







1、求解最优化问题的算法 通常需要经过一系列的步骤,在每个步骤都面临多种选择。对于许多最优化问题,使用动态规划算法求最优解有些杀鸡用牛刀了,可以使用更简单、更高效的算法
贪心算法(greedy algorithm)就是这样的算法,它在每一步都做出当时看起来最优的选择。也就是说,它总是做出局部最优的选择,寄希望通过这些选择导致全局最优解
2、贪心算法 并不保证得到最优解,但对很多问题 确实可以求得最优解
1、活动选择问题
一个调度竞争共享资源的 多个活动的问题,目标是 选出一个最大的互相兼容的活动集合。假定有一个 n 个活动的集合 S = {a1, a2, …, an},这些活动使用同一资源(例如一个阶梯教室),每个活动 a_i 都有一个开始时间 s_i 和 一个结束时间 f_i,其中 0 ≤ s_i < f_i < ∞。如果被选中, a_i 发生在 [si, fi) 期间。如果 a_i 和 a_j 满足 [s_i, f_i) 和 [s_j, f_j) 不重叠,则称它们是兼容的
当 s_i ≥ f_j 或 s_j ≥ f_i 时,a_i 和 a_j 是兼容的。希望选出一个最大兼容活动的子集
假定活动 已按结束时间的单调递增顺序排列:
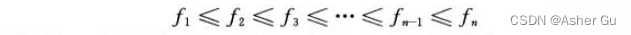
可以通过动态规划方法 将这个问题分为两个子问题,然后 将两个子问题的最优解 结合成原问题的一个最优解。在确定该将 哪些子问题用于最优解时,要考虑几种选择
贪心算法只需考虑一种选择(即贪心的选择),在做贪心选择时,子问题之一必定是空的,因此,只留下一个非空子问题。找到一种递归贪心算法 来解决活动调动问题,并将递归算法转化为迭代算法,以完成贪心方法的过程
1.1 最优子结构
A_ij = A_ij U { a_k } U A_kj,而且 S_ij 中最大兼容任务子集 A_ij 包含 I A_ij I = | A_ik | + | A_kj l + 1 个活动
用剪切一粘贴办法证明最优解
A_ij 必然包含两个子问题 S_ik 和 S_kj 的最优解
用 c[i, j] 表示集合 S_ij 的最优解的大小
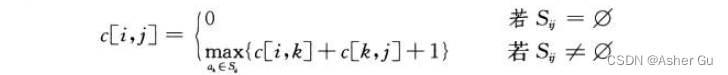
1.2 贪心选择
假如 发现所有子问题都可以选择出一个活动加入到最优解,对于活动选择问题, 只需要考虑一个选择,贪心选择
应该选择这样一个活动,选出它后 剩下的资源应能被尽量多的其他任务所用。现在考虑可选的活动, 其中必然有一个最先结束。应该选择S中最早结束的活动,因为 它剩下的资源可供它之后尽量多的活动使用
选择最早结束的活动并不是本问题唯一的贪心选择方法:也可以选择 最晚开始活动(开始要把 活动开始时间 从晚到早排序(贪心 之前的排序很重要),然后把满足条件的顺次加入进去 就行)
定理16.1 考虑任意非空子问题s,且 a_j 是 A_k 中结束时间最早的活动,则 a_m 在 S_k 的某个最大兼容子集中

虽然 可以用动态规划方法 求解活动选择问题,但并不需要这样做(此外,并未检查活动选择问题 是否具有重叠子问题性质)。相反,可以反复选择 最早结束的活动,保留与此活动兼容的活动,重复这一过程,直至无剩余活动可选
而且,因为 总是选择最早结束的活动,所以选择的活动 在结束时间上总是严格递增的,只需要 按结束时间的单调递增顺序 去处理所有活动,每个活动只考虑一次
贪心算法 通常都是这种自顶向下的设计:做出一个选择,然后求解剩下的那个子问题
1.3 递归贪心算法
输入为两个数组 s 和 f,表示活动的开始 和 结束时间,下标 k 指出要求解的子问题 S_k, 以及 问题规模 n
为了方便 算法初始化,添加一个虚拟活动 a_0,其结束时间 f_0 = 0(因为上来的活动就是 k + 1),求解原问题 即可调用RECURSIVE-ACTIVITY-SELECTOR(s, f, 0, n)
RECURSIVE-ACTIVITY-SELECTOR(s, f, k, n)
1 m = k + 1
2 while m <= n and s[m] < f[k]
3 m = m + 1
4 if m <= n
5 return {a_m} ∪ RECURSIVE-ACTIVITY-SELECTOR(s, f, m, n) // 下一代从 k = m 开始
6 else return ∅
可能因为 m>n 而终止,这意味着我们已经检查了 S_k 中所有活动,未找到与 a_k 兼容者
假定活动 已经按结束时间排好序,则递归调用 RECURSIVE-ACTIVITY-SELECTOR(s, f, 0, n) 的运行时间为 Θ(n),在整个递归调用过程中,每个活动只被 while 循环检查一次
1.4 迭代贪心算法
1、将算法转换为 迭代形式。过程 RECURSIVE-ACTIVITY-SELECTOR 几乎就是“尾递归”。它以一个对自身的递归调用 再接一次并集操作结尾。将一个尾递归过程 改为 迭代形式 通常是很直接的,实际上,某些特定语言的编译器可以自动完成这一工作
GREEDY-ACTIVITY-SELECTOR(s, f)
1. n = s.length
2. A = {a_1}
3. k = 1
4. for m = 2 to n
5. if s[m] >= f[k]
6. A = A ∪ {a_m}
7. k = m
8. return A
与递归版本类似,在输入活动已按结束时间排序的前提下,GREEDY-ACTIVITY-SELECTOR 的运行时间为 Θ(n)
2、并不是所有贪心方法都能得到最大兼容活动子集。在剩余兼容活动中 选择 持续时间最短者 不能得到最大集。在剩余兼容活动选择与其他剩余活动重叠最少者 也是同理
3、假定有一组活动,需要将它们安排到一些教室,任意活动都可以在任意教室进行。希望使用最少的教室完成所有活动。设计一个高效的贪心算法来安排哪些活动在哪个教室进行
(这个问题称为 区间图着色问题(interval-graph coloring problem))。可以构建一个区间图,其中表示活动的节点,边连接不兼容的活动。要求用最少的颜色对图的顶点进行着色,使用所有邻项顶点之间的不同颜色

这个算法的关键在于贪心策略:
总是优先使用已经空闲的讲堂来安排新的活动
只有当没有空闲讲堂时,才添加新的讲堂

不能用贪心了,O(n3) 是 i 从0到 n,j 从 i + 1 到 n,k 从 i 到 j
因为 c[i, k] + c[k, j] + V_k
希望最大化兼容活动的总价值,可以使用动态规划(Dynamic Programming, DP)来实现


def find_latest_non_conflicting(activities, n):
for j in range(n-1, -1, -1):
if activities[j][1] <= activities[n][0]:
return j
return -1
def activity_selection_with_values(activities):
# 按结束时间排序
activities.sort(key=lambda x: x[1])
# 动态规划数组
n = len(activities)
dp = [0] * (n + 1)
for i in range(1, n + 1):
# 当前活动的值
value = activities[i-1][2]
# 查找最新的与当前活动兼容的活动
j = find_latest_non_conflicting(activities, i-1)
# 递推公式
if j != -1:
dp[i] = max(dp[i-1], value + dp[j+1])
else:
dp[i] = max(dp[i-1], value)
return dp[n]
# 示例活动 (开始时间, 结束时间, 价值)
activities = [(1, 3, 5), (2, 5, 6), (4, 6, 5), (6, 7, 4), (5, 8, 11), (7, 9, 2)]
print("最大价值:", activity_selection_with_values(activities))
2、贪心算法原理
1、通过 做出一系列选择来求出问题的最优解。在每个决策点,它做出在当时看来最佳的选择。这种 启发式策略 并不保证总能找到全局最优解
2、设计贪心算法步骤
- 将最优化问题 转换为这样的形式:对其做出一次选择后,只剩下一个子问题需要求解
- 证明做出贪心选择后,原问题总是 存在最优解,即贪心选择是安全的
- 证明做出贪心选择后,剩余的子问题 满足性质:其最优解与贪心选择组合 即可得到原问题的最优解,这样就得到了最优子结构
2.1 贪心选择性质
1、可以通过做出局部最优(贪心)选择 来构建全局最优解
2、与动态规划 先求解子问题才能 进行第一次选择不同,贪心算法 在进行第一次选择之前 不求解任何子问题,一个动态规划算法是 自底向上 进行计算的,而一个贪心算法 通常是自顶向下的,进行一次又一次选择,将给定问题实例 变得更小
3、必须证明每个步骤 做出贪心选择 能生成全局最优解。这种证明 通常首先考查 某个子问题的最优解,然后用贪心选择 替换某个其他选择 来修改此解,从而得到一个相似但更小的子问题
进行贪心选择时 不得不考虑 众多选择,通常意味着 可以改进贪心选择,使其更为高效
例如,在活动选择问题中,假定 已经将活动按结束时间单调递增顺序 排好序,则对每个活动能够只处理一次。通过对输入进行预处理 或者 使用适合的数据结构(通常是优先队列),通常可以使得贪心选择更快速,从而得到更有效的算法
2.2 最优子结构
1、如果一个问题的最优解 包含其子问题的最优解,则称此问题具有 最优子结构性质。此性质是 能否应用动态规划 和 贪心算法的关键要素
活动选择问题为例,如果一个子问题 S_ij 的最优解包含活动a_k,那么必然也包含子问题 S_ik 和 S_kj 的最优解
如果知道 S_ij 的最优解应该包含 哪个活动 a_k,就可以组合 a_k 以及 S_ik 和 S_kj 的最优解中所有活动来构造 S_ij 的最优解
2、论证最优子结构:将子问题的最优解 与 贪心选择 组合在一起就能生成原问题的最优解。这种方法隐含对于子问题 使用了数学归纳法,证明了 每个步骤进行贪心选择都会生成原问题的最优解
2.3 贪心对动态规划
1、0-1背包问题:一个正在抢劫商店的小偷 发现了 n 个商品,第 i 个商品价值 v_i 美元,重 w_i 磅,v_i 和 w_i 都是整数。小偷希望 拿走价值尽货高的商品,但他的背包 最多能容纳 W 磅重的商品, W是一个整数。应该拿哪些商品
(称这个问题是 0-1 背包问题, 因为对每个商品,小偷要么把它完整拿走, 要么把它留下,不能只拿走一部分)
2、在分数背包问题 中,设定与 0-1 背包问题是一样的,不同的是:小偷可以拿走其一部分,而不是 只能做出二元 (0-1) 选择
3、两个背包问题都具有 最优子结构性质。对0-1背包问题,考虑重量不超过 W 而 价值最高的装包方案。如果 将商品 j 从此方案中删除,则剩余商品 必须是重量不超过 W - w_j 的价值最高的方案
贪心策略 可以求解分数背包问题,而不能求解 0-1 背包问题
为了求解分数背包问题,首先计算每个商品的每磅价值 v_i / w_i 。遵循贪心策略,首先尽量多地拿 每磅价值最高的商品。通过将背包按每磅价值排序,贪心算法的运行时间可为 O(nlgn)
证明分数背包问题具有贪心选择性质

拿走商品 1 的策略对 0-1 背包问题无效 是因为小偷无法装满背包,空闲空间降低了方案的有效每磅价值。在 0-1 背包问题中,当考虑是否 将一个商品装入背包时,必须比较包含 此商品的子问题的解 与 不包含它的子问题的解,然后才能做出选择。这会导致大量的重叠子问题——动态规划的标识
设计动态规划算法求解 0-1 背包问题,要求运行时间为 O(nW),n 为商品数量,W 是小偷能放进背包中的最大商品总重量
动规不用事先排序
K含义:K[考虑过的物品, 剩余空间重量]
0-1-KNAPSACK(n, W)
Initialize an (n + 1) by (W + 1) table K
for i = 1 to n
K[i, 0] = 0
for j = 1 to W
K[0, j] = 0
for i = 1 to n
for j = 1 to W
if j < i.weight
K[i, j] = K[i - 1, j]
else
K[i, j] = max(K[i - 1, j], K[i - 1, j - i.weight] + i.value)

3、赫夫曼编码
1、根据每个字符的出现频率,赫夫曼算法 构造出字符的最优二进制表示
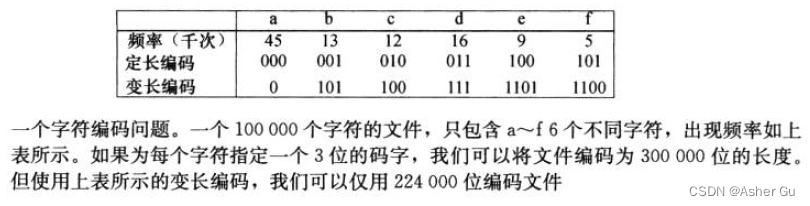
每个字符用一个唯一的一二进制串表示,称为码字。如果使用定长编码,需要用3位表示6个字符:a=000, b=001, …, f=101。这种方法需要300,000个二进制位来编码文件
2、变长编码 可以达到 比定长编码好得多的压缩率,其思想是赋予高频字符 短码字,赋予低频字符 长码字。上图显示了六个字符的一种变长编码:1位的a表示,4位的f表示。因此,这种编码表示此文件
(45⋅1+13⋅3+12⋅3+16⋅3+9⋅4+5⋅4)⋅1000=224,000位
与定长编码相比 节约了25%的空间,这是 此文件的最优字符编码
3.1 前缀码
1、只考虑所谓前缀码,即没有任何字符是其他字符的前缀。与任何字符编码相比,前缀码 都可以保证达到最优数据压缩率。因此 只关注前缀码,不会丧失一般性
前缀码的作用是 简化解码过程。由于没有码字是其他码字的前缀,编码文件的开始码字是无歧义的。可以简单地识别出 开始码字,将其转换回 原字符,然后对编码文件剩余部分 重复这种解码过程
在上节的例子中,二进制串 001011101 可以唯一地解析为 0·0·101·1101,解码为 aabec
2、解码过程 需要前缀码的一种方便的表示形式,以便 可以容易地截取开始字符。一种二叉树表示 可以满足这种需求,其叶结点为 给定的字符。字符的二进制码字 用从根结点到该字符叶结点的简单路径表示,其中 0 意味着 “转向左孩子”,1 意味着 “转向右孩子”
注意,编码树并不是二叉搜索树,因为叶节点并未有序排列,而内部结构并不包含 字符关键字
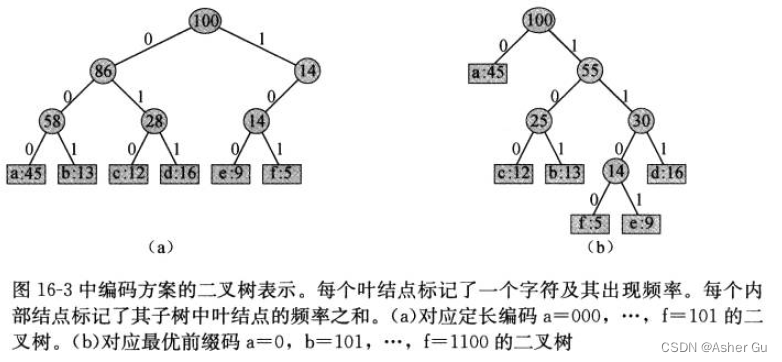
文件的最优编码方案总是对应一棵 满(full) 二叉树,即每个非叶节点都有两个孩子结点。前文给出的定长编码实例 不是最优的,因为它的二叉树表示 并非 满二叉树
若 C 为字母表 且 所有字符的出现频率 均为正数,则最优编码树对应的树结构恰有 |C| 个叶结点,每个叶结点对应字母表中一个字符,且恰有 |C|−1 个内部结点
对字母表C中的每个字符c,令属性 c.freq 表示 c 在文件中出现的频率,令 d_T(c) 表示c的叶结点在树中的深度。注意,d_T(c) 也是字母c的码字的长度。则编码该文件需要

3.2 构造赫夫曼编码
1、贪心算法来构造最优前缀码,它的正确性证明 依赖于 贪心选择性质 和 最优子结构
2、算法自底向上地构建出 对应最优编码的二叉树 T
它从 |C| 个叶结点开始,执行 |C|−1 次“合并”操作 创建出最终的二叉树。算法使用一个以 属性 freq 为关键字的最小优先队列 Q,以识别 两个最低频率的对象 将其合并。当合并两个对象时,得到的新对象的频率 等于原来两个对象频率之和
(根 搜索树不一样,没有其他对节点的顺序限制之后,只需要 让频率大的靠近根,频率小的远离根)
HUFFMAN(C)
1 n = |C|
2 Q = C
3 for i = 1 to n-1
4 allocate a new node z
5 z.left = x = EXTRACT-MIN(Q) // 把代价最小的删除并返回
6 z.right = y = EXTRACT-MIN(Q)
7 z.freq = x.freq + y.freq
8 INSERT(Q, z)
9 return EXTRACT-MIN(Q) // return the root of the tree
由于字母表 包含6个字符,初始队列大小为 n=6
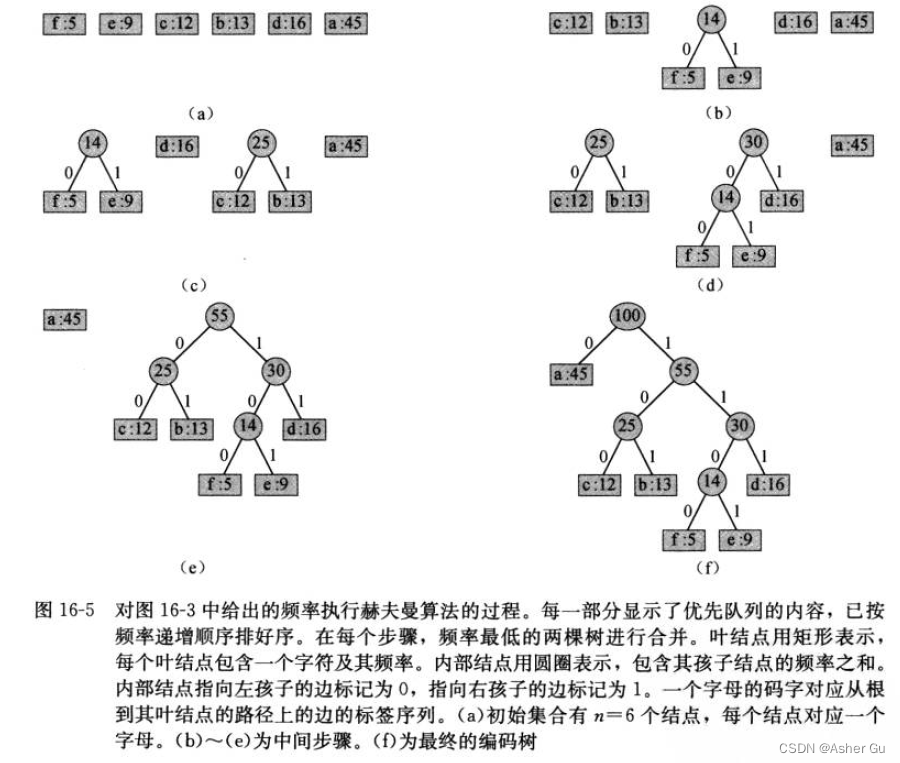
for循环 反复从队列中提取两个频率最低的结点 x 和 y,将它们合并为 一个新结点z,替代它们。z的频率为 x 和 y 的频率之和
结点z将 x 作为其左孩子,将 y 作为其右孩子(顺序是不重要的,交换左右孩子会生成一种不同的编码,但代价完全一样)。经过 n−1 次合并后,第9行返回队列中剩下的唯一结点——编码树的根结点
3、为了分析赫夫曼算法的运行时间,假定 Q 是使用最小二叉堆实现的(参见第6章)。在第2行用 BUILD-MIN-HEAP过程(参见6.3节)将 Q 初始化,花费时间为 O(n)。第3~8行的 for 循环执行 n−1 次,且每个堆操作需要 O(lgn) 的时间,所以循环对总时间的贡献为 O(nlgn)。因此,处理一个n个字符的集合,HUFFMAN 的总运行时间为 O(nlgn)
3.3 赫夫曼算法的正确性
1、确定最优前缀码的问题 具有贪心选择 和 最优子结构性质
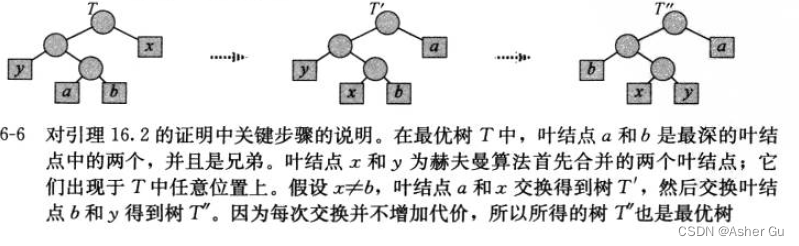
2、(1)令 C 为一个字符表,其中每个字符 c∈C 都有一个频率 c.freq。令 x 和 y 是 C 中频率最低的两个字符。那么存在 C 的一个最优前缀码,x 和 y 的码字长度相同,且 只有最后一个二进制位不同(即是 兄弟结点,在最优的基础上 每次合并仍是最优,即可合并)
证明 证明的思想是令 T 表示任意一棵最优前缀码所对应的编码树,对其进行修改,得到表示另外一个最优前缀码的编码树,使得在新树中,x 和 y 是深度最大的叶结点,且它们为兄弟结点
如果 可以构造这样一棵树,那么 x 和 y 的码字将有相同长度,且只有最后一位不同
令 a 和 b 是 T 中深度最大的兄弟叶结点, 不失一般性, 假定a.freq <= b.freq 且 x.freq<= y.freq。由于 x.freq 和 y.freq 是叶结点中最低的两个频率,而 a.freq 和 b.freq 是两个任意频率。因此, 我们有 x.freq <= a.freq 且 y.freq <= b.freq
交换 x 和 a 生成一棵新树 T’, 井在 T 中交换 b 和 y 生成一棵新树 T"
T和T’的代价差为

类似地,交换 x 和 b 也不能增加代价,所以 B(T′) − B(T’‘) 也是非负的。因此 B(T′′) < B(T),由于 T 是最优的,我们有 B(T′’) = B(T),这意味着 B(T′′) = B(T)。因此,T’’ 也是最优树,且 x 和 y 是其中深度最深的兄弟结点,引理成立
3、通过合并来构造最优树的过程,可以 从合并出现频率最低的两个字符 这样一个贪心选择开始。为什么这是一个贪心选择?可以将每一次合并操作的代价 看做 被合并的两项的频率之和
在每个步骤 可选择的所有合并操作中,HUFFMAN 选择是 代价最小的那个,下面的引理证明了构造最优前缀码的问题具有最优子结构性质
(2)令 C 为一个含有 n 个字符表,其中每个字符 c∈C 都有一个频率 c.freq。令 C’ 为 C 去棹字符 x 和 y, 加入一个新字符 z 后得到的宇母表,即 C’ = C - {x, y} ∪{z},z.freq = x.freq + y.freq。令 T’ 为字母表 C’ 的任意一个最优前缀码对应的编码树。于是 可以将 T’ 中叶结点 z 替换为一个以 x 和 y 为孩子的内部结点,得到树 T, 而 T 表示字母表C的 一个最优前缀码
证明:用树 T’ 的代价 B(T’) 来表示树 T 的代价 B(T)
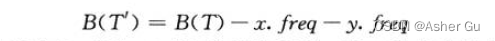
用反证法来证明引理。假定 T 对应的前缀码并不是 C 的最优前缀码,存在最优编码树 T’’ 满足 B(T′‘) < B(T)。不失一般性(由引理 16.2),T’’ 包含兄弟结点 x 和 y,令 T’’ 将 T 中 x,y 及它们的父结点替换为叶结点 z 得到的树,其中 z.freq = x.freq + y.freq(T’‘’ 对应 T’,T’’ 对应 T)
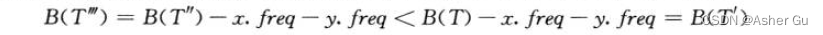
与 T’ 对应 C’ 的一个最优前缀码的假设矛盾。因此 T 必然表示字符表 C 的一个最优前缀码,即最优 T 一定包含 最优 T’'(最优子结构)
4、由(1)(2),过程 HUFFMAN 会生成一个最优前缀码

5、
















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









