







开始写之前,先推荐几个介绍贝叶斯分类方面比较好的文章。
数学之美番外篇:平凡而又神奇的贝叶斯方法
算法杂货铺——分类算法之朴素贝叶斯分类
1.问题背景
贝叶斯方法最出是有托马斯·贝叶斯提出,在他提出这个方法的时候,并不为当时的人们所熟知。他在生前发表了一篇用来求解‘逆概’问题的文章,直到死后才被朋友发表出来。
考虑这样的一个实际场景,现在有一个袋子,袋子里面装有若干个白球和黑球,现在随机的从袋子当取一个求出来,问你取到白球的概率是多少,取到黑球的概率是多少,根据生活常识,我们很容易通过黑球和白球的多少估计出各自的概率大小。如果现在我们并不知道袋子中黑球和白球的个数,随机的从袋子中摸出一个球出来,这样连续的重复几次实验,我们可以根据摸出的球来估计袋子中白球和黑球各自的所占比例大小吗?仅仅根据摸出的球来知道袋子中球的情况,这个时候就只能猜测了,可以算出各种可能的大小,在这各种可能中选取最靠谱的猜测。那么这个例子和我们的贝叶斯方法有什么联系吗?如果说事先知道袋子中球的情况来求概率是一个正向问题的话,那么根据摸出的球来估测袋子中球的分布情况的话就是一个反向概率问题。
2.贝叶斯公式
在介绍贝叶斯公式之前,先给出条件概率公式:
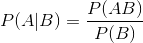
条件概率公式说明的是在时间B发生的情况下求事件A发生的概率可以通过求事件AB同时发生的概率除以时间B发生的概率。
贝叶斯公式:
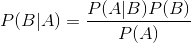
在贝叶斯公式中,求事件A发生的情况下时间B发生的条件概率,通过条件概率公式可以转化为求事件B发生的情况下时间A的条件概率和事件B发生的概率。在这里我们把P(B|A)叫做后验概率,P(B)叫做先验概率,P(A|B)叫做类条件概率,P(A)叫做证据因子。那么为什么好好的求取条件概率非得转化成贝叶斯公式来求解呢?是因为在实际中,有些情况下直接求后验概率是不容易的,而求先验概率却是十分容易的,所以往往就可以通过这样的一个转化进行求解。下面利用一个具体的额实例来进行说明。
给出实际应用中的一个实例来说明应用贝叶斯公式的好处。比如我们在进行网络检索时,往往会因为一时的疏忽而导致了输入出错,如果用户输入了字典中不存在的单词,那么从局外人的角度来看,我们就会想他到底是想要输入什么呢,此时我们就会根据这个输入错误的单词来联想他可能想要输入的单词,如果我们把用户输入错误单词记作X,用户想要正确输入单词记作C,那么现在想要完成的是知道概率P(C|X)的大小,在这里C是不确定的,因为猜测有多种可能,我们不妨一次将这些可能的结果记作(C1,C2...Ch),它们都属于一个有限且离散的猜测空间 H ,由贝叶斯公式可以得到P(C|X)=P(C)*P(X|C)/P(X),在比较P(C|X)的时候,分母P(X)都是一样的,所以这里只需要比较分子的大小即可,分子中,P(C)是先验概率,可以直接计算得到,P(X|C)是类条件概率,可以通过联合概率公式计算,比如说现在我们想要输入单词the,却一不小心输入了rhe,根据输入的rhe来猜测应该输入的是什么,可能是the,也可能是she等等,那么只需要计算the和rhe在单词库中出现的概率大小,对应的就是P(C),在分别计算输入the却输入了rhe和输入she却输入了rhe的概率大小,计算对应的乘积,比较结果大小,结果较大的那个就是最可能输入的值。
2.朴素贝叶斯
朴素贝叶斯分类算法,这里的朴素体现在哪里呢,跟一般的贝叶斯方法又有什么不同呢,还是我们上面的例子,上面的例子说计算输入the却输入了rhe的概率,那么具体的可以怎样计算呢?可以根据字母在键盘上面的位置关系来算,比如字母t距离r的距离明显的小于字母s距离r。更一般的,在分类问题中P(X|C)中的X表示的是特征向量,对于一个特征向量来说,属性与属性之间多多少少是存在着一定的联系的,也就是不是互相独立的,这样一来计算类条件概率就不容易了,这个联合概率密度很难从有限的训练样本中直接估计得到。为了避开这个障碍,我们假设属性之间是互相独立的,也就是每个属性独立的对分类结果产生影响。这样的假设从直观上说好像是不符合事实的,比如说在文本分类中,前后单词之间往往会存在着一定的联系。但是事实证明,基于朴素贝叶斯属性之间条件独立的假设可以取得很好的分类效果。
基于上述条件独立的假设,可以将贝叶斯公式变形如下:
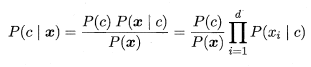
这里P(x|c)利用联合概率公式来代替,只需要求在给定类别c的情况下,每一个属性对应的特征发生情况即可。在实际的计算中,有时候为了减少运算量,式子两边取对数操作,将乘法转化为加法。很显然,朴素贝叶斯分类器的训练过程就是基于训练集来估计类先验概率P(C)和并为每个属性估计条件概率P(Xi|C)
3.连续和平滑处理
对于离散的数值来说,很容易统计包含某一个属性特征值得样本在整体样本中出现的次数,以此可以来计算先验概率。对于连续的数值来说,往往假设概率密度函数是符合一个正态分布,则可以通过下面的公式来求解:
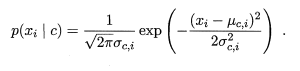
注意到,如果某一个属性值在训练集中没有与某一个类别同时出现,则直接利用公式计算得到的概率将会是0,因此,无论该样本的其他属性值是什么,最后的结果总是0,这显然是不符合事实的,所以要进行平滑处理。用N表示训练集D中可能的类别数,Ni表示第i个类别可能的取值数,则计算先验概率和类条件概率的公式可以如下表示:
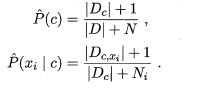
这样就避免了因为分子为0导致最后的结果为0的情况。















 1221
1221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









