例代码:
import jieba # 导入结巴模块
seg_list=jieba.cut('我来到北京清华大学',cut_all=True) # 使用全模式分词将文本"我来到北京清华大学"进行分词
# (cut_all=True)将使用全模式将句子中所有可能的词语都进行分词,可能会产生大量的冗余词语,这种模式适用于对文本进行初步分析或者处理速度要求较高的场景
print("全模式:"+"/".join(seg_list))
seg_list = jieba.cut("我来到北京清华大学", cut_all=False) # (cut_all=False或者不指定参数)将使用精准模式分词将文本"我来到北京清华大学"进行分词
print("精准模式:"+"/".join(seg_list))
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精准模式
print(','.join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
# 搜索引擎模式是在精准模式的基础上,对长词再次切分,以适应搜索引擎的需求,这种模式适用于对文本进行搜索引擎优化或者需要更多精准匹配的场景
print(','.join(seg_list))
运行结果:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\26320\AppData\Local\Temp\jieba.cache
Loading model cost 0.398 seconds.
Prefix dict has been built successfully.
全模式:我/来到/北京/清华/清华大学/华大/大学
精准模式:我/来到/北京/清华大学
他,来到,了,网易,杭研,大厦
小明,硕士,毕业,于,中国,科学,学院,科学院,中国科学院,计算,计算所,,,后,在,日本,京都,大学,日本京都大学,深造
2.根据歌词文本文件使用jieba库分析功能生成词云
将指定文件夹‘lyric’中的所有文本文件的内容合并到一个字符串中,并打印出这个字符串。该文件夹中共有16首歌曲的歌词文本文件和两张图片。
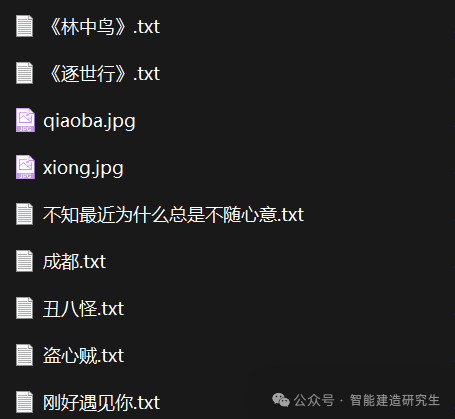
import os # os模块用于处理文件路径
content='' # 定义空字符串content用于存储所有文本文件的内容
content_path=r'F:\桌面\python100\files\lyric' # 设置变量content_path为指定的文件夹路径
files=os.listdir(content_path) # 使用os.listdir()函数列出指定文件夹中的所有文件和子文件夹,将结果存储在列表files中
for file in files: # 遍历files列表中的每一个文件或子文件夹
full_path=os.path.join(content_path,file) # 使用os.path.join()函数将文件夹路径和文件名拼接成完整的文件路径,存储在变量full_path中
print(full_path)
if full_path.endswith('.txt'): # 如果文件路径以.txt结尾
f=open(full_path,'r',encoding='utf-8') # 使用open()函数以只读模式打开文本文件,指定编码为UTF-8,返回文件对象f
content+=f.read() # 读取文件对象f的内容,并将其追加到content字符串中
else: # 如果文件不是文本文件(不以.txt结尾),则跳过
pass
print(content) # 打印合并后的所有文本文件的内容字符串
F:\桌面\python100\files\lyric\qiaoba.jpg
F:\桌面\python100\files\lyric\xiong.jpg
F:\桌面\python100\files\lyric\《林中鸟》.txt
F:\桌面\python100\files\lyric\《逐世行》.txt
F:\桌面\python100\files\lyric\三生三世.txt
···
F:\桌面\python100\files\lyric\灵主不悔.txt
F:\桌面\python100\files\lyric\盗心贼.txt
《林中鸟》
词曲:高进
演唱:葛林
编曲:张亮
混音:侯春阳
来不及祈祷就开始奔跑
总觉得外面世界有多美好
···
盗心的贼
我的一腔热血就化作眼泪
不要再让我悲伤 如痴如醉
再爱一回
将上面的读取指定文件夹中的所有文本文件(.txt)并将它们的内容读取并合并到一个字符串中的操作完整地封装成一个 read_content()函数。
import os
# 读取指定路径下的所有文件,返回所文件接起来的内容
def read_content(content_path):
# 初始化内容为空
content=''
# print(os.listdir(file_path))
files=os.listdir(content_path) # 使用os.listdir()函数列出‘content_path’中的所有文件和子文件夹,将结果存储在列表files中
for file in files: # 列表中的每一个文件或子文件夹
# 拼接完整路径
full_path=os.path.join(content_path,file) # 使用os.path.join()函数将文件夹路径和文件名拼接成完整的文件路径,存储在变量full_path中
if os.path.isfile(full_path): # 判断full_path是否是一个文件,而非目录
if full_path.endswith('.txt'): # 进一步判断文件是否以.txt结尾
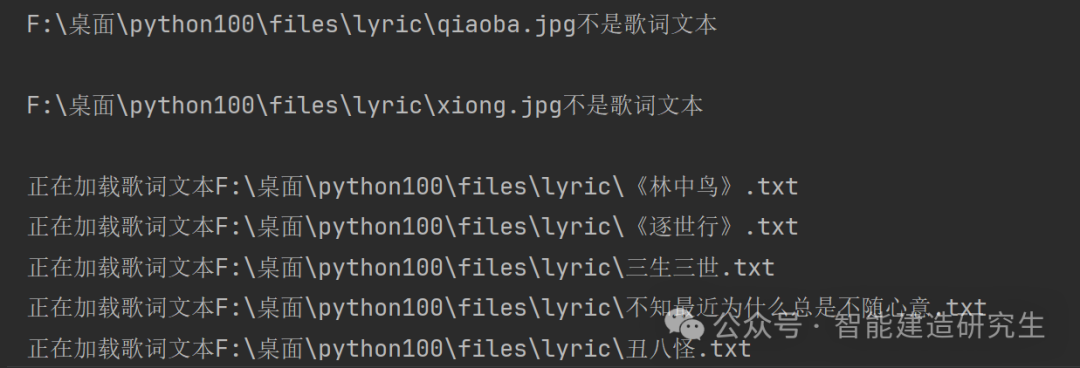
print('正在加载歌词文本{}'.format(full_path)) # 打印正在加载的文件名
content+=open(full_path,'r',encoding='utf8').read() # 读取文件内容并追加到content变量中
content += '\n' # 在每个文件内容后添加换行符以便区分不同文件的内容
else: # 对于非.txt文件
print('{}不是歌词文本\n'.format(full_path)) # 打印文件不是歌词文本的信息
print('加载歌词完毕\n')
return content # 函数返回最终拼接的内容
content=read_content(r'F:\桌面\python100\files\lyric')
print(content)
在得到所有文本组合成的字符串后,利用TextRank算法提取歌词字符串中的关键词。这是一种基于图的排序算法,用于从文本中提取关键词,根据词与词之间的共现关系来确定每个词的重要性。这种方法适用于自动提取文本关键信息,常用于文本摘要、关键词提取等自然语言处理任务。下面的代码示例使用结巴(jieba)库的 analyse 模块来提取文本中的关键词,并计算它们的重要性。
import jieba.analyse # 专门用于文本关键词提取的模块
#使用jieba的textrank提取出1000个关键词及其比重
result=jieba.analyse.textrank(content,topK=1000,withWeight=True) # 使用 textrank 方法从变量 content(应该包含所有文本内容的字符串)中提取前1000个关键词。参数 withWeight=True 表示返回关键词及其相应的权重(重要性)
print(result)
keywords = dict() # 初始化一个空字典 keywords,用于存储关键词及其权重
for i in result: # 每个元素i是一个元组,其中i[0]是关键词i[1]是该关键词的权重
keywords[i[0]] = i[1] # 将关键词和其权重添加到字典 keywords 中
# print(i[0])
print(keywords)
运行结果(部分):

结果可视化,生成一个基于文本关键词频率的词云,其中还结合了一个指定的图片形状‘熊大’和图片颜色。

from PIL import Image, ImageSequence # 导入图像处理模块
import numpy as np # np库常用于处理大型多维数组和矩阵
import matplotlib.pyplot as plt # 绘图模块
from wordcloud import WordCloud, ImageColorGenerator # 用于生成词云
# 初始化图片
image = Image.open(r'F:\桌面\python100\files\lyric\xiong.jpg')
graph = np.array(image) # 图片转换为数组
# 生成云图,指定字体路径,因为WordCloud默认不支持中文,所以需要指定中文字体
# 指定字体路径,因为WordCloud默认不支持中文,所以需要指定中文字体。background_color: 设置词云的背景颜色。max_words: 设置最多显示的词数。mask: 设置词云形状的掩模图像,此处使用之前转换的图片数组。
wc = WordCloud(font_path='C:/Windows/Fonts/STFANGSO.TTF',
background_color='white', max_words=100, mask=graph)
# 生成词云
wc.generate_from_frequencies(keywords)
# 创建一个颜色生成器,它会基于提供的图片数组来为词云生成颜色
image_color = ImageColorGenerator(graph)
# 显示图片
plt.imshow(wc)
plt.imshow(wc.recolor(color_func=image_color))
plt.axis("off") # 关闭图像坐标系
plt.show()

以上内容总结自网络,如有帮助欢迎转发,我们下次再见!















 4078
4078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









