






原文链接
前言
在之前实现嵌入式设备中的人脸识别中,我们使用的是Opencv的原生模型。当时就有谈到,即使是其中相对最优的LBPH模型也已经非常古老,如果小伙伴们需要更加优秀、现代化的模型,可以参考本文章。如果你对于人脸识别、交叉编译等此前完全没有了解,可以先参考前文有一个大概的认知
流程
硬件需求
树莓派的板子,32G以上的SD卡,USB读卡器,屏幕,micro-Hdmi线、摄像头(CSI/USB)
如果使用的是树莓派5且官方摄像头,需要更换FPC线,没接触过的小伙伴可能不知道如何更换,这部分可以参考这个视频Raspberry Pi 5 - Ep04 - Raspberry Pi Camera Module 3
镜像安装
烧录工具使用官方工具即可Imgar,镜像使用ubuntu或者官方镜像都可以。如果希望使用ubuntu,官网此处下载镜像,如果希望使用树莓派镜像,那么直接在官方烧录工具里面选择即可,包括ubuntu在内其他的官方镜像也可以直接在树莓派烧录工具里面找到,只是可能会较慢
将带有SD卡的读卡器插入开发计算机,打开官方烧录软件,以树莓派5使用树莓派镜像为例为例。树莓派设备选择树莓派5,操作系统为推荐的Raspberry Pi OS (64-bit),即携带桌面的树莓派操作系统,SD卡选择我们刚刚插入的读卡机,点击下一步即可进行烧录,根据不同机器等待5-30分钟完成:
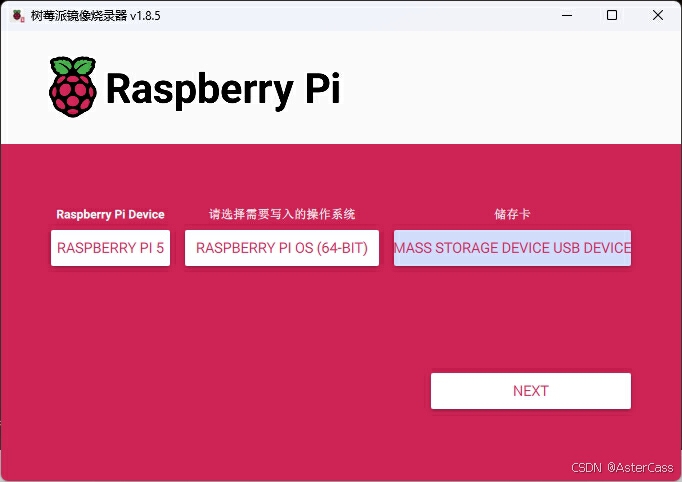
配置这里没什么东西,简单说一下。第一个选项卡,设置账户密码就不谈了,如果没有网线的小伙伴需要设置一下连接WIFI的扎账号密码,不然到时候不好进去,第二个选项卡SSH需要开启
设备启动
将读卡器插入设备,并且摄像头和屏幕等设备连接完毕,上电启动树莓派(首次启动需要按压主板启动按钮),等待片刻后即可在屏幕上观察到操作系统页面:

此时,我们可以使用SSH连接到树莓派,在开发机器打开命令行执行ssh your_username@your_pi_ip,树莓派IP地址在右上角网络连接处可以查看
注意:这里你使用包管理器安装软件的时候可能会遇到类似:files list file for package 'libip4tc2:arm64' is missing final newline的问题。此时在/var/lib/dpkg/info中删除对于的包的list文件,比如上例当中应该执行rm /var/lib/dpkg/info/libip4tc2\:arm64.list,然后执行apt install --reinstall libip4tc2:arm64,中间如果出现其他包报错,同样方案处理,直接安装即可,比如apt install libc-bin等
因为涉及后续相关软件的执行以及显示,我们这里通过说明在SSH下如何截屏来解释带显示的应用运行原理。首先,如果我们在SSH中直接执行需要显示屏的程序,一般会报could not connect to display这种错误,所以我们这里一般需要先设置需要显示的屏幕的在全局变量当中:export DISPLAY=:0(0为默认屏幕),然后再执行相应程序即可。如果你没有或者不想使用X11那么可能需要使用QT_QPA_FB_DRM环境变量直接在Linux帧缓冲区或DRM设备上渲染图形(QT限定)
以截root屏为例:我们首次登录的屏幕并不是root用户的屏幕,而是在烧写镜像时候配置的用户,所以我们需要先启动root屏幕,即先sudo su登录root账号,然后使用startx启动屏幕(可以在后台启动也可以新开一个SSH连接用于执行后续命令),最后DISPLAY=:1 scrot ./screenshot.png,即可完成截屏(没有scrot的小伙伴需要安装,apt install scrot)(由于root屏幕是我们启动的第二个屏幕,所以DISPLAY不再是默认的0)
故而小伙伴在后续应用程序启动中需要注意DISPLAY和当前用户的对应关系,防止出现类似使用root用户执行相关程序启动脚本报could not connect to display :0等问题
摄像头测试
这里可以执行export DISPLAY=:0 && libcamera-hello --camera 0 -t 0 --qt-preview测试摄像头功能是否正常,如果不正常,可以参考上方的安装视频确认摄像头正确安装
编译环境构建
交叉编译工具链部分
开发机为ubuntu直接执行sudo apt-get install gcc-aarch64-linux-gnu即可,其他操作系统参考本站之前的文章交叉编译armv7运行环境以及嵌入式opencv的编译示例
非常重要:这里需要注意gcc版本,首先先查看运行环境的gcc版本,根据不同情况你可能需要使用安装sudo apt install gcc-12 gcc-12-aarch64-linux-gnu g++-12 g++-12-aarch64-linux-gnu或其他版本到开发机器进行交叉编译
这里其实最保险的方法是使用和运行环境完全相同的版本进行交叉编译,防止出现libc.so.6: version GLIBC_2.38 not found这种类型的问题,即从运行环境导出系统库,进行编译。即首先打包运行环境库sudo tar --exclude=/proc --exclude=/sys --exclude=/dev --exclude=/tmp --exclude=/run --exclude=/media --exclude=/mnt -czvf rootfs.tar.gz /,然后将文件传入开发机器scp rootfs.tar.gz username@domin:/to/your/path/解压tar -xzvf rootfs.tar.gz -C /usr/aarch64-linux-gnu-same,在编译时添加选项--sysroot=/usr/aarch64-linux-gnu-same即可。但是这里需要先判断交叉编译工具链是否支持--sysroot选项,如果some-platform-g++-12 -v中包含--with-sysroot=/意味着该gcc/g++是在没有--sysroot支持下编译的
Qt部分
进入树莓派/usr/lib/aarch64-linux-gnu目录查看当前Qt版本,我们这里可以看到目前的版本是5.15.8:
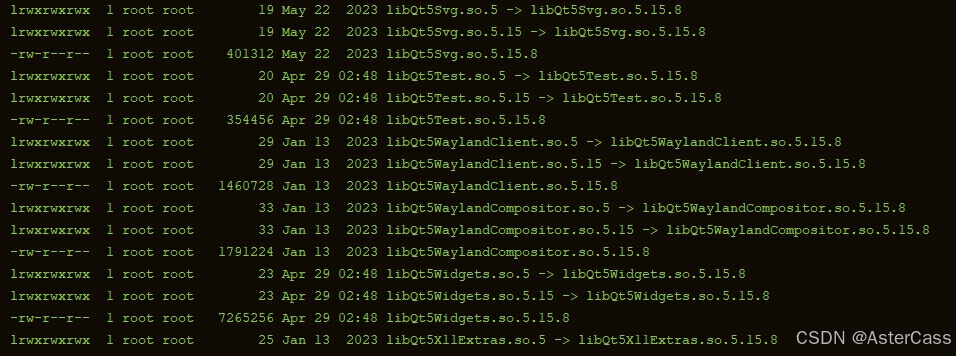
你这里当然可以不选择和他相同的版本,可以选择更高的版本,然后交叉编译之后覆盖他的动态库,但是可能会有各种兼容性的问题需要调整,最简单的方案还是选择和他相同版本的Qt进行编译。在Qt官网资源库选择你需要的源码,我们这里选择5.15.8,下载之后xz -d name.tar.xz && tar -xf name.tar进行解压
由于Qt已经将交叉编译的脚本写好,我们这里只需要指定环境即可,如果需要调整进入qtbase/mkspecs在相应的工具链目录调整,执行./configure -release -opensource -confirm-license -xplatform linux-aarch64-gnu-g++ -prefix /path/to/your/qt-app-version -nomake examples -no-opengl -slient
./configure:配置脚本,用于设置Qt的构建选项和环境,生成Makefile-release:相比debug文件更小,性能更高-opensource:开源许可-confirm-license:自动确认开源许可条款-xplatform linux-aarch64-gnu-g++: 指定平台-prefix /path/to/your/qt-app-version:安装路径-nomake examples:不编译example-no-opengl:禁用OpenGL,使用软件渲染而不是硬件渲染-slient:静默,减少输出打印-static:生成静态库。如果不想遇到各种兼容性问题,对于应用程序的大小的不是特别敏感的小伙伴,可以使用静态库,尤其是在初期调试调研功能性方案的时候
Makefile生成完成后,执行make -j 24 && make install即可在/path/to/your/qt-app-version看到arm64架构的指定版本Qt
注意:部分版本可能会编译报错,此时的处理方案有两个。要么换版本,选择更高的稳定的子版本号,要么对于报错的模块取消编译,比如5.15.2版本的qtlocation模块,使用-skip qtlocation跳过该模块的编译
至此开发机器编译环境就构建完成了
开发机器QtCreator配置
一般情况,开发机器不止有纯编译环境,可能还需要使用QtCreator进行可视化的交互开发,更甚我们需要应用程序可以在开发机器上直接跑,使用各种预处理宏来区别实际的实现,但是使用统一的UI来加快开发效率
QtCreator下载安装
在官网下载页面下载对应版本的QtCreator,下载完成后执行、注册,进入配置页面进行组件选择,这里觉得自己用不到就不用选,QtCreator有个很方便的子模块Qt Maintenance Tool可以很方便地在后续添加删除组件。注意,我们这里需要先点击Archive再点击筛选才能看到全部版本,否则只能看到Qt6的部分版本:

构建套件配置
进入编辑(Edit)->首选项(Preferences)页面,在构建套件(Kit)选项卡中添加(Add)构建套件。其他配置和默认安装的开发机的配置差不多,主要修改编译器和Qt版本即可,分别对应开发机器上的交叉编译环境的gcc和g++以及前文交叉编译安装完成的qmake,如下:
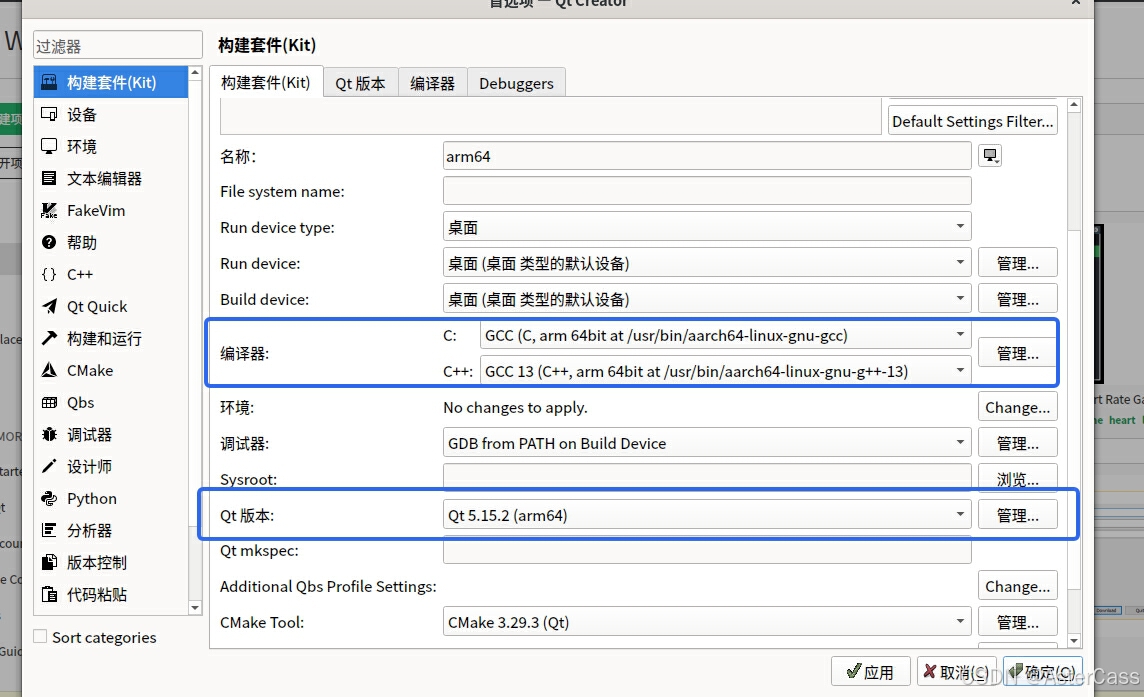
将该构建套件添加到指定项目当中,即可使用交互界面交叉编译树莓派的应用程序
树莓派动态库补充
如果上方使用静态库进行Qt相关内容的编译,那么在Qt部分就不需要对于运行环境的静态库进行补充了
当我们将应用程序打包传入树莓派中后,可能遇到提示动态库缺失的情况,比如multimedia库,此时我们需要将开发机器的动态库拷贝到树莓派中,比如在开发机的/path/to/your/qt-app-version的/lib中执行tar -czvf media.tar.gz *media*,将文件拷贝到树莓派/usr/lib/aarch64-linux-gnu中,执行tar -xzf media.tar.gz
基本测试
此时我们使用QtCreator使用创建项目,创建Qt Widgets Application的模板项目,编译后生成可执行文件,传入树莓派执行(如果使用的SSH参考上文显示在默认屏幕的方式),即可得到:
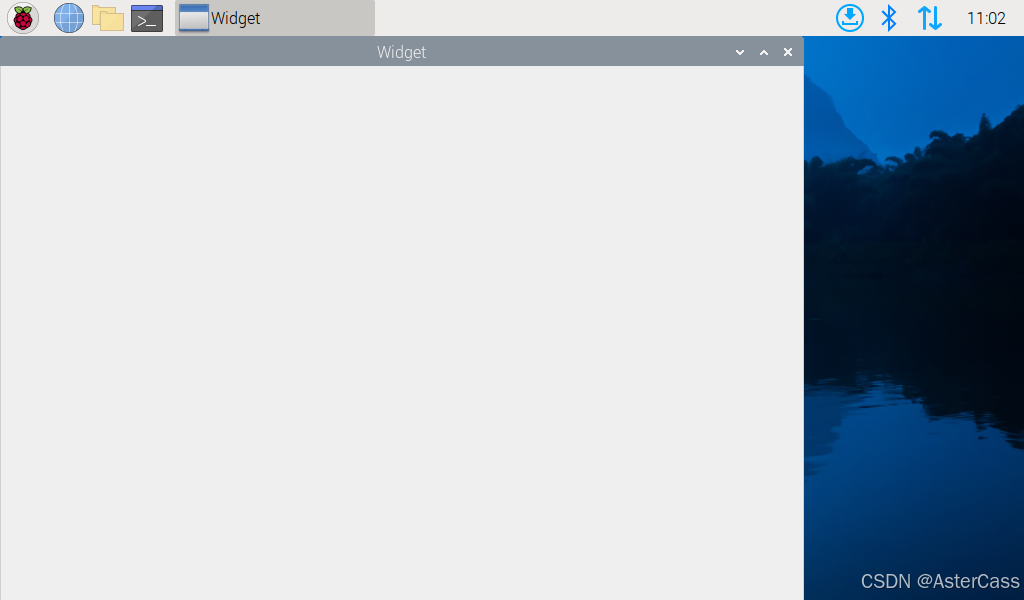
Opencv交叉编译
这个部分仍然可查看本站前文交叉编译armv7运行环境以及嵌入式opencv的编译示例,注意架构区别,我们这里运行环境是aarch64-gnu。这里一般情况我们会编译两次Opencv,分别是树莓派架构和开发机器架构的,尤其是你开发机器有摄像头的情况下。Linux和Mac下相对简单,参考Installation in Linux或者Installation in MacOS即可。Windows下稍微麻烦点,所以你可以参考本站前文Windows下使用Qt引用opencv库进行二维码识别的Opencv编译部分,直接下载其他人已经编译好的版本
Opencv测试
同样参考本站前文交叉编译armv7运行环境以及嵌入式opencv的编译示例的测试部分,成功模糊图片即Opencv交叉编译成功
人脸识别算法
这里我们选择InspireFace为例,当然你也可以选择其他的人脸识别模型算法,比如dlib中的face_detector模块等,目前开源的人脸模型算法还是挺多的,而且实际差别不大,小伙伴们自行选用即可
人脸识别算法编译
虽然在Release中已经有一些编译好的动态库,但是GLIBC等基本库未必是和你的运行环境一模一样。所以如果你直接使用他的动态库在编译链接时候出现libInspireFace.so: undefined reference to std::basic_filebuf<char, std::char_traits<char> >::basic_filebuf()@GLIBCXX_3.4类似这种问题,那么就意味着我们需要对于InspireFace进行交叉编译了
首先需要拉取代码和第三方库:
git clone https://github.com/HyperInspire/InspireFace.git
cd InspireFace
git clone https://github.com/HyperInspire/3rdparty.git
cd 3rdparty
git pull
git submodule update --init --recursive
第三方模块非常大,大概有快2G,所以可能拉取过程会比较长,小伙伴们需要稍微等待一下。拉取完成后我们需要设置交叉编译的环境,以64位树莓派为例:
export ARM_CROSS_COMPILE_TOOLCHAIN=/usr
bash command/build_cross_aarch64.sh
如果你不知道在自己的环境下ARM_CROSS_COMPILE_TOOLCHAIN应该设置成什么,参考脚本文件,或者随便设置一个看报错信息。对于树莓派64位,可以在开发环境根目录下或者usr目录下执行find ./ -name aarch64-linux-gnu-gcc | grep bin/aarch64-linux-gnu-gc进行检索。对于开发环境为Ubuntu而言,如果你是直接从包管理器安装的交叉编译工具,那么直接设置/usr即可
编译完成后我们可以在build下对应环境找到库文件和头文件,即可根据他的头文件和官方示例进行对应功能的开发
人脸算法模型
除了库文件和头文件,我们进行人脸识别还需要算法对应的模型,从谷歌云盘下载,进入test_res/pack即可看到,可以根据需求自行选用不同模型,Pikachu,Megatron,Gundam-RV1109。如果云盘链接过期或者错误,请自行到官方文档查看最新资源地址
最终代码
算法初始化
void init()
{
qDebug() << "[op:FaceRecognition] Init start";
qRegisterMetaType<UserFaceData>("userFaceData");
// Init base
HResult ret;
// Load modle
ret = HFLaunchInspireFace("/data/face/model/Pikachu");
//ret = HFLaunchInspireFace("/data/face/model/Megatron");
//ret = HFLaunchInspireFace("/data/face/model/Gundam_RV1109");
if (ret != HSUCCEED) {
qDebug() << "[op:FaceRecognition] Load Resource error: " << ret;
return;
}
// Configuration for the feature database
HFFeatureHubConfiguration featureHubConfiguration;
featureHubConfiguration.featureBlockNum = 20; // Number of feature blocks
featureHubConfiguration.enablePersistence = 0; // Persistence not enabled, use in-memory database
featureHubConfiguration.dbPath = ""; // Database path (not used here)
featureHubConfiguration.searchMode = HF_SEARCH_MODE_EAGER; // Search mode configuration
featureHubConfiguration.searchThreshold = 0.48f; // Threshold for search operations
// Enable the global feature database ret = HFFeatureHubDataEnable(featureHubConfiguration);
if (ret != HSUCCEED) {
qDebug() << "[op:FaceRecognition] An exception occurred while starting FeatureHub: " << ret;
return;
}
// Create a session for face recognition
HOption option = HF_ENABLE_FACE_RECOGNITION;
ret = HFCreateInspireFaceSessionOptional(
option, HF_DETECT_MODE_ALWAYS_DETECT, 1,
-1, -1, &m_session);
if (ret != HSUCCEED) {
qDebug() << "[op:FaceRecognition] Create session error: " << ret;
}
qDebug() << "[op:FaceRecognition] Session build success";
}
获取特征值
方法中将特征值指针传入,获取特征值
long getImgFeature(Mat image, HFFaceFeature *feat)
{
qDebug() << "[op:getImgFeature] Start ";
// Init base
HResult ret;
HFImageStream stream;
// Prepare image data for processing
HFImageData imageData = {0};
imageData.data = image.data; // Pointer to the image data
imageData.format = HF_STREAM_BGR; // Image format (BGR in this case)
imageData.height = image.rows; // Image height
imageData.width = image.cols; // Image width
imageData.rotation = HF_CAMERA_ROTATION_0; // Image rotation
ret = HFCreateImageStream(&imageData, &stream); // Create an image stream for processing
if (ret != HSUCCEED) {
qDebug() << "[op:getImgFeature] Create stream error: " << ret;
return ret;
}
// Execute face tracking on the image
HFMultipleFaceData multipleFaceData = {0};
ret = HFExecuteFaceTrack(m_session, stream, &multipleFaceData); // Track faces in the image
if (ret != HSUCCEED) {
qDebug() << "[op:getImgFeature] Run face track error: " << ret;
return ret;
}
// Check if any faces were detected
if (multipleFaceData.detectedNum == 0) {
qDebug() << "[op:getImgFeature] No face was detected: " << ret;
return ret;
}
// Extract facial features from the first detected face
ret = HFFaceFeatureExtract(m_session, stream, multipleFaceData.tokens[0], feat);
if (ret != HSUCCEED) {
qDebug() << "[op:getImgFeature] Extract feature error: " << ret;
return ret;
}
qDebug() << "[op:FaceRecognition] Insert feature to FeatureHub";
// Release the image stream
ret = HFReleaseImageStream(stream);
if (ret != HSUCCEED) {
qDebug() << "[op:FaceRecognition] Release stream failed: " << ret;
}
return ret;
}
这里如果你使用的是路径读入,比如QString,那么可以使用:
// Load the image from the specified file path
auto image = cv::imread(path.toStdString());
if (image.empty()) {
qDebug() << "[op:getImgFeature] The image is empty: " << path << ret;
return ret;
}
进行转换
添加人脸
void addFace()
{
// load data
QJsonArray sqlRet = LocalDatabase::getInstance()->exec(QString("select * from user_data;"));
for (auto obj : sqlRet)
{
QJsonObject colJsonValue = obj.toObject();
int faceId = colJsonValue["face_id"].toInt();
QString userId = colJsonValue["user_id"].toString();
QString extra = colJsonValue["extra"].toString();
QJsonDocument extraDoc = QJsonDocument::fromJson(extra.toUtf8());
QJsonObject userColObj = extraDoc.object();
QString path = userColObj["faceAddress"].toString();
if (0 == faceId || path.isEmpty())
{
qDebug() << "[op:FaceRecognition] No Face data " << faceId << userId << path;
continue;
}
//For get current img feature
HFFaceFeature feature = {0};
ret = getImgFeature(path, &feature);
// Assign a name to the detected face and insert it into the feature hub
HFFaceFeatureIdentity identity = {0};
identity.feature = &feature; // Assign the extracted feature
identity.customId = faceId; // Custom identifier for the face
identity.tag = ""; // Tag the feature with the name
ret = HFFeatureHubInsertFeature(identity); // Insert the feature into the hub
if (ret != HSUCCEED) {
qDebug() << "[op:FaceRecognition] Feature insertion into FeatureHub failed: " << ret;
continue;
}
//...
qDebug() << "[op:FaceRecognition] Member " << userId << faceId << path << isDisable
<< voiceTemplate << startTime << endTime << " add successful";
}
//Insert face count
HInt32 count;
HFFeatureHubGetFaceCount(&count);
qDebug() << "[op:FaceRecognition] Inserted data: " << count;
qDebug() << "[op:FaceRecognition] Init function successful";
}
人脸识别
UserFaceData faceCheck(Mat image)
{
HResult ret;
UserFaceData data = {0};
// Get feature
HFFaceFeature feature = {0};
ret = getImgFeature(image, &feature);
if (ret != HSUCCEED) {
return data;
} else {
//...
}
//...
// Initialize the structure to store the results of the face search
HFFaceFeatureIdentity searched = {0};
HFloat confidence;
// Variable to store the confidence level of the search result
// Search the feature hub for a matching face feature
ret = HFFeatureHubFaceSearch(feature, &confidence, &searched);
if (ret != HSUCCEED) {
qDebug() << "[op:FaceRecognition] Search face feature error: " << ret;
return data;
}
if (searched.customId == -1) {
qDebug() << "[op:FaceRecognition] No similar faces were found";
return data;
}
qDebug() << "[op:FaceRecognition] Found similar face: id= "
<< searched.customId << ", confidence=" << confidence;
//TODO build data
return data;
}
调用
这里有关于,摄像头的画面的捕捉以及Qt窗口的展示,小伙伴们根据自己的需求和硬件设备进行处理,这里就不放具体代码了。如果你使用的USB摄像头那么直接使用Qt原生组件即可,可以简单参考QT Camera Demo相关内容。如果你使用的是CSI摄像头,那么最好使用cv::VideoCapture、cv::CAP_ANY相关对于摄像头进行VideoCapture::open()、VideoCapture::read(cv::Mat)相关操作
int main(int argc, char *argv[]) {
startCamera();
initAndInsertFaceModel();
openWindow();
}

















 8765
8765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









