







单链表的读取
获得链表的第 i个数据的思路
- 声明一个结点 p 指向链表第一个结点,初始化 j 从 1 开始
- 当j < i 时,就遍历链表,让p的指针向后移动,不断指向下一结点,j 累加 1
- 若到链表末尾 p 为空,则说明第 i 个元素不存在
- 否则查找成功,返回结点 p 的数据
核心思想:工作指针后移
单链表的插入和删除
插入:
s->next = p->next;
p->next = s;

单链表第 i 个数据插入结点的算法思路:
- 声明一个结点 p 指向链表第一个结点,初始化 j 从 1 开始
- 当j < i 时,就遍历链表,让p的指针向后移动,不断指向下一结点,j 累加 1
- 若到链表末尾 p 为空,则说明第 i 个元素不存在
- 否则查找成功 ,在系统中生成一个空结点 s
- 将数据元素 e 赋值给s->data
- 单链表的插入标椎语句
s->next = p->next; p->next = s; - 返回成功
单链表的删除
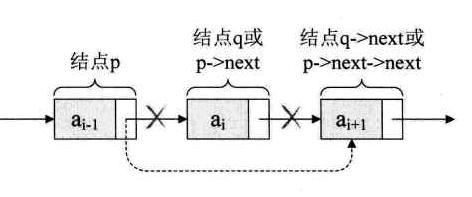
q=p->next;p->next=q->next
对于插入或删除数据越频繁的操作,单链表的效率优势就越是明显
单链表的整表创建
思路:
- 声明一结点 p 和计数器变量i
- 初始化一空链表L
- 让L的头结点的指针指向NULL,即创建一个带头结点的单链表
- 循环:
- 生成一新结点赋值给p
- 随机生成一个数字赋值给p->data
- 将p插入到头结点与前一新结点之间(
头插法)将p插在终端结点的后面(尾插法)
单链表的整表删除
- 声明一结点p和q
- 将第一个结点赋值给p
- 循环
- 将下一结点赋值给q
- 释放p
- 将q赋值给p
单链表结构与顺序存储结构优缺点

- 线性表需要频繁查找,很少插入删除,选顺序存储,否则单链表结构
- 当线性表中的元素个数变化较大或者根本不知道有多大,最好用单链表,这样就不用考虑存储空间的大小问题。















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









