






文章目录
前言
本文为9月3日关键点检测学习笔记——图像识别与检测,分为三个章节:
- 特征;
- 目标定位与检测;
- Pytorch 搭建 CNN。
一、特征
1、颜色特征
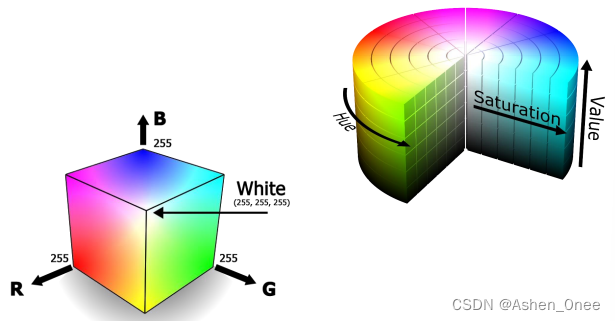
2、形状特征

3、纹理特征

二、目标定位与检测
检测 = 多目标定位。
1、目标定位 Object Localization
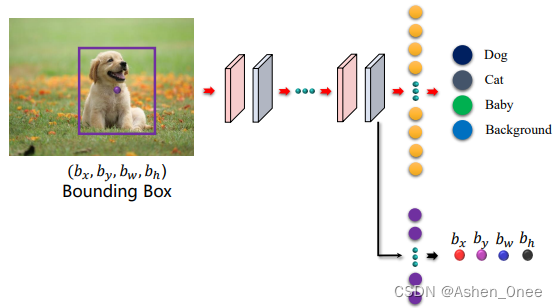

- y = [ P c , b x , b y , b w , b h , C 1 , C 2 , C 3 ] T y = [P_c, b_x, b_y, b_w, b_h, C_1, C_2, C_3]^T y=[Pc,bx,by,bw,bh,C1,C2,C3]T;
- P c P_c Pc:0 或 1,判断是背景还是 object,背景为 0;
- C C C:分类;
- Loss: L ( y ^ − y ) = { ( P c ^ − P c ) 2 + ( b x ^ − b x ) 2 + … + ( C 3 ^ − C 3 ) 2 i f P c = 1 ( P c ^ − P c ) 2 i f P c = 0 L(\hat{y} - y) = \left\{\begin{matrix} (\hat{P_c} - P_c)^2 + (\hat{b_x} - b_x)^2 + … + (\hat{C_3} - C_3)^2 \quad if\ P_c = 1 \\ (\hat{P_c} - P_c)^2 \quad if\ P_c = 0 \end{matrix}\right. L(y^−y)={(Pc^−Pc)2+(bx^−bx)2+…+(C3^−C3)2if Pc=1(Pc^−Pc)2if Pc=0。
(1)、One Class CNN
一个窗口 ⇒ 检测一个类别。

(2)、Two Classes CNN

-
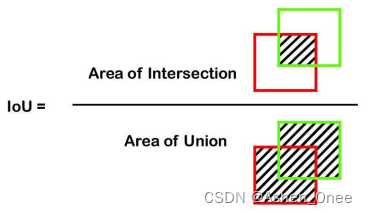
IoU:
-
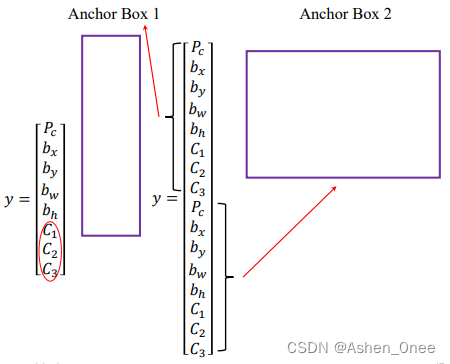
Anchor:
- Anchor Box 1: y = [ P c , b x , b y , b w , b h , C 1 , C 2 , C 3 ] T y = [P_c, b_x, b_y, b_w, b_h, C_1, C_2, C_3]^T y=[Pc,bx,by,bw,bh,C1,C2,C3]T;
- Anchor Box 2: y = [ P c , b x , b y , b w , b h , C 1 , C 2 , C 3 , P c , b x , b y , b w , b h , C 1 , C 2 , C 3 ] T y = [P_c, b_x, b_y, b_w, b_h, C_1, C_2, C_3, P_c, b_x, b_y, b_w, b_h, C_1, C_2, C_3]^T y=[Pc,bx,by,bw,bh,C1,C2,C3,Pc,bx,by,bw,bh,C1,C2,C3]T.
2、目标识别 Object detection
分类问题。
(1)、One-stage
- **Single-Shot Detector: **
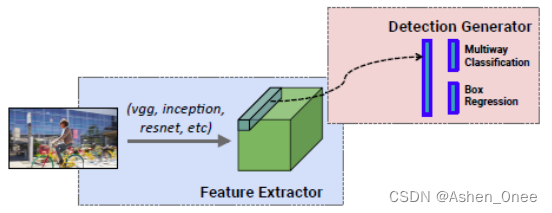
(2)、Two-stage
- Faster R-CNN:
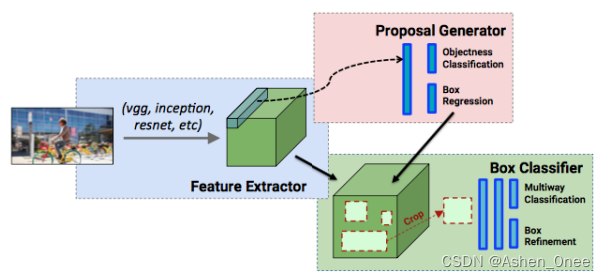
3、目标检测
分类 + 定位。
三、Pytorch 搭建 CNN
# 使用 Cifar 数据集
import numpy as np
import torch, torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets
import torchvision.transforms as transformers
print(torch.__version__)
# 1. Import & preprocess dataset
'''
- 计算数据的均值和标准差,然后 normalization;
- 需要分别计算 RGB 三个通道的均值和标准差;
- 传入元组,返回列表。
'''
ROOT = './data'
train_data = datasets.CIFAR10(root=ROOT,
train=True,
download=True)
# means = train_data.mean(axis=(0, 1, 2)) / 255
# stds = train_data.std(axis=(0, 1, 2)) / 255
#
# print(f'Calculated means: {means}')
# print(f'Calculated stds: {stds}')
train_transformers = transformers.Compose([
transformers.RandomRotation(5),
transformers.RandomHorizontalFlip(0.5),
transformers.RandomCrop(32, padding=2),
transformers.ToTensor(),
transformers.Normalize(mean=[0.4914, 0.4812, 0.4465],
std=[0.2470, 0.2435, 0.2616])
])
test_transformers = transformers.Compose([
transformers.ToTensor(),
transformers.Normalize(mean=[0.4914, 0.4812, 0.4465],
std=[0.2470, 0.2435, 0.2616])
])
train_dataset = datasets.CIFAR10(ROOT,
train=True,
download=True,
transform=train_transformers)
test_dataset = datasets.CIFAR10(ROOT,
train=False,
download=True,
transform=test_transformers)
# 2. 搭建 CNN 网络并训练
# Data loaders
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=128,
shuffle=True)
test_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=128,
shuffle=False)
# CNN
class net(nn.Module):
def __init__(self, input_dim, num_filters, kernel_size, stride, padding, num_classes):
super(net, self).__init__()
self.input_dim = input_dim
conv_output_size = int((input_dim - kernel_size + 2 * padding) / stride) + 1 # 卷积层输出尺寸
pool_output_size = int((conv_output_size - kernel_size) / stride) + 1 # 池化层输出尺寸
self.conv = nn.Conv2d(3,
num_filters,
kernel_size=kernel_size,
stride=stride,
padding=padding)
self.pool = nn.MaxPool2d(kernel_size=kernel_size,
stride=stride)
self.relu = nn.ReLU()
self.dense = nn.Linear(pool_output_size * pool_output_size * num_filters, num_classes)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
x = self.pool(x)
x = x.view(x.size(0), -1) # resize to fit into final dense layer
x = self.dense(x)
return x
# 超参数
DEVICE = torch.device('cuda')
INPUT_DIM = 32
NUM_FILTERS = 32
KERNEL_SIZE = 3
STRIDE = 1
PADDING = 1
NUM_CLASSES = 10
LEARNING_RATE = 1e-3
NUM_EPOCHS = 30
model = net(INPUT_DIM, NUM_FILTERS, KERNEL_SIZE, STRIDE, PADDING, NUM_CLASSES).to(DEVICE)
criterion = nn.CrossEntropyLoss() # 不需要调用 softmax,已包含在内
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
# 训练模型
for i in range(NUM_EPOCHS):
temp_loss = []
for (x, y) in train_loader:
x, y = x.float().to(DEVICE), y.to(DEVICE)
outputs = model(x)
loss = criterion(outputs, y)
# print(loss.type)
'''
.item():
- 以列表返回可遍历的(键, 值) 元组数组;
- 可用于 for 循环遍历;
- 把字典中每对 key 和 value 组成一个元组,并把这些元组放在列表中返回.
'''
temp_loss.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Loss at {}th epoch: {}".format(i, np.mean(temp_loss)))
# 3. Evaluation
y_pred, y_true = [], []
with torch.no_grad():
for x, y in test_loader:
x, y = x.float().to(DEVICE), y.to(DEVICE)
outputs = F.softmax(model(x)).max(1)[-1] # 预测的 label
y_true += list(y.numpy())
y_pred += list(outputs.numpy())
# 评估结果
from sklearn.metrics import accuracy_score
print(accuracy_score(y_true, y_pred))
>>> ……
>>> Loss at 29th epoch: 1.006340386312636
>>> 0.66006
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









