







如下:定义一个 1对多 关系:
# 国家表
class Country(models.Model):
name = models.CharField(max_length=100)
# 学生表, country 字段是国家表的外键,形成一对多的关系
class Student(models.Model):
name = models.CharField(max_length=100)
grade = models.PositiveSmallIntegerField()
country = models.ForeignKey(Country,
on_delete=models.PROTECT)创建方式:
方式1:
obj= 类(name=”“)
obj.save()
类实例化后, 然后用save,实际上就执行了sql,可以用 connection.queries 查看到
connction 是django 连接数据库时的一个东西
查询的时候要 导入才能用
from django.db import connection 补充:查看实际sql

方式2:
用objects的create方法,其中自动去save了
类.objects.create(name='中国')
from common.models import *
c1 = Country.objects.create(name='中国')
c2 = Country.objects.create(name='美国')
c3 = Country.objects.create(name='法国')
Student.objects.create(name='白月', grade=1, country=c1)
Student.objects.create(name='黑羽', grade=2, country=c1)
Student.objects.create(name='大罗', grade=1, country=c1)
Student.objects.create(name='真佛', grade=2, country=c1)
Student.objects.create(name='Mike', grade=1, country=c2)
Student.objects.create(name='Gus', grade=1, country=c2)
Student.objects.create(name='White', grade=2, country=c2)
Student.objects.create(name='Napolen', grade=2, country=c3)小小的补充创建子表的两种方式(知道就行):
第一种:如上,创建Student表
第二种:可以这么写:Student.objects.create(name='白月', grade=1, country_id=c1_id)
1.查询:
查询结果为多个的QuerySet列表形式
QuerySet对象的特性:
支持链式调用
惰性查询,仅仅在使用时才执行sql语句,如:len(), count(), 通过切片
对象列表
返回的是QuerySet列表的形式(仅数据对象)
Country.objects.all()
结果为:<QuerySet [<Country: Country object (1)>, <Country: Country object (2)>, <Country: Country object (3)>]>
筛选数据:如果筛不出来就返回空的QuerySet列表
Country.objects.filter(name="中国",id="1") # 筛选方式1 且的关系 Country.objects.filter(name="中国").filter(id=1) # 筛选方式2
小技巧:
如果id是 主键,可以写成 pk=* 对于查询级列表,
可以像列表一样切片,
可以.first() .last() 最后一个 .count() 列表数量 .exists() 是否存在 .ordey_by排序详细看后面
可以进行 for 循环
含数据的列表
返回的是QuerySet列表的形式(所有数据及所有字段) Country.objects.values() 格式: <QuerySet [{'id': 1, 'name': '中国'}, {'id': 2, 'name': '美国'}, {'id': 3, 'name': '法国'}]> 筛选展示:如 Country.objects.values("name") 则结果为:<QuerySet [{'name': '中国'}, {'name': '美国'}, {'name': '法国'}]> 筛选数据(类似where条件):Country.objects.values("name").filter(name="法国") 则结果为:<QuerySet [{'name': '法国'}]> 如下,可以这样把数据库的数据展示再页面上补充:QuerySet API reference | Django documentation | Django
从官网中看到, Country.objects ,后面还可以加 value_list() 等等
[(字段数据1,字段数据2),(),()]
aggregate() ,聚合运算
固定搭配:values 和 annotate , 分组父表的id,然后查询每个id的从表数据有多少个。

用 value_list时,可以加flat=True的参数,但只能指定一个字段

具体的对象
返回具体的对象:
类.objects.all()[0] # 第一个
类.objects.all().first() # 第一个
get方式根据字段查询:
Country.objects.get(id=1)
Country.objects.get(name="美国")
如果:查不到、或者查出来有多个,都会抛出异常, 所以最好使用有唯一约束的条件去查询下

查询的方式
QuerySet查询集列表的 过滤 查询类型
Country.objects.filter() filter中的查询类型

常用的:
id__gt = 5 表示 大于5 注: id后面要默认带出关键字才能用(自定义的id好像才能用)
id__lt = 5 小于5
id__gte = 5 表示 大于等于5
id__lte=5 小于等于5
id__in=[1,2,5]
name__exact="中国" 补充: name=“中国” 默认就是name__exact
name__iexact="Abc" 全匹配,并忽略大小写
name__contains='美' 包含
name__icontains='x' 包含 忽略大小写
name__startswith='中' 以中开头的
name__icontains='x'
name__endswith='国' 以国结束的
name__iendswith='国'
补充=== filter() 的反义 用 exclude() ,
如 exclude( name__contains='美' ) ,表示不包含 美 的数据
官网-model 中的 querySet 的 lookups:QuerySet API reference | Django documentation | Django
还有
如: __range =(开始时间,结束时间)
__regex =r"^(An?|The) +" --正则
外键字段用法补充:
如国家--人 一对多案例
学生表中有个country 字段,可以些country__国家表的字段,如
country__name

以上是两表查询,实际上还有多表查询(没试过)

外键表字段+ 查询条件, 如下:
list3=Student2.objects.filter(grade=1,country__name__icontains='国')
for i in list3:
print(i.name)

多张表的查询举例:
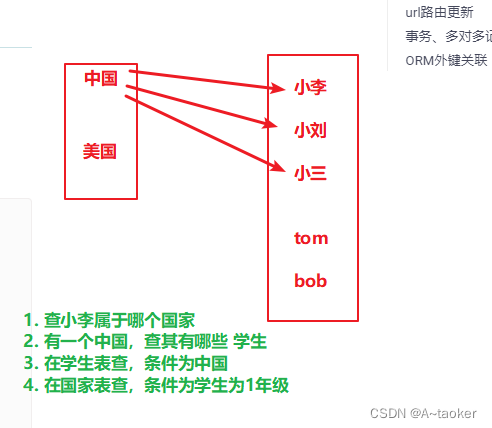

关联方式总结:
country__name 表示国家表的名字字段, 查学生用 Student2.objects.filter(条件)( 例3)
students__grade 表示学生的grade字段。 查国家用 Country.objects.filter(条件)( 例4 )
stu1.country 一学生属于哪个国家 (例1)
c1.students 一个国家下的学生们 (例2)
------------------------1.已知一个学生,查其国家------------------------------------------------
查看某个学生,属于哪个国家,同上面的a
s1 = Student.objects.get(name='白月')
s1.country.name
-------- 2.已知一个国家,查有哪些学生属于这个国家------------定义 related_name ,就能反向查询-
如:此列子是反向查询所有
例子4:是反向查询,并且过滤每个字段
方式1: cn = Country.objects.get(name='中国') cn.student_set.all() 结果同Students.object.all() 的查询集列表 通过表Model名转化为小写 ,后面加上一个 _set, 来获取所有的反向外键关联对象 方式2:定义外键时:用related_name,指反向查询时用什么名字: 可以想象成。 给Country表增加了一个东西 叫 students。 某个国家.students 来使用cn.students .all()
class Student2(models.Model): name = models.CharField(max_length=100) grade = models.PositiveSmallIntegerField() country = models.ForeignKey(Country, on_delete=models.PROTECT, # 指定反向访问的名字 related_name='students' )
------------------------ 3.查子表-学生们,条件有学习的字段 、国家的字段。(关联查询)-------------
查看学生,一年级 且 国家为中国的(快捷写法,外键__外键表的字段名) Student.objects.filter(grade=1,country__name='中国').values()
如果返回结果只需要 学生姓名 和 外键表的国家名两个字段,可以这样指定values内容
Student.objects.filter(grade=1,country__name='中国') .values('name','country__name')
另命名:如下代码
from django.db.models import F # annotate 可以将表字段进行别名处理 Student.objects.annotate( countryname=F('country__name'), studentname=F('name') )\ .filter(grade=1,countryname='中国').values('studentname','countryname')
------------------------ 4.查父表-国家表,条件为学生的字段---------(关联查询)----------------------------
Country.objects.filter(students__grade=1).values().distinct()
或:Country.objects.filter(students__name__contains="月")
students为上面讲的定义的related_name
注意:据说
.distinct()对MySQL数据库无效,我没有来得及验证。实测 SQLite,Postgresql有效。
逻辑关系
且关系:
一个filter中写多个条件,中间用逗号隔开,或者,链式调用,连续的filter 就是and关系
如上的例子3就是且的关系。
Student.objects.filter(grade=1,country__name='中国')
或者 Student.objects.filter(grade=1).filter(country__name='中国')
或关系:
from django.db.models import Qqs = Student2.objects.filter(Q(name__contains="白") | Q(grade="1"))
查询集的排序: Country.objects.all().order_by("name") # 默认升序# 降序的写法
Country.objects.all().order_by("-name")
# 多个字段排序的时候
Student2.objects.all().order_by("-grade","name")
更新
更新一条数据, 直接改,然后save()一下
c1.name="新中国"
c1.save()
或者指定:要更新哪些字段 c1.save(update_fields=["name"])
批量更新多条数据、使用update方法 无需调用svae
Student2.objects.filter(name__contains="白").update(grade=4)
删除
使用delete()方法
c1.delete()
删除多条数据,也是用delete()方法
qurrset查询.delete()
如 Student2.objects.filter(name__contains="白").delete()
#测试后,补上数据。
c1 = Country.objects.get(name="中国")
Student2.objects.create(name='白月', grade=1, country=c1)
项目举例:
相关知识点:














 1361
1361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









