







一文详解,分类和回归树算法背后原理。码字不易,喜欢请点赞,谢谢!!!

一、前言
分类和回归树(Classification And Regression Trees),简称CART,是1984年提出来的既可用于分类,又可用于回归的树。CART被称为数据挖掘领域内里程碑式的算法。
上一节介绍了决策树的ID3和C4.5算法,后面说到了C4.5算法存在几点不足,主要为,生成多叉树;容易过拟合;只能用于分类;特征选择采用熵模型计算量大。而CART针对C4.5算法的这几点不足都提出了改进。本文将会一一介绍。
二、CART特征选择方法
CART算法包括分类树和回归树,其中分类树和回归树的特征选择采用的是不同的方法,这里依次介绍。
- CART分类树特征选择
在ID3中,采用信息增益来选择特征;在C4.5中,采用信息增益率来选择特征;而在CART的分类树中,则是采用基尼系数来选择特征。这是因为,信息论中的熵模型,存在大量的对数运算,而基尼系数在简化熵模型的计算的同时保留了熵模型的优点。
- 基尼系数
基尼系数代表模型的纯度,基尼系数越大,模型越不纯;基尼系数越小,模型越纯。因此在特征选择时,选择基尼系数小的来构建决策树,这和信息增益(率)是相反的。
基尼系数表达式:
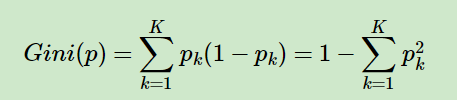
式中 K K K表示分类问题有 K K K个类别,第 k k k个类别的概率为 p k p_k pk。
如果是二分类,公式将更简单,假设第一类的概率为 p p p,则基尼系数表达式为:
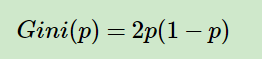
对于个给定的样本 D D D,假设有 K K K个类别, 第 k k k个类别的数量为 C k C_k
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9811
9811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









