







po在前头:本人不是研究NLP领域的,看这篇论文主要想借鉴一下思想,所以笔记内容着重讲了思路,具体细节还请看论文原文,有任何错误的地方欢迎评论区指出。若有转载请标明出处,谢谢。
论文链接: https://arxiv.org/pdf/2001.09386v3.pdf
Part 01 笔记
作者:

任务:
为新闻故事(新闻文章组)生成标题。
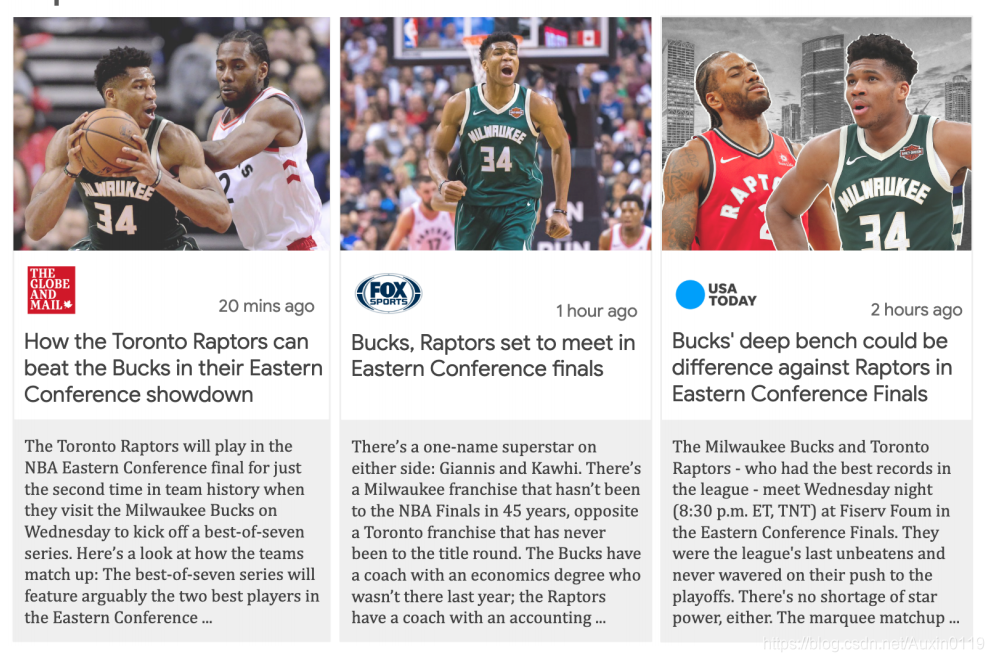
理解:每一个新闻事件可以称为一个新闻故事(news story),每个故事有多个新闻文章(news articles),如下图所示为三个新闻文章,他们均讲述了一个故事,也就是属于一个新闻故事。而本文的任务就是基于新闻文章-标题对的数据集,生成新闻故事的标题。
贡献:
(1)我们提出了新闻报道标题生成的任务,并发布了第一个大规模的人类标注的数据集,以服务于研究社区;
(2)我们提出了一种具有多级预训练框架的远程监管方法来训练大规模生成模型,而无需任何人工注释。可以通过合并人类标签来进一步增强该框架,但可以大大减少标签的需求;
(3)我们开发了一种新颖的基于自投票的文章关注模块,该模块可以有效地提取不同文章共同共享的重要信息,并且对输入新闻故事中的噪声具有鲁棒性。
数据集:
- NewSHead:包含35.7万个新闻故事,每个故事包含3-5个新闻文章(文章标题对),每一个故事都有人工标注的标题。
- NewSHeaddist:包含220万个新闻故事,每个故事包含3-5个新闻文章(文章标题对),每一个故事标题都是由远程监督生成的。
远程监督:
对于每个故事A,我们旨在通过选择最具代表性的文章标题来获得其启发式标题yˆ:
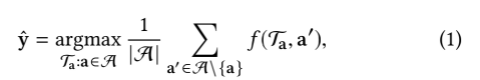
其中Ta代表文章a的标题,而f(T,a)代表任何标题T与文章a之间的语义匹配分数。请注意,a仅在主要段落中包含tokens。换句话说,文章标题的分数是标题与故事中其他文章之间的平均匹配分数。
用BERT预训练的Transformer模型,计算新闻故事A内的文章ai标题ti与其他文章aj的匹配分数(用文章ti可用于描述aj的概率表示),取和所有文章匹配度之和最高的文章标题t作为故事标题T。通过使用现有的文章标题对作为正实例,并采样随机对作为负实例来获取训练数据。
因为可能存在故事中所有文章标题都不足以作为故事标题的情况,这里只计入了包含正标签的故事。
(如果标签在所有文章中的平均预测得分高于0.5,则标签为正。)

模型:基于transformer的encoder-decoder模型作为基本架构。
-
预训练1:用包含50M篇文章的语言模型预训练数据集(新闻文章的主要段落),学习初始化编码器模块和单词嵌入层的参数,解码器使用另一篇文献中的方法进行初始化。
-
预训练2:用包含1000万篇文章的单文档预培训数据集(精选的文章标题对),进一步调整编码器和解码器模块参数,以及他们之间的相互关注。
-
encoding阶段:每篇文章a单独输入,并生成隐层表示Hia,将输入文章组A的向量表示为{Hia}的加权和,即
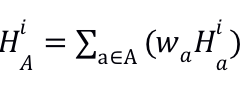
权重系数{wa}由通过文章级别关注学习的相似度矩阵确定。 -
decoding阶段:通过文章组的隐层表示,生成新闻故事A的标题T。
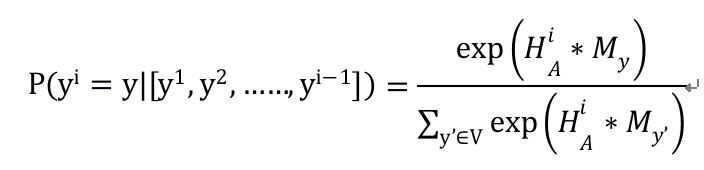
给定[y1,y2,…,yi-1],上面的等式2定义了给定yi成为y的概率。 V是整个词汇表,My是与标记y相对应的可学习的嵌入矩阵M∈RdH×| V |的列。使用波束搜索(beam search)来找到top-k输出序列,使下式最大化:
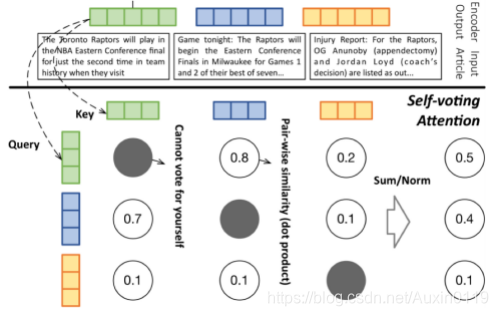
基于投票的文章级注意力:
基本思想:让每篇文章投票支持故事中的其他文章。总得分高于其他文章的文章应具有更高的关注度。
优点:大多数文章共享的公共信息会在获得更多票数时回显和放大,而与此无关的文章将在此交互式过程中被淡化,以减少对最终输出的有害干扰。
给定文章a的表示向量Ha,我们将其查询(query)向量和关键(key)向量分别计算为Qa = WQ * Ha和Ka = WK * Ha,其中WQ和WK是所有文章共享的可学习矩阵。然后将a的注意力得分计算为:
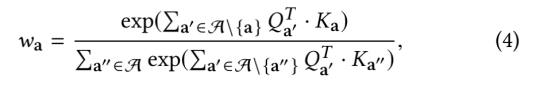
其中exp(QTa’·Ka)表示a’对a的投票。举例如下:
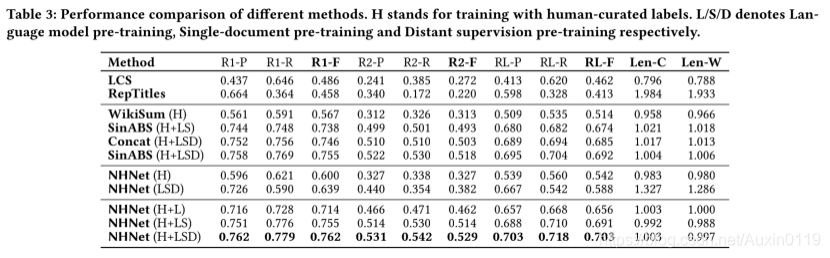
实验结果:
(因为是新任务,所以作者在作对比的时候进行了一些筛选和处理,具体的请看论文)
Part 02 翻译
本文翻译基本来自google翻译,对于2、3、4、5章节进行了少量手动调整及配图,仅供参考。
摘要
每天都有数以百万计的新闻文章在线发布,这对于读者而言可能是压倒性的。将报道同一事件的文章分组为新闻故事是帮助读者消费新闻的一种常用方法。但是,有效地为每个故事生成具有代表性的标题仍然是一个具有挑战性的研究问题。对文档集的自动汇总已进行了数十年的研究,而很少有研究集中于为一组文章生成代表性的标题。摘要不同于旨在捕获最少冗余的大多数信息的摘要,标题旨在捕获故事文章在短时间内共同共享的信息,并排除每个文章的特定信息。
在这项工作中,我们研究为新闻报道生成代表性标题的问题。我们开发了一种远程监管方法来训练大规模生成模型,而无需任何人工注释。拟议的方法以两个技术要素为中心。首先,我们提出了一个多层次的预训练框架,该框架结合了具有不同质量与数量平衡在不同层次上的大量未标记语料库。我们显示,在多级预训练框架内训练的模型优于仅使用人类管理语料库训练的模型。其次,我们提出了一种新颖的基于自投票的文章关注层,以提取多个文章共享的显着信息。我们表明,包含此关注层的模型对于新闻报道中的潜在噪声具有鲁棒性,并且在干净和嘈杂的数据集上均优于现有基准。我们通过合并人类标签进一步增强了我们的模型,并表明我们的远程监管方法大大减少了对标签数据的需求。最后,为了为研究社区服务,我们在新闻报道的标题生成上发布了第一个手动策划的基准数据集NewSHead,其中包含367K个故事(每个故事包含3-5条文章),是当前最大的多文档摘要数据集的6.5倍。
1 引言
当今的新闻消费者被新闻内容所淹没,每天发布超过200万条新闻文章和博客文章1。结果,组织新闻文章的服务已经在在线用户中流行。一种方法是将文章分类为预定义的新闻主题,每个主题都带有简短的类别标签,例如“技术”,“娱乐”和“体育”。尽管组织得井井有条,但多余的内容仍可以出现在每个主题中。另一个更有效的方法是根据新闻故事在每个主题中对文章进行进一步分组。在这里,每个故事都由报道同一事件的一系列文章组成。新闻故事使完成读者的新闻消费之旅更加有效-读者可以从一个故事到另一个故事,并根据需要深入研究每个故事。但是,当我们仅列出文章标题列表时,读者将无法通读故事的要旨,直到他们通读了几篇文章为止,因为文章标题是针对特定文章量身定制的,因此无法提供整个故事的概述。此外,标题可能太长而无法浏览,尤其是在移动设备上。
为了解决这个问题,我们建议以简洁明了的标题来
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









