






-
Naive Bayes 算法基本原理
假设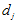
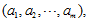

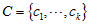
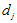

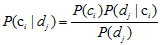
因为

其中,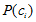

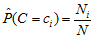
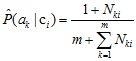
式中,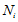
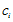
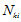

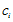
对样本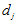
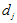
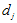
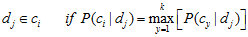
-
算法求解
对于贝叶斯判别,首先确定一个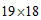
TO FROM | A | B |
A | 9 | 1 |
B | 0 | 9 |
由以上结果可以发现,A类中有9个样品得到正确的判别,还有1个样品被错误判到B类;B类中的9个样品均得到正确的判别。因此Bayes判别效果较好。则对10个未判别的DNA序列进行判别,程序见附录。最终得到分类结果为:
类别 编号 | A类 | B类 |
DNA编号 | 21,22,23,24,26,27,28,29,30 | 25 |















 7576
7576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









