







1. 背景介绍
近期一直在跟进大模型相关领域知识的学习,大模型的学习需要两条路并进,理论和实践。理论知识的学习,比如说对当前大模型的深度学习架构(预告:下周会带来关于transformer以及从数学角度理解transformer的分享)、不同基座大模型之间的架构对比分析(主流的就是GPT系列、LLama系列、Claude系列)、涉及的细分模块组成及功能等,但更重要的是对大模型的实践,这个实践包括了应用层,比如利用已有的大模型生态工具,如何解决实际生活、工作、业务问题。大模型生态能力,足以让一个小团队开发出一套可面向C端的工具包,而且越来越觉得小团队的创业逐步成为可能,自己也逐渐萌发创立自己团队的想法。也包括对于大模型基座模型训练、微调、RAG等技术,自己也正在按照所介绍的开源项目推进实操,后续会逐步做一些实战分享。
2. 项目简介
最近遇到三个比较好的项目,可以对比起来参考。详细介绍了如何一步步打造基座模型,通过端到端从头开始构建,能够帮助从底层技术理解大模型如何由来。
第一个项目是来自Andrej Karpathy的LLM101n课程【1】,Karpathy是前OpenAI的联合创始人。该课程的github项目内容目前已经被删除,但根据之前fork出来的内容,还是能够看到系列课程。该课程主要通过构建一个故事讲述者AI大语言模型(LLM)的处理流程来讲述相关大模型依赖的技术。你将能够与AI携手合作,创建、改进和插图小故事。从基础开始,端到端地构建一个类似于GPT的功能性Web应用程序,从头开始使用Python、C和CUDA,并且对计算机科学的前置要求极少,来实现创建、改进和插图小故事的chat工具。帮助对AI、大语言模型和深度学习有相对深入的理解。
课程大纲如下:
第 01 章 Bigram 语言模型(语言建模)
第 02 章 Micrograd(机器学习、反向传播)
第 03 章 N-gram 模型(多层感知器、matmul、gelu)
第 04 章 Attention(attention、softmax、位置编码器)
第 05 章 Transformer(transformer、residue、layernorm、GPT-2)
第 06 章 Tokenization(minBPE、字节对编码)
第 07 章 优化(初始化、优化、AdamW)
第 08 章 提速系列 I:设备(设备,CPU,GPU,...)
第 09 章 提速系列 II:精度(混合精度训练,fp16,bf16,fp8,......)
第 10 章 提速系列 III:分布式(分布式优化、DDP、ZeRO)
第 11 章 数据集(数据集、数据加载、合成数据生成)
第 12 章 推理 I:kv-cache(kv-cache)
第 13 章 推理 II:量化(quantization)
第 14 章 微调 I:SFT(监督微调 SFT、PEFT、LoRA、聊天(chat))
第 15 章 微调 II:RL(强化学习,RLHF,PPO,DPO)
第 16 章 部署(API、Web 应用程序)
第 17 章 多模态(VQVAE、扩散 transformer)
第二个项目是从头实现LLama3【2】,可以参考该git项目。 项目将会介绍端到端一步步实现Llama3的各个模块,包括每个张量和矩阵乘法。
整个项目中将会介绍涉及的步骤如下,过程很清晰:
- 分词器
- 读取模型文件
- 推断关于LLama3模型的细节
- 文本转换为tokens
- tokens转换为其嵌入表示
- 使用RMS归一化对嵌入进行归一化
- 构建Transformer的第一层
- 从头实现注意力机制
- 展开query
- 实现第一层的第一个head
- 将query权重与token嵌入相乘,以获得token的query
- 位置编码
- RoPE
- 使用复数的点积来旋转向量
- 获得每个token的旋转后的queries和keys值
- 将queries和keys矩阵相乘
- 屏蔽query-key得分
- values(几乎是注意力机制的最后一步)
- value向量
- 注意力机制
- 多头注意力机制
- 权重矩阵,最后几个步骤之一
- 对嵌入增量进行归一化,然后通过前馈神经网络运行
- 加载前馈神经网络的权重并实现它
- 第一层之后对每个token获得了新的编辑嵌入
- 有了最终的嵌入,这是模型对下一个token的最佳猜测
- 将嵌入解码为token值
- 使用最后一个token的嵌入来预测下一个值
第三个项目是《从零开始构建大型语言模型》这本书的源代码项目【3】,同样是逐步从头开始编写代码,由内而外地学习和理解大型语言模型(LLM)的工作原理。为了避免失效,可以参考该链接。引导创建自己的 LLM,通过清晰的文本、图表和示例来解释每个阶段。所以可以将这几个项目对照起来理解和实践。目标是训练和开发属于自己的虽小但功能齐全的模型的方法,反映了创建大规模基础模型(如GPT系列背后的模型)所采用的方法。此外,还包括加载更大的预训练模型权重以进行微调的代码。
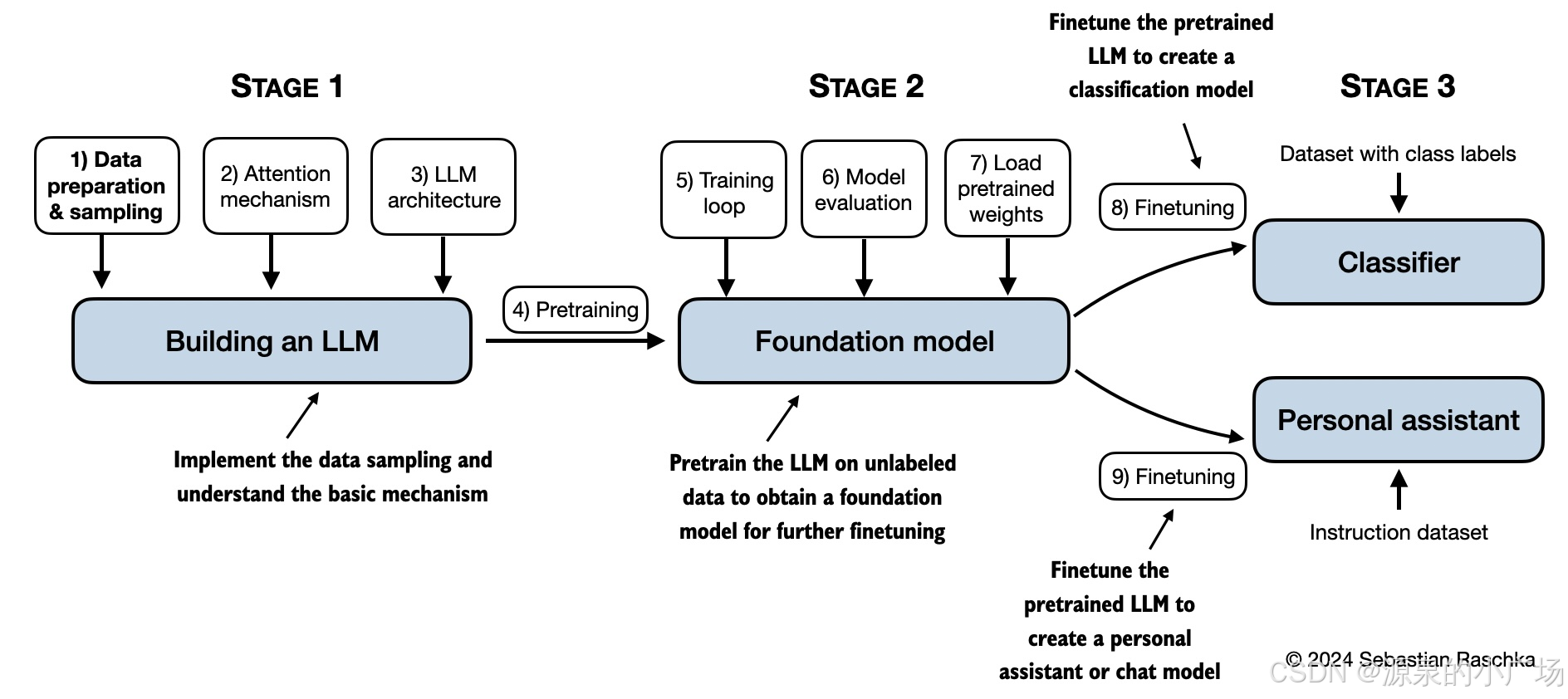 该项目包含的内容:
该项目包含的内容:
设置
Python 设置提示
安装需要使用的 Python 包和库
Docker 环境设置指南
第 2 章:
比较各种字节对编码(BPE)实现
理解嵌入层和线性层之间的差异
用简单数字理解数据加载器的直觉
第 3 章:
比较高效的多头注意力实现
理解 PyTorch 缓冲区
第 4 章:
浮点运算次数分析
第 5 章:
使用 Transformers 从 Hugging Face 模型中心加载权重的替代方法
在Gutenberg数据集上预训练 GPT
为训练循环增添特色(增加额外功能)
优化预训练的超参数
第 6 章:
对不同层进行微调以及使用更大模型的额外实验
在 5 万条 IMDb 电影评论数据集上对不同模型进行微调
第 7 章:
用于查找近似重复项和创建被动语态条目的数据集工具
使用 OpenAI API 和 Ollama 评估指令响应
生成用于指令微调的数据集
使用 Llama 3.1 70B 和 Ollama 生成偏好数据集
语言模型对齐的直接偏好优化(DPO)
20241021新增项目:Zero-Chatgpt
该开源项目的目的是想从0开始,将chatgpt的技术路线跑一遍。包括:数据收集 -> 数据清洗和去重 -> 词表训练 -> 语言模型预训练 -> 指令微调 -> 强化学习(rlhf,ppo)。最主要的是把代码和流程跑通。
预训练数据:10B token,指令微调数据:30w条,rlhf数据:10w条,模型大小:0.1B。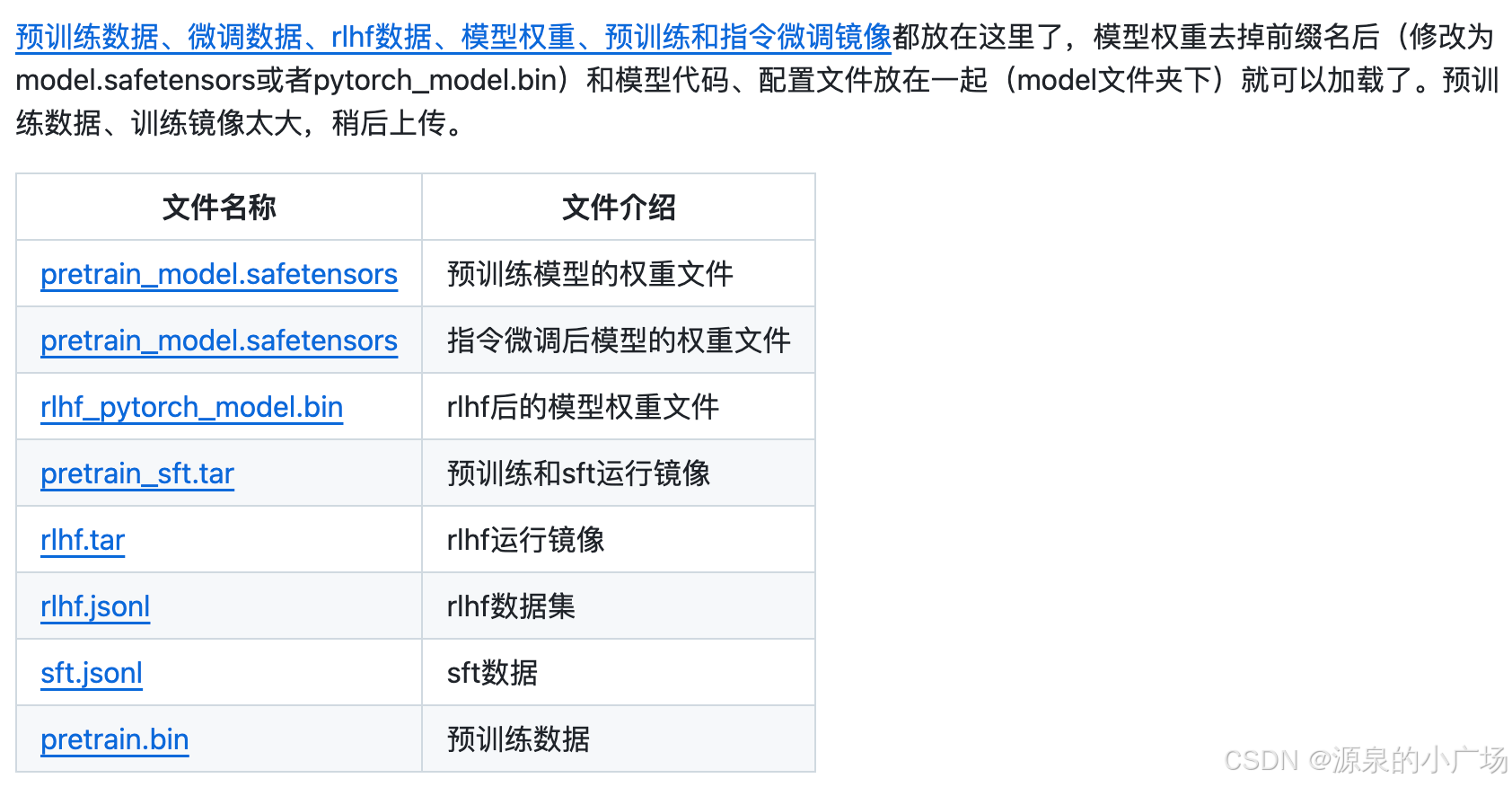
另外,作者还基于qwen实践了多模态的模型 Zero-Qwen-VL, 从0开始训练一个对中文支持更友好的图文大模型,跑通图文多模态的训练流程。项目用的是qwen-vl的图片编码器和Qwen2-0.5B-Instruct的语言模型。 作为学习的小例子还不错,给作者点赞。
3. 参考材料
【1】LLM101n
【2】LLAMA3




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











