






# 商业转载请联系作者获得授权,非商业转载请注明出处。
# For commercial use, please contact the author for authorization. For non-commercial use, please indicate the source.
# 协议(License):署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
# 作者(Author):Astrophel
# 链接(URL):基于深度神经网络的遥感船只检测方法 – Astrophel
# 来源(Source):Astrophel
原文地址:基于深度神经网络的遥感船只检测方法![]() https://www.astrophel.top/?p=630
https://www.astrophel.top/?p=630
随着技术的不断发展和进步,遥感图像已经成为了获取地球表面信息的重要手段之一。遥感图像可以提供地表覆盖类型、地表温度、植被指数等多种信息,这些信息对于自然资源管理、城市规划、环境保护等领域都具有重要意义。然而,由于遥感图像数据的特殊性,传统的遥感图像处理和分析方法存在一定的局限性。因此,基于卷积神经网络的遥感图像分类研究应运而生。
(人话:为了完成人工智能课的大作业,写了这个程序,代码比较简陋,仅供参考)
使用工具
本项目使用Anaconda搭建虚拟环境,所用python版本为3.10。机器学习框架选择PyTorch cuda 11.7版,训练显卡为NVIDIA RTX 2060,显存为6G。展示环节使用了第三方库gradio。
效果展示
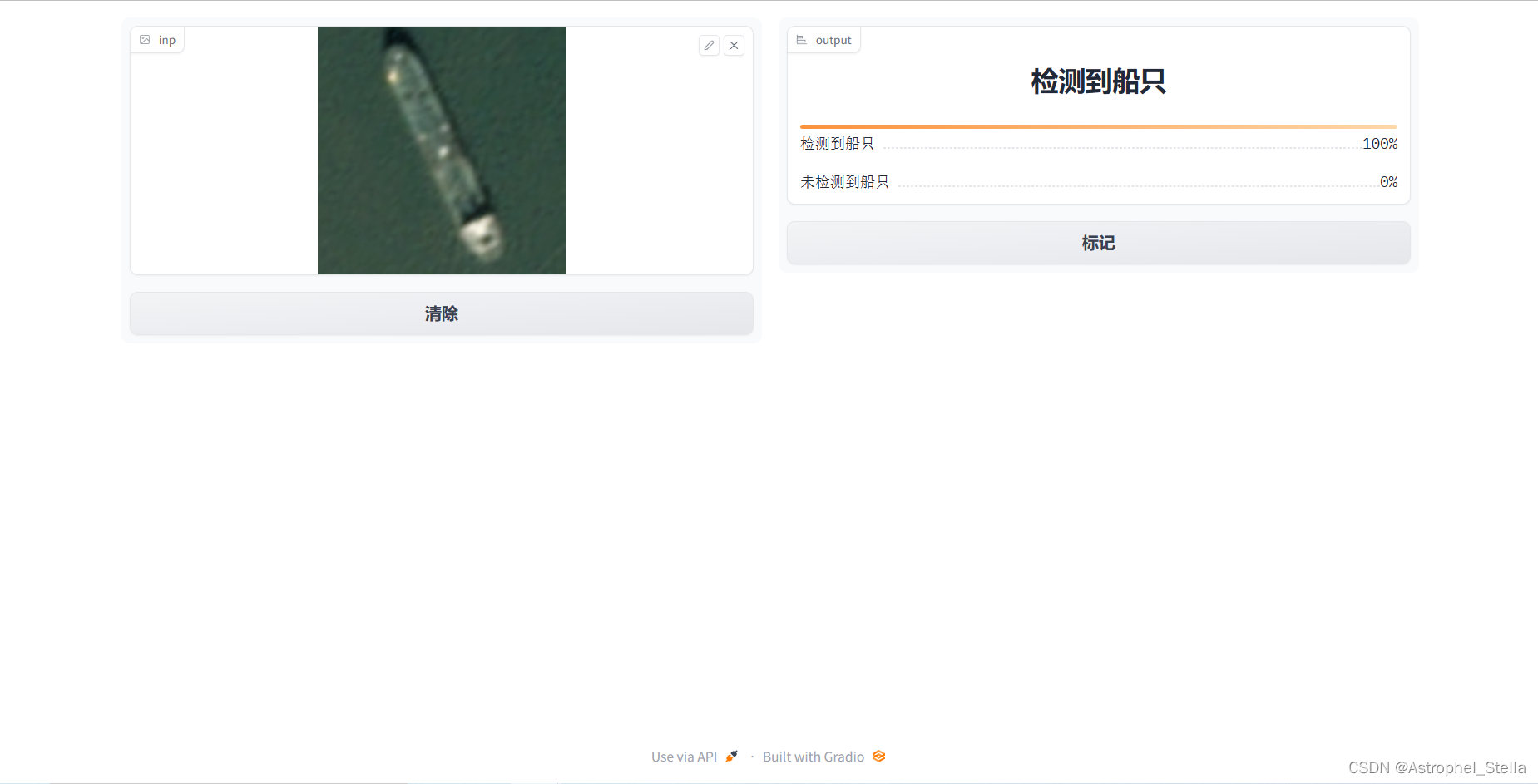
详细内容及代码
项目地址:GitHub 简单的使用AlexNet网络检测光学遥感影像中的船舶![]() https://github.com/Astrophel02/ShipDetect
https://github.com/Astrophel02/ShipDetect
使用了https://opensar.sjtu.edu.cn 的opensarship-1 数据集,对数据集进行预处理使之大小适合网络。处理后的数据集请前往:基于深度神经网络的遥感船只检测方法 – Astrophel或GitHub查看。
模型选用简单的AlexNet,最终识别准确率可以达到97%以上。
代码中,CNN_1是训练过程,CNN_2是展示过程,针对实验用数据集的预训练模型在这里:OneDrive,该模型可以直接在CNN_2.py中加载。全部代码如下:
CNN_1:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
#设置超参数
BATCH_SIZE=32
EPOCHS=20
DEVICE = torch.device("cuda") #选择计算硬件
transforms = transforms.Compose([
#transforms.RandomCrop(32,padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
train_path = "D:\\ship\\train" #修改数据集位置
train_dataset = datasets.ImageFolder(train_path, transform=transforms)
test_path = "D:\\ship\\test" #修改数据集位置
test_dataset = datasets.ImageFolder(test_path, transform=transforms)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=6)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=6)
#定义网络
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 2),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
model=AlexNet().to(DEVICE)
weights = [1.0,3]
class_weights = torch.FloatTensor(weights).to(DEVICE)
criterion = nn.CrossEntropyLoss(weight=class_weights)
optimizer = torch.optim.Adam(model.parameters(), lr=0.00005)
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output=model(data)
loss=criterion(output,target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 30 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model,device,test_loader):
model.eval()
test_loss=0
correct=0
with torch.no_grad():
for data,target in test_loader:
data,target=data.to(device),target.to(device)
output=model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(EPOCHS):
#test(model, DEVICE, test_loader,loss)
train(model,DEVICE,train_loader,optimizer,epoch)
test(model,DEVICE,test_loader)
#保存模型
MODEL_PATH = "./Model.pth"
torch.save(model,MODEL_PATH)CNN_2:
# 商业转载请联系作者获得授权,非商业转载请注明出处。
# For commercial use, please contact the author for authorization. For non-commercial use, please indicate the source.
# 协议(License):署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
# 作者(Author):Astrophel
# 链接(URL):https://www.astrophel.top/?p=630
# 来源(Source):Astrophel
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import gradio
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 2),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
#加载模型
device=torch.device("cuda")
model = torch.load("./Model.pth")
model.to(device)
#model.eval()
device=torch.device('cuda')
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
test_path = "D:\\ship\\test"
test_dataset = datasets.ImageFolder(test_path, transform=transform)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=32, shuffle=False, num_workers=6)
def test(model,device,test_loader):
model.eval()
test_loss=0
correct=0
with torch.no_grad():
for data,target in test_loader:
data,target=data.to(device),target.to(device)
output=model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
test(model, device, test_loader)
#可视化
labels=["未检测到船只","检测到船只"]
def predict(inp):
#model.eval()
img = transforms.ToTensor()(inp)
img = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])(img)
img = img.unsqueeze(0)
img = img.to(device)
with torch.no_grad():
prediction = torch.nn.functional.softmax(model(img)[0], dim=0)
confidences = {labels[i]: float(prediction[i]) for i in range(2)}
return confidences
def test(inp):
img = transforms.ToTensor()(inp)
img = img.unsqueeze(0)
return img.shape
inp = gradio.Image()
io = gradio.Interface(fn=predict,inputs=inp,outputs="label",live=True)
io.launch()遇到的坑
1)模型选择不恰当。开始选择了VGG-16作为模型,结果无法拟合;
2)结果展示过程忘记对输入图片进行预处理,导致结果不准确;
3)数据集正反样本数量不均匀,导致模型更倾向于预测无船只,解决方法是为损失函数增加权重。















 7034
7034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









