







前言
机器学习基本上可以算是统计机器学习问题,也就是通过大量的数据学习到一些潜在的数据之间的特征,从而得到数据与数据之前的相关关系,进而进行目标检测、追踪、知识问答等处理。很自然的一个问题就是,既然机器学习当前主流是以统计规律得到的相关关系为主,那么我们为什么要研究因果关系呢?因为辛普森悖论 (Yule-Simpson’s Paradox)所揭示的现象,统计规律有时候不一定是正确的,所以我们需要建立起数据之间的因果联系,这也是因果推理在机器学习中存在的价值。
文章内容来源于网络,作者通过整理,加上一些自己的理解。参考列表在文末。
什么是因果推断
关于因果关系,在《 牛津哲学词典》的定义是,“当一个事件的出现导致、产生或决定了另一个事件的出现,这两个事件之间的关系就被称为因果关系。例如,外面正在下雨,不带雨具出门会被淋湿衣服。下雨和淋湿衣服之间就是因果关系, 下雨是原因,淋湿衣服是结果。[ 1 ]
因果推断是统计学和数据科学的核心问题之一,在一种现象已经发生的情况下,推出因果关系结论的过程,就是因果推断。它在生物医学、经济管理和社会科学中有都有广泛应用,可以揭示变量之间的因果关系,发现现象背后的深层原因,比如:吸烟是否致癌?社会招聘是否存在性别歧视?也可以估计定量的因果效应,分析当原因改变时结果变量的响应,以帮助人们更科学的做决策干预,比如:教育水平如何影响一个人未来的收入?比如一种药物会使得病人生存期延长多少?等等。因果推断也被认为是人工智能领域的一次范式革命,是近年来该领域的研究热点之一。未来,能否让AI像人一样思考?强人工智能是否能实现?为AI模型赋予因果关系思维似乎成了解答这些问题的必要因素和必经之路。[1]
为什么要研究因果推断
当前的机器学习主要利用数据中的统计相关性进行建模。相关性的主要来源有:因果(causation)、混淆(confounding)、样本选择偏差(selection bias),三类分别对应以下三种结构:
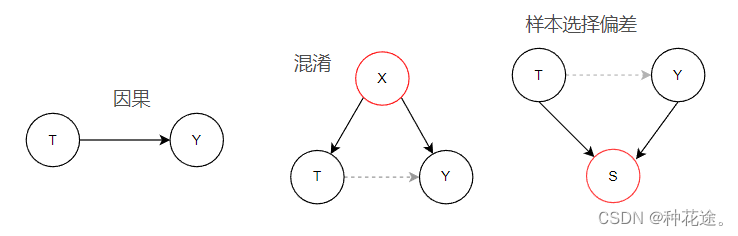
因果关系:其中T表示原因,Y表示结果,X表示混淆变量,S表示选择偏差。黑色的实线箭头表示直接的因果关系,灰色的虚线箭头表示假的相关关系。其中,只有由因果(causation)产生的相关,即因果关系(图中从左往右第一个),因果关系是一种稳定的机制,不随环境变化而变化;也只有这种稳定的结构是可解释的。例如,无论是在哪个国家,夏天时候天气变热(原因:T ),会导致冰淇淋的数量(结果:Y )上升。
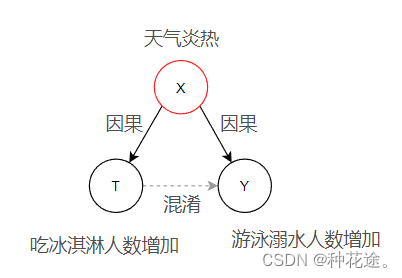
混淆(Confounding):是指存在一个变量X,这个变量构成了T和Y的共同原因,如果忽略了X的影响,那么T与Y之间就是假的相关性关系。也就是说T并非Y的直接原因。比如在夏天的时候游泳溺水的人数增加,吃冰淇淋的人也增加了,如果单从数据上看,将吃冰淇淋与溺水人数交给深度学习模型,将会得到溺水人数与吃冰淇淋的人数正相关性。但是事实是溺水人数与吃冰淇淋的人数都是受到天气气温的影响。
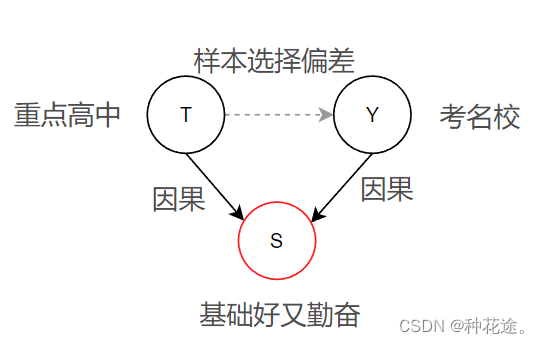
样本选择偏差(selection bias):当两个相互独立的变量T 和Y 产生了一个共同结果变量 S ,引入S 则为T 和Y 之间打开了一条通路,从而误以为T 和Y 之间存在关联关系。例如,有些基础好且勤奋的人考入重点高中,他们高考之后考入名校,那么在样本选择偏差的背景下,会产生重点高中的同学可以考名校;而现实的情况是自身的付出才是考取名校的主要因素。重点高中与考名校之间的关系次之。
大量研究表明:过于依赖统计相关的建模方式,存在着严重的理论缺陷:缺乏因果关系考虑,仅从数据中学习到的相关性可能是错误的。首先,利用相关性学习的模型,泛化能力和稳定性差,极易受到场景变化或数据中异常值的影响;再者,过度依赖数据拟合的机器学习模型就像是一个黑盒子,缺乏可解释性。
随着人工智能的应用从互联网领域向工业、医疗、金融等领域的拓展,人工智能技术的优化方向也逐渐开始从「性能驱动」转向「风险敏感」。在这样的背景下,缺乏稳定性和可解释性极大地限制了AI模型的落地。在机器学习模型中加入因果机制,似乎已经成为弥补机器学习理论缺陷,进一步发展人工智能技术的必经道路。因果关系的稳定性和可解释性,强大到可以让人们有足够的信心去做科学且安全的决策,进而提高效率、降低成本、防止损失。
工业界和学术界存在大量使用因果推断改进人工智能模型的研究和应用案例。例如,在传统的网络营销中,为了研究网页上【了解更多】按钮还是【获取方案】按钮更促进转化,我们需要进行严格的控制实验,通过A/B测试去测量各个元素的转化效果。这种方法往往受到很多现实因素的限制,且成本昂贵。然而,我们可以通过在现有数据上使用因果推断来实现该目标。
如何进行因果推断的研究
当前有关因果推断的研究主要包括两个方向:一是因果发现(Causal Discovery),二是因果效应的估计(Causal Effect Estimation)。因果发现旨在从纷繁的数据中,挖掘出变量之间的因果关系,其本质是要找到用于描述变量间因果关系的图网络结构。因果效应估计主要研究原因变量对结果变量的影响程度,其本质是建立因果模型并输出对增量的预测值。
在现实生活中,人们通过行为干预(Intervention)认知因果。以冰淇淋的销量为例,虽然我们不能直接干预天气变化,但是我们可以通过选择在干旱地区,即那些即使在夏天也无人游泳的区域,比较冬天和夏天冰淇淋的销量,得出冰淇淋的销量会随着气温上升而增加的结论;同样,我们可以选择比较干旱地区和湿润地区的冰淇淋销量,得知冰淇淋销量的增加与溺水人数并无因果关系。这样的行为干预,直接表现为控制实验(Controlled Experiment)。严格的控制实验,已经成为了研究因果关系的经典方法。然而,因果革命还带来了另一个重要成果,即允许我们在不实际实施控制实验的情况下,仅仅从观测数据中进行因果发现,并对因果效应进行估计。
在日常生活中,我们讲因果关系的时候,要么吧因果关系当做一种认知方法,要么把因果关系当作事物内部固有的一种客观联系。可是人工智能当中讲的因果关系跟日常生活当中我们所理解的这两种都有差别。
在深度神经网络当中,我们只能观察到输入和输出,而不知道中间所发生的所谓“黑盒子”的过程,这样就没办法把模型往其他应用上推广。所以,为了推广和泛化我们就要研究因果关系。人工智能界经常用一个和我们不同的词叫“捕获”,如何从数据当中捕获因果关系?大家通过用词的不同也可以体会到,它和我们日常讲的因果关系是有很大的区别。它需要在许许多多不同的训练数据当中找到某种共同的不变性,这是人工智能讲的因果关系。
参考文献
[1].https://blog.csdn.net/jiey0407/article/details/126599496?spm=1001.2014.3001.5502
[2] https://zhuanlan.zhihu.com/p/559099450
[3] https://www.zhihu.com/people/c-ome
[4] https://zhuanlan.zhihu.com/p/397796913















 1381
1381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









