









论文原文:https://www.sciencedirect.com/science/article/pii/S0950705123008171
基于模块化的动态社会网络社区跟踪方法
Michele Mazzaa, Guglielmo Colaa,∗, Maurizio Tesconia
aInstitute of Informatics and Telematics, National Research Council, Via G. Moruzzi, 1,
56124, Pisa, Italy
社区检测是揭示在线社交网络复杂动态的一项关键任务。这些网络的出现极大地增加了用户之间交互的数量和速度,为研究人员提供了前所未有的机会来探索和分析社会社区的底层结构。尽管人们对跟踪现实世界社交网络中用户群体的演变越来越感兴趣,但社区检测工作的主要焦点一直是静态网络中的社区。在本文中,我们介绍了一种在动态网络中随时间跟踪社区的新颖框架,能够为每个社区识别出一系列重要事件。我们的框架采用基于模块化的策略,不需要预定义的阈值,从而可以更准确、更稳健地跟踪动态社区。我们通过对具有嵌入式事件的合成网络进行大量实验来验证我们框架的有效性。结果表明我们的框架可以超越最先进的方法。此外,我们在 2020 年包含超过 60,000 名用户和 500 万条推文的 Twitter 网络上使用了所提出的方法,展示了其在识别现实场景中的动态社区方面的潜力。所提出的框架可以应用于不同的社交网络,并提供了一个有价值的工具,以更深入地了解动态社交网络中社区的演变。
关键词:社区检测,社区跟踪,动态社区,社会网络分析
1.介绍
随着在线社交网络、移动网络和协作网络等各种社交网络系统的快速扩散和发展,社交网络分析已成为一个重要的研究课题。在这一领域,社区检测在揭示网络内有意义的群体结构、提供对潜在社会动态的洞察方面发挥着关键作用。因此,人们通过考虑个体合作或敌对关系等因素,利用局部信息来识别隐藏社区,提出了各种社区检测算法。尽管社区检测在最近的文献中受到了极大的关注,但大多数方法都集中在静态网络上,忽视了现实世界网络固有的时间特性。传统方法依靠聚合来构建表示指定时间段内所有交互的静态网络。不可避免的是,这种表示无法捕捉受时间敏感事件影响的社区不断变化的性质。例如,在 Twitter 转发网络中,社区结构的演变可能是由新用户开始转发特定帐户或现有社区成员停止互动等因素驱动的。将这些类型的网络视为静态可能会导致无效的关联和过于简化的社区表示。用户可能在某个时间表现出与一个社区的相似性,然后转向另一个不同的社区:该用户将代表两个社区之间的唯一联系,并且省略时间属性可能会导致这些社区聚合为单个大社区。此外,时间也会在语义上影响内容。例如,随着 #MeToo 社会运动的出现,#MeToo 标签的含义发生了巨大变化。因此,此类网络中的社区检测对于更深入地了解潜在动态至关重要。
动态网络可以表示为静态网络的时间序列,称为快照。每个快照对应于在定义的时间段(如一周或一小时)内聚合的交互。在划分为快照的动态网络中检测社区的直观方法在于对每个快照采用经过充分研究的静态社区检测算法。接下来,可以通过识别随着时间的推移影响社区演变的事件来跟踪动态社区。此步骤涉及通过算法匹配在不同快照中找到的社区,通常基于社区成员的相似性。因此,需要一个任意阈值来确定在不同快照中发现的两个或多个社区是否确实是同一社区随时间演变的结果。主要缺点是最终结果可能会根据所选阈值而发生巨大变化:高相似性阈值会导致对波动成员的容忍度降低,而设置太低的相似性阈值会导致不同社区的合并。无门槛框架的稀缺对其现实世界的实施产生了负面影响,而事实证明,现实世界的实施可能有助于应对困扰在线社交平台的威胁,例如虚假信息和信息操纵。
在本文中,我们介绍了一个无阈值框架,旨在跨动态网络的多个快照跟踪社区的演变和结构。给定在所有快照中检测到的社区,我们将整个网络表示为相似性网络,其中节点是找到的静态社区,边的权重对应于它们的相似性。通过应用局部模块化优化,我们揭示了具有高度模块化和相似性的节点组。通过这种方式,我们将社区匹配任务转化为模块化优化问题,其中通过在所有节点上本地优化模块化来找到动态社区。发现的节点组体现了社区随时间的演变。最后,将每个组解开,以重建所代表的动态社区的时间演化。
值得注意的是,通过构建包含跨快照的所有静态社区的单个网络,我们的方法避免了顺序匹配,顺序匹配很难跟踪可能不存在于连续快照中的间歇性社区。通过局部模块化优化,我们派生出具有强大互连性和显着相似性的社区组,同时在它们之间保持理想程度的灵活性。重要的是,我们的无门槛设计保证了一致且值得信赖的结果,促进了我们的框架在现实场景中的应用。
为了评估我们的框架,我们使用了四个嵌入不同社区和事件的合成动态网络。结果表明,在大多数情况下,我们的方法比最先进的社区跟踪方法表现更好。在评估的第二部分中,我们展示了如何将所提出的方法应用于现实世界的联合标签 Twitter 网络,以提取有关动态社区的相关信息。
我们工作的主要贡献可概括如下:
我们提出了一种新颖的框架,利用局部模块化优化来跟踪动态网络中社区的演变和结构。跟踪动态网络中社区的能力对于充分理解现实世界网络(例如在线社交网络)的潜在社会动态至关重要。
我们的框架无需设置特定阈值,从而比现有方法具有显着优势,从而可以更准确、更稳健地跟踪动态社区。
我们的新颖框架在四个合成数据集上的评估表明,与最先进的技术相比,它具有优越的性能。
我们展示了我们的框架在由真实恶意帐户生成的 Twitter 数据集上的实际应用,说明了其提取有关动态社区的相关和暗示性信息的潜力。
接下来的部分简要概述了动态社区跟踪的现有研究。在第 3 节中,我们提供与动态网络相关的基本概念。第 4 节深入研究了我们提出的框架的全面描述。第 5 节包括我们的框架与其他方法的评估和比较,以及从现实世界网络得出的结果的呈现。最后,第 6 节对本文进行了简洁的总结和未来研究的潜在途径。
2、相关工作
近年来,大多数社交网络[18]固有的动态性质激发了研究其演化的巨大研究兴趣。在本节中,我们简要回顾了与我们的方法类似的工作,这些工作采用现有的静态社区检测算法来捕获社交网络的时间动态[19]。这种方法特别适合具有高度动态社区结构的社交网络[20]。虽然在这里我们概述了每项工作的主要贡献,但第 5 节提供了对选定研究的详细审查。
[21] 中提出了一项开创性的工作,利用静态网络快照来跟踪社区随时间的演变。作者提出了一种基于凝聚层次聚类的方法来识别和跟踪随时间变化的稳定集群。在[22]中,派系渗透方法被扩展用于监测动态网络演化中的事件。他们为连续快照对构建了联合图,然后使用自相关函数匹配获得的基于派系的社区,以找到社区两个状态之间的重叠。[23] 中提出的工作引入了一种策略,以位操作的形式实现,以识别两个连续快照中发现的社区之间的事件。 [9] 中描述了另一种跨多个快照识别和跟踪动态社区的有效方法。作者采用了基于加权二分匹配的社区匹配策略。 [20]提出的框架提供了一种基于事件的方法来检测连续快照中社区之间的转换。在同一作者的后续工作中 [10],事件定义公式已得到改进,可以跟踪整个观察时间内的社区转变,不再将其限制为连续快照。 [11]提出的群体进化发现(GED)框架不仅考虑了社区成员的相似性,还考虑了社区内节点的位置和重要性。这种方法有助于匹配社区并跟踪它们在连续快照中的演变。最近的研究 [24, 25] 提出了一种使用称为“相互转变”的新颖相似性度量来检测和建模社区演化的方法。在[19]中,提出了一种通过绘图识别社区进化的方法(ICEM)。在他们的方法中,通过在哈希图中表示社区成员来跟踪社区的演变。
我们在第 5 节中对 [9,10,20,11,24,25,19] 进行了更详细的描述和分析,其中我们比较了这些方法相对于我们的新颖框架的优点和缺点。
3.动态网络的基本概念
在深入研究我们的框架之前,让我们首先介绍与动态社交网络相关的基本概念。
3.1动态社区
动态社交网络可以表示为n 个图![]() 的序列,其中Gi表示第 i 个快照处的图,仅包含该特定时间存在的节点和边。接着,将
的序列,其中Gi表示第 i 个快照处的图,仅包含该特定时间存在的节点和边。接着,将![]() 定义为在第i个快照中发现的
定义为在第i个快照中发现的![]() 个静态社区。我们的目标是找到一组出现在一个或多个快照中的 m 个动态社区
个静态社区。我们的目标是找到一组出现在一个或多个快照中的 m 个动态社区![]() 。每个动态社区
。每个动态社区![]() 都由其组成的静态社区的时间线表示,这些社区按时间顺序排列。图 1 显示了五个动态社区的时间线示例。当动态社区(例如
都由其组成的静态社区的时间线表示,这些社区按时间顺序排列。图 1 显示了五个动态社区的时间线示例。当动态社区(例如和
或
和
)内部有静态社区互连时,我们可以独立对待这些动态社区,也可以将它们合并为一个包含所有组成其的静态社区的实体。在后一种情况下,它们变为
和
。

图 1:五个动态社区的示例,跟踪五个快照,包括增长、收缩、合并、分裂和死亡事件。
3.2.重大事件
为了跟踪社区及其随时间的结构变化,我们需要定义结构事件来描述动态社交网络的进化行为。在[22]和[23]中,提出了某些类型的事件,但它们并未涵盖社区发展的所有可能方式。本文使用与[9]中提出的关键事件模型相同的模型:成长(一个社区获得新成员)、收缩(一个社区失去一些成员)、合并(两个或多个社区合并成一个新社区)、分裂(一个社区分裂成两个或多个新社区)、诞生(一个新社区出现),死亡(社区消失)。
这些事件的示例如图 1 所示:
中的社区在第二个快照时进行了成长。
社区在第三次快照时分裂。
中的社区在第 4 个快照时与
中的社区合并。
中的社区在第 5 个快照中形成。
值得注意的是,社区可能不会在每个快照中都出现。参考图 1 中的示例,在第一个快照中观察到中的社区,然后在第三个快照中再次观察到该社区。这种“间歇性”可能是由社区成员的行为引起的,也可能取决于每个快照的持续时间粒度。
3.3 相似性
当跟踪动态社区及其组成社区的进化事件时,从不同快照中发现社区之间关系的关键是相似性。大多数现有方法都需要设置相似度阈值:只有当社区的相似度超过阈值时才被认为是相关的。在不断发展的动态社交网络中,不稳定的社区可能会经历成员转移,失去原始成员并获得新成员。因此,将相似性阈值设置得太高无法识别这些不断发展的社区,而将阈值设置得太低可能会错误地链接不相关的社区。如下一节所述,我们的框架利用不需要预定义阈值的相似性。
4. 跟踪动态社区的拟议框架

图 2:所提出方法的工作流程。从网络开始,我们将其划分为快照。然后,我们对每个快照应用静态社区检测算法。我们使用上一步中找到的社区构建社区相似性网络。随后使用局部模块化优化来识别动态社区。最后,对于每个动态社区,我们根据其原始快照对其静态社区进行重新排序,以突出显示关键事件。
图 2 提供了我们的框架的轮廓。我们通过将初始网络分段为快照来启动该过程。接下来,我们对每个快照应用静态社区检测方法。随后,我们构建社区相似性网络,其中每个静态社区表示为一个节点。在此阶段,我们忽略静态社区的起源,从而实现来自非连续快照的社区之间的匹配。然后,我们通过跨所有节点本地优化模块化来识别动态社区。最后,对于每个动态社区,我们对其组成社区进行重新排序,以重建其时间演化并识别跨快照发生的事件。
4.1.社区相似度网络
在我们的框架中,匹配步骤依赖于加权无向社区相似性网络![]() ,其中顶点集(节点)
,其中顶点集(节点)包含在每个快照中找到的静态社区,边集
由连接这些社区的链接组成,
根据连接社区的相似度值为这些边分配权重。值得注意的是,只有当两个社区源自不同的快照并共享非零相似性时,才会在两个社区之间建立边缘。
我们将相似度计算为两个社区之间的重叠系数。令![]() 和
和![]() 表示在快照i和j处找到的社区集合,其中
表示在快照i和j处找到的社区集合,其中![]() 。进一步,令
。进一步,令![]() 且
且![]() 。两个社区
。两个社区和
之间的重叠系数计算如下:
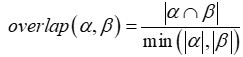 (1)
(1)
其中和
分别是
和
中的成员数量,而
是共享成员的数量。所提出的框架不依赖于任何特定的相似性度量。例如,可以采用 Jaccard 相似度,如 [9] 所示。
4.2.局部模块化优化
构建相似性网络后,我们通过在所有节点上局部优化模块化来识别相似节点组。模块化是评估社区结构的主要指标[26]。在 [−0.5, 1] 之间取值,它量化了社区内链接相比于社区间链接的密度。通过优化模块化,我们为网络中的每个节点寻求社区分配,以便使用以下定义的函数最大化模块化 M:
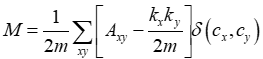 (2)
(2)
其中A是邻接矩阵,表示顶点x和y之间的边的权重,
和
分别是连接到顶点x和y的边的权重之和,
和
是顶点x和y所属的社区,
是Kronecker delta函数(如果
=
,则
返回 1,否则返回 0),m是图中所有边的权重之和。在模块化优化中,代表连接强度的边权重指导优化过程。最初,网络中的每个顶点都被分配给自己的社区。然后,每个顶点x从自己的社区中移除,并移动到每个邻居顶点y的社区。当一个顶点被分配到一个新的社区时,模块化的增加通过下面式子计算:
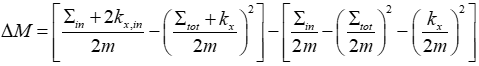
其中是x移动到的社区内所有链接的权重之和,
是x移动到的社区中所有链接到节点的权重的总和,
是x的加权度,
是x与x移动到的社区中其他节点之间的边的权重之和,m是网络中所有边的权重之和。然后,一旦计算出与x连接的所有社区的
,导致模块性增加最显着的社区就包含 x。如果模块化程度没有增加,顶点x仍保留在其初始社区中。上述过程适用于所有顶点,直到模块性不再增加。虽然我们的方法与 Louvain 算法 [16] 的初始阶段一致,但后者随后过渡到第二阶段,构建一个新网络,其中顶点代表前一阶段发现的社区。接下来,它将第一阶段应用于这个新网络,进一步优化模块化。两个阶段的完整运行称为一次通过。重复执行这样的过程,直到实现最大程度的模块化。由于我们的目标是聚合具有高度相似性的顶点,而不是最大化模块化,因此我们只采用第一步。此外,由于社区相似性网络的内在属性,使用 Louvain 的完整过程可能会产生低粒度的社区,从而可能导致某些成员彼此相关性较差的集群生成。因此,通过仅将局部模块化优化应用于社区相似性网络的顶点,我们获得了具有高模块化度的集群,并且因此由相似的社区组成。这些集群对应于动态网络中的动态社区。
4.3.随着时间的推移识别动态社区
算法 1 中给出了随着时间的推移识别和跟踪动态社区的伪代码。首先,社区相似性网络被初始化为空图(第 1 行)。对于所有快照中的每个社区,将遍历所有后续快照以查找相似度值大于 0 的社区(第 2-7 行)。当两个社区表现出正相似性时,它们会作为
中的顶点引入,并通过按该相似性值加权的边连接(第 8-9 行)。随后,初始化社区集,其中
中的每个节点都被分配给自己独立的社区中(第 10 行)。然后应用局部模块化优化,评估每个顶点以确定如果将其移动到另一个社区是否会增强网络模块化(第 11-20 行)。最终结果是社区集合的集合,其中每个集合都是已识别的动态社区。通过根据时间对每组中的社区进行重新排序,我们可以发现塑造动态社区演变的事件。

4.4.事件重建
一旦从社区相似性网络中找到了动态社区,我们就可以继续识别描述它们演变行为的事件。给定一个动态社区D,它是跨快照找到的一组静态社区,让我们更正式地定义每个关键事件,如下所示:
- 增长——如果在先前快照
中存在与
共享成员且规模较小的社区
,则社区
经历了增长。
![]() if
if
![]()
- 收缩——如果在之前的快照
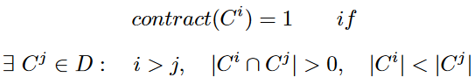
- 合并——如果存在来自先前快照
,使得
集中的每个社区与
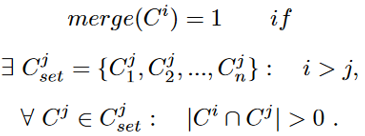
- 分割——如果社区
中的每个社区都由分割产生且与
- 诞生——如果任何先前快照
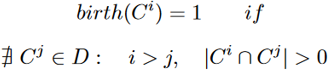
- 死亡——如果任何后续快照
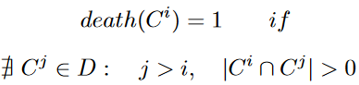
5 实验与结果
在本节中,我们详细介绍了将我们的框架与最先进的方法进行比较的实验。此外,我们还提供了一个利用现实世界数据的示例来展示我们的框架从社交互动中提取有价值的见解的能力。
5.1.综合数据集
为了评估我们的框架,我们采用了从[9]中提出的四个基准数据集派生的合成网络。这些合成网络是通过静态LFR基准[27]的动态扩展构建的,以模拟社区随时间的不同类型的进化行为。每个数据集由 15,000 个顶点组成,包含五个静态网络(快照),模拟不断发展的社区。对于每个快照,都可以获得有关静态社区的基本事实。在四个合成网络中,节点的平均度数为20,最大度数为40,以及控制社区重叠的混合参数μ=0.2。此外,在每个快照中,20%的节点都会更改其成员资格,反映了成员随着时间的推移在社区之间的自然迁移。合成网络旨在涵盖所有类型的社区进化事件:
- 出生死亡:建造 40 个新社区来取代 40 个现有社区。
- 扩展收缩:40 个随机选择的社区在每个快照中将其规模扩大或缩小 25%。
- 合并分裂:随机选择 40 个社区进行分裂,同时另一组 40 个社区进行合并,将两个社区合并为一个。
- 间歇性:在每个快照中,10% 的社区被间歇性隐藏,使它们无法被观察到。
5.2.评估指标和实验设置
为了实现公平的评估,我们使用Louvain算法[16]作为所有方法的静态社区检测方法。我们选择了与初始快照时的真实静态社区数量最匹配的层次结构级别。为了评估动态社区跟踪的性能,我们采用了一种部分受[9,28,29]启发的方法。对于每个评估的竞争对手,考虑两种情况找到动态社区:i)在每个快照中使用真实的静态社区; ii) 使用上述由 Louvain 导出的静态社区。然后,我们使用标准化互信息 (NMI) 将成员资格与两种场景中发现的动态社区进行比较。NMI 是信息论中常见的熵度量,用于量化两个簇之间的相似性。它定义为:

其中 H(X) 是与已识别社区关联的随机变量 X 的熵,H(Y) 是与基本事实关联的随机变量 Y 的熵,H(X,Y) 是联合熵。NMI 值越高(接近1),表明动态社区检测对于每个快照的静态社区信息中的噪声更具弹性。这种弹性对于确保现实世界数据集中可靠的动态社区跟踪至关重要。
对于每个数据集,我们通过五个连续实验计算NMI,每个可用快照一个。第一个 NMI 值是仅考虑第一个快照而找到的,然后对于后续实验,我们一次添加一个快照。因此,最后一个实验采用了由五个快照组成的整个“时间线”。如上所述,我们使用相同的Louvain派生的静态社区集将我们的框架与其他最先进的方法进行比较,以进行公正的比较。由于其中一些方法需要设置阈值,因此我们使用不同的阈值对其进行测试:(0.1;0.3;0.5)。为了选择阈值,我们计算了每个数据集的五个NMI值的平均值。然后,对于每种方法,我们选择产生最高平均 NMI 的阈值。
5.3.最先进的方法
在本节中,我们将描述与我们的框架进行比较的最先进方法:Greene [9]、Takaffoli [10, 20]、Brodka (GED) [11]、Tajeuna [24, 25] 和Mohammadmosaferi(ICEM)[19]。与我们的框架类似,这些方法首先使用社区检测算法分析每个快照检测到的静态社区。这些方法中的每一种都采用不同的策略和相似性度量来跟踪社区随时间的演变,即跨快照的演变。
格林等人[9]提出了一种基于阈值的启发式方法,可以在不同快照的社区之间实现多对多映射。该策略的实施过程如下。首先,在每个快照上应用查找静态社区的算法。第一个快照中的每个社区都分配给一个专用的动态社区。随后,将每个快照的社区与每个动态网络的前端社区进行比较。动态网络的前端社区是在属于该动态社区的最新快照中找到的社区。为了执行匹配,作者使用了二进制集的 Jaccard 系数 [30]:
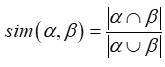 (5)
(5)
如果一对的相似度超过阈值 k,则将其视为匹配。此外,假设在快照 t 出现的社区如果缺少 d 个连续快照的匹配,则被视为已解散。这种情况允许在非连续快照中发现不断发展的社区。在我们对该框架的评估中,我们假设 d = inf 以启用与所有非连续快照的匹配。根据我们的实验,当 k = 0.1 时获得最佳结果。
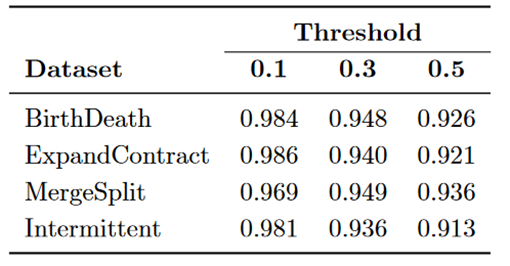
表1:Greene框架获得的NMI值。
Takaffoli等人[10, 20]使用以下相似性度量来识别连续和非连续快照中的关键事件:
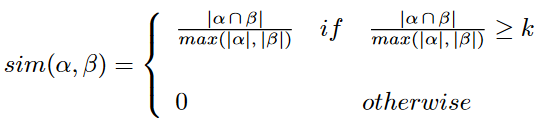 (6)
(6)
相似性阈值 k 是使用文本挖掘方法自动确定的,因为它是在具有内容信息的网络上进行评估的。鉴于我们使用合成网络,我们无法自动确定阈值。根据我们的实验,我们使用此方法使用 k = 0.3 获得了最佳结果。
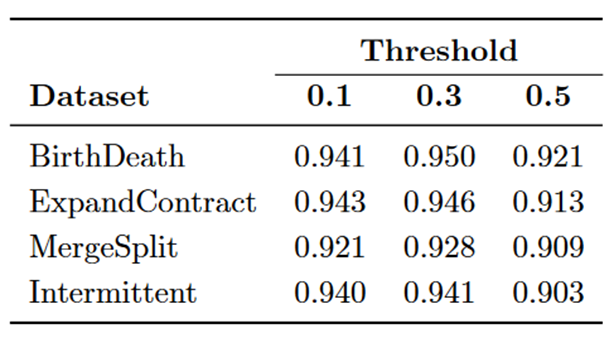
表 2:Takaffoli 框架获得的 NMI 值。
Brodka等人[11]介绍了群体进化发现(GED)框架,旨在识别重叠社区。与以前仅依赖相似性度量来跟踪社区变化的方法不同,这种方法通过结合拓扑度量来扩展度量:
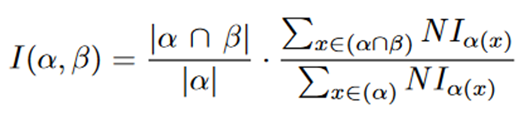 (7)
(7)
其中 N Iα(x) 表示节点 x 在社区 α 中的重要性。该值可以是任何中心性度量,例如度中心性、社会地位、介数中心性或 PageRank。尽管比较是在连续快照中进行的,但包含效应(inclusion effect)有助于跟踪重叠和非重叠社区。该方法需要两个阈值k和j。我们对 k 和 j 使用相同的值,并获得 k、j =0.1的最佳结果。
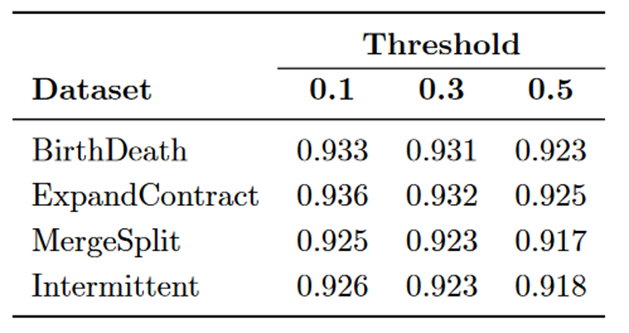
表 3:通过 GED 框架(Brodka 等人)获得的 NMI 值。
Tajeuna等人[24, 25]使用转移概率向量来表征每个社区。这些向量概括了不同社区之间随时间的共享成员资格的程度。为了评估社区之间的相似性,该方法比较它们各自的转移概率向量。给定两个社区 α 和 β 及其转移概率向量 vα和vβ,社区之间的相似度计算如下:
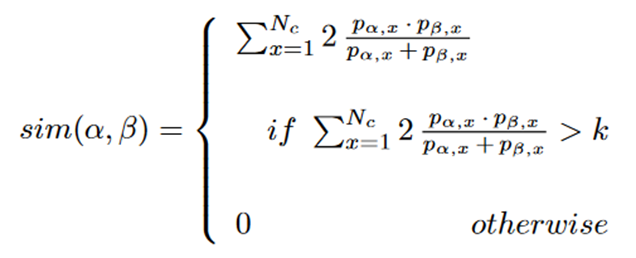 8
8
其中 pα,x 和 pβ,x 分别是转移概率向量 vα 和 vβ 的分量,Nc 是动态网络中社区的总数。阈值 k 自动确定为两条 Gamma 曲线的近似交点。这些曲线源自转移概率向量对之间的非零相似度值。
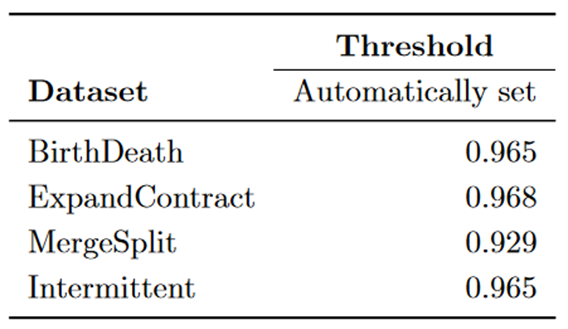
表 4:Tajeuna 框架获得的 NMI 值。
Mohammadmosaferi等人[19]介绍了一种通过绘图识别群落进化的新方法(ICEM)。在该方法中,使用哈希图来映射每个社区的成员。该映射将成员与由快照和社区索引组成的对相关联。从第二个快照开始,ICEM 为每个社区构建一个相似性列表,并根据该列表确定社区的演变。除了识别常见的关键事件之外,作者还引入了部分事件的概念。这些事件是根据两个社区之间的部分相似性来识别的:
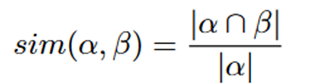 9
9
 10
10
其中 α 是第 i 个快照中的社区,β 是第 j 个快照中的社区,其中 i < j。如果 sim(α, β) > k 且 sim(β, α) > k,则社区 α 和 β 部分相似,而如果 sim(α, β) > v,则社区 α 和 β 非常相似。因此,k 和 v 是阈值分别识别部分相似和非常相似的社区。由于我们关心的不是在本次评估中区分不同类型的关键事件,因此我们设置 v = 0.5,并在 k = 0.1 时获得最佳结果。
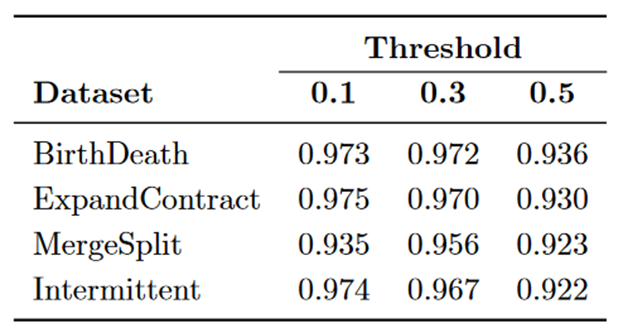
表 5:通过 ICEM 框架(Mohammadmosaferi 等人)获得的 NMI 值。
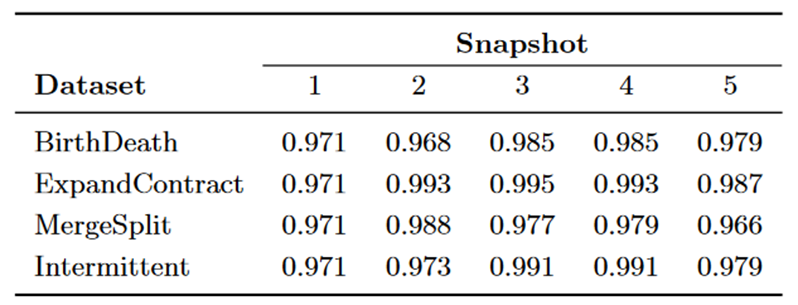
表 6:我们的框架获得的 NMI 值。
5.4.评估与比较结果
表 6 显示了我们的框架在所有数据集和快照中实现的 NMI 值。值得注意的是,它在每个实验中都获得了较高的 NMI 值(高于 0.96)。
图 3 将我们的结果与四个合成数据集上最先进的方法进行了对比。尽管 Greene 和 ICEM 偶尔会获得稍高的 NMI 值,但我们的方法在大多数情况下都能提供最佳性能。

图 3:所提出的动态社区跟踪框架和四个合成数据集上最先进的方法的 NMI。
总体而言,Greene、ICEM 和 Tajeuna 表现出了强劲的结果,而 Takaffoli,尤其是 GED 在大多数实验中都表现不佳。 GED 的表现不佳可能源于其无法连接不连续的社区。有趣的是,所有评估的方法在 MergeSplit 数据集上都达到了最差的性能。合并和分裂事件极大地扭曲了动态社区结构,使追踪变得困难。尽管如此,即使对于这个数据集,我们的方法也始终获得高于 0.96 的 NMI 分数。其中,只有 Greene 在此数据集中能够将 NMI 值保持在 0.94 以上,而 ICEM 和 Tajeuna 随着可用快照数量的增加而表现出性能下降。对于进化模式不太复杂的场景,我们的方法的功效在包含两个以上的快照时变得更加明显。在Greene中也观察到类似的趋势。随着社区相似性网络的扩展,以更高的精度精确定位相似的社区聚类变得更加可行。相反,随着快照计数的增加,一些竞争方法对社区匹配错误的脆弱性也增加。
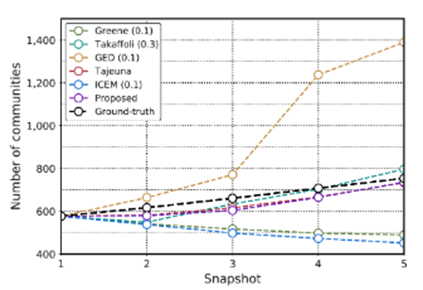
图 4:通过所提出的动态社区跟踪方法和最先进的方法,在 MergeSplit 合成动态网络上找到的动态社区数量,相对于动态社区的真实数量。
图 4 提供了关于 MergeSplit 数据集中评估方法性能的独特视角。它将每个快照中的真实动态社区数量与通过各种方法识别的社区数量进行了对比。我们的方法与 Tajeuna 和 Takaffoli 一起,密切反映了动态社区数量的基本事实。 Greene 和 ICEM 观察到的差异可能是由于采用的阈值较低,导致社区匹配和随后的合并增加。相比之下,如前所述,GED 的比较范围有限,仅限于连续的快照社区。
总之,所提出的框架通过关注局部模块化优化并忽视时间成分,在处理动态社区跟踪方面表现出色。这种独特的设计选择使框架能够适应动态社区的结构变化,始终如一地得到优秀的结果。与大多数竞争对手不同,我们的方法无需设置阈值即可运行。尽管这意味着无法通过改变阈值来改变不满意的结果,但至关重要的是要认识到社区跟踪是一个复杂的过程,没有普遍正确的结果。因此,没有阈值可以被视为一个优点,可以防止误导性的调整。虽然允许阈值调整的方法可能会产生看似令人满意的结果,但它们可能无法真正反映动态社区的真正演变。此外,通过利用更密集的社区相似性网络,我们的框架在使用两个以上快照时实现了增强的性能。
5.5.复杂性分析
我们从复杂性分析中排除了网络表示和静态社区检测的计算成本,因为我们的框架建立在从任何给定的静态社区检测方法派生的社区之上。在我们的框架中,每个静态社区都会与后续快照中的所有其他社区进行比较,产生 O(c2) 的时间复杂度,其中 c 代表静态社区的总数。局部模块化优化阶段需要 O(c)。因此,该框架的总时间和内存复杂度为 O(c2)。为了评估我们框架的可扩展性,我们采用[9]提出的合成图生成器来创建逐渐变大的动态网络。表 7 显示了数据集的属性以及相应的执行时间。我们生成了两组合成动态网络:一组有五个快照,另一组有十个快照。节点数量范围为 1,000 到 100,000,这决定了框架处理的静态社区的数量。我们使用了Python 实现所提出的框架,并使用配备 Intel Xeon 处理器 (2.2 GHz) 和 64 GB RAM 的机器的单核执行实验。对于跨五个快照、包含 100,000 个节点的动态网络,处理时间低于 35 分钟。然而,如果有十个快照,时间就会增加到大约两个半小时。执行时间很大程度上受动态网络中快照数量的影响,因为它与静态社区的数量呈正相关。由于大多数计算(例如确定两个社区之间的相似性)可以独立运行,因此有可能通过并行化来提高计算性能。通过结合 Minhashing [31] 和局部敏感哈希 (LSH) [32] 来识别 Jaccard 空间中的近似最近邻,可以实现进一步的改进。这将显着减少比较次数,以接近线性时间复杂度。

表 7:所提出的框架在具有不同特征的网络上的执行时间。
5.6.应用于现实世界的数据集
对于我们的第二次评估,我们使用[17]描述的真实数据集评估了所提出框架的行为。该数据集包含 63,358 个虚假 Twitter 帐户的活动,这些帐户在 2020 年期间产生了5,457,758 条推文。“虚假账户”一词是指包含虚假信息或冒充真实个人或组织的社交媒体账户[33]。该数据集非常适合我们的实验,因为推文不限于特定语言或主题,提供了广泛的内容,例如政治和加密货币 [34]。我们将快照粒度设置为一天里的活动,并为每个快照生成一个加权无向图。每日图表源自共同主题标签网络,在该网络中,如果两个用户在某一天都使用相同的主题标签,那么他们就会被链接起来。每条边的权重由两个用户之间共同使用的主题标签的数量给出。为了找到每个快照的静态社区,我们使用了订单统计局部优化方法(OSLOM)[35],该方法基于测量社区与没有社区结构的空模型相比的重要性[36]。OSLOM通过对相邻节点进行分组来识别具有统计显着性的社区后,会进行节点添加或删除等多次迭代调整,以增强社区的重要性。我们选择 OSLOM 是因为它在检测在线社交网络中的社区方面具有显着的功效 [37, 38]。OSLOM 的一个可能的缺点是它倾向于识别较小的静态社区 [39],这可能无法正确捕获网络的社区结构 [40]。这种担忧与实验无关,因为所确定的静态社区通过所提出的框架加入到更大的动态社区中。
我们将我们的框架应用于 OSLOM 识别的静态社区,获得了 103 个动态社区。为了调查所识别的动态社区的时间行为,我们确定了每个静态社区中每天使用的主题标签。然后,我们引入了一个与动态社区相关的新指标:平均主题标签重叠度。给定两组主题标签 h1 和 h2,发现主题标签重叠如下:
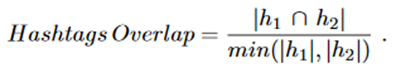 11
11
动态社区 D 的平均主题标签重叠是通过对其所有组成静态社区的主题标签重叠进行平均来计算的。一种可接受的替代指标可能是[10]中使用的指标,其中作者依赖于主题,而不是关键字或主题标签。鉴于该数据集捕获了一年多来出售的虚假帐户的活动,因此社区在不同日期使用不同的主题标签集似乎是合理的。尽管如此,一组主题标签有效地代表了特定日期的社区。
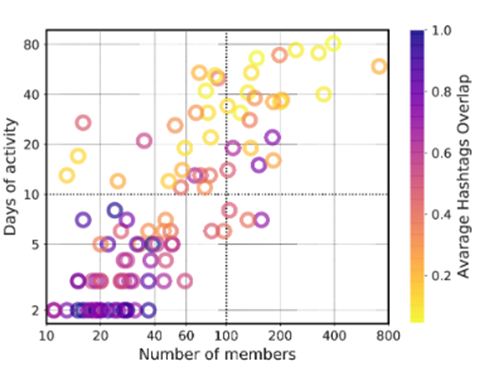
图 5:圆圈代表动态社区,以 x 轴上的成员总数与 y 轴上的活动天数绘制。每个圆圈的颜色编码其平均主题标签重叠值。
对动态社区内所有静态社区的主题标签重叠值进行平均,使我们能够深入了解已识别的动态社区的特征。图 5 绘制了已识别的动态社区,其中 x 轴为成员总数,y 轴为活动天数。此外,通过颜色,我们报告了每个动态社区的平均主题标签重叠度。该图揭示了成员数量和活动天数之间的相关性;具体来说,用户越多的社区往往活跃的天数越多,反之亦然。此外,在成员和活动天数方面具有较高值的动态社区也表现出平均主题标签重叠值较低,这意味着在一年期间,这些动态社区讨论了不同的主题。平均主题标签重叠值较低并不意味着动态社区不相关,因为该指标可能会受到其他因素(例如所采用的策略)的影响。
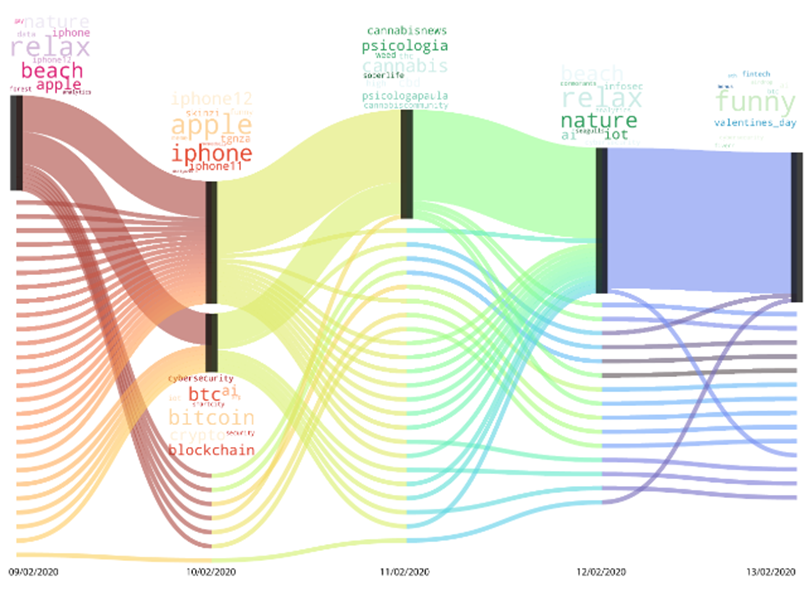
图 6:代表分析的动态群落结构的冲积图。
图 6 展示了 2020 年 2 月 9 日至 2 月 13 日动态社区的活动。为了更好地理解时间行为,对于每个组成社区,我们显示了 10 个最常用的主题标签。我们观察到,最初只有一个社区使用大多数通用主题标签,例如 #relax、#beach 和 #nature,以及一些更具体的主题标签,例如 #apple 和 #iphone。第二天,这个社区分裂成了两个社区,其中一个社区因为新用户的到来而比最初的社区更大。该社区恢复了前一天使用的有关 Apple 产品的主题标签,引入了新标签,例如 #iphone11 和 #iphone12。相反,另一个社区通过主题标签#btc、#bitcoin 和 #blockchain 关注加密货币和区块链技术。第二天,这两个社区的部分用户合并到一个以大麻相关主题为中心的新社区:#cannabis、#cbd、#cannabisnews。然而,这个社区在第二天扩大,恢复到更通用的主题标签。这种行为第二天仍在继续,我们发现#funny 以及#valentines day,因为今天是情人节前夕。
此示例强调了在线社交网络的用户每天可以讨论的主题的可变性。观察这种现象,更一般地说,研究社区随时间的行为,只有考虑其时间特性,即将其作为动态社区进行分析,才有可能实现。通过将该框架的应用扩展到类似的数据集 [41, 42],分析师可以对社交媒体平台上的各种现象获得与时间相关的新见解,例如协调的不真实行为。
6.结论
在本文中,我们介绍了一个旨在跟踪动态社区随时间演变的框架。与大多数现有框架不同,我们的社区匹配阶段没有阈值。相反,它采用应用于加权、无向社区相似性网络的模块化优化,其中时间分量被省略。我们使用带有嵌入式事件的合成图评估了我们的框架,并将我们的结果与其他最先进的框架进行了基准测试。我们的方法擅长处理动态社区的结构变化,在不同的场景中始终产生强有力的结果。没有阈值进一步确保了这些结果的一致性。此外,我们的框架与所使用的特定社区检测算法无关,从而根据网络属性(例如网络是加权还是未加权、有向还是无向)提供算法选择的灵活性。我们还在现实世界的 Twitter 网络上对所提出的框架进行了初步评估,发现了 103 个具有鲜明特征的动态社区。这一发现表明,动态社区,特别是那些源自在线社交媒体的社区,其所涵盖的主题可能表现出相当大的可变性。当应用于在线社交媒体分析时,我们的框架在识别具有一致兴趣或行为的用户群体方面显示出巨大的潜力。通过跟踪动态社区,我们的方法还可以增强影响者和关键意见领袖的时间分析,为研究应用提供有价值的见解。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









