







数据挖掘:模型选择——监督学习(分类)
机器学习算法可分为监督学习和非监督学习。本文主要讨论非监督学习中的分类任务。
一、简单介绍
简单的说,监督学习就是有标签的数据,有需要预测的变量。
分类任务就是预测的变量数据为离散型。比如,将天气数据放入模型中,来预测明天是否下雨(下或不下,两种结果),为分类任务。预测降雨量具体是多少,为回归任务。
而分类任务一般分为二分类和多分类。先介绍二分类。本文将对一些常用算法的主要思想,特点和sklearn中的调参进行说明。
二、KNN
简单介绍:
KNN(k-NearestNeighbor)即K-近邻算法。一句话总结就是近朱者赤,近墨者黑。KNN算法为给定⼀一个训练数据集,对新的输⼊入实例例,在训练数据集中找到与该 实例例最邻近的K个实例例,这K个实例例的多数属于某个类,就把该输⼊入实例例分为这个类。
k 近邻算法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。
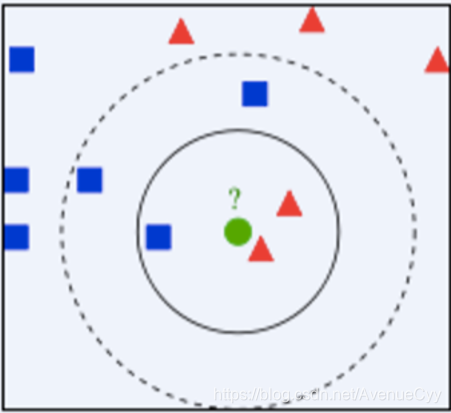
- 如果K=3,绿色圆点最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多 数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最近5个邻居是2个红色角形和3个蓝色的正方形,还是少数从属于多 数,基于统计的方法,判定绿色这个待分类点属于蓝色的正方形一类。
工作原理:
假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系。
输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较。
- 计算新数据与样本数据集中每条数据的距离。
- 对求得的所有距离进行排序(从小到大,越小表示越相似)。
- 取前 k (k 一般小于等于 20 )个样本数据对应的分类标签。
求 k 个数据中出现次数最多的分类标签作为新数据的分类。
主要参数:
通过上述原理的说明,可将主要参数归总为k值的选择、距离度量以及分类决策规则是k近邻算法的三个基本要素。
-
k值选择:如果选择较小的K值,近似误差减小,估计误差增大。意味着整体模型变得复杂,容易发生过拟合(容易受到训练数据的噪声而产生的过拟合的影响)。选择较大的K值,模型会变得简单。在实际应⽤用中,K值⼀般取⼀个比较小的数值。通常采用交叉验证法来选取最优的K值(经验规 则:K一般低于训练样本数的平方根)。
-
距离度量:特征空间中两个实例点的距离可以反映出两个实例点之间的相似性程度。K近邻模型的特征空间 ⼀一般是N维实数向量量空间,使⽤用的距离可以是欧式距离,也可以是其他距离。
-
分类决策:多数表决,即由输⼊入实例例的K个邻近的训练实例例中的多数类决 定输⼊入实例例的类。
算法特点:
- 优点:精度高、对异常值不敏感、无数据输入假定
- 缺点:计算复杂度高、空间复杂度高
sklearn代码:
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier()
clf.fit(train_x, train_y)
三、决策树
简单介绍:
决策树是模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是 if-then 规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性(features),叶结点表示一个类(labels)。
用决策树对需要测试的实例进行分类:从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分配到叶结点的类中。

决策树学习通常包括 3 个步骤:特征选择、决策树的生成和决策树的修剪。
特征选择:
若一个特征具有很好的分类能力,那么就应该选择这个特征。选择的准则是信息增益或是信息增益比。
熵: 熵指的是体系的混乱的程度。一种信息的度量方式,表示信息的混乱程度,也就是说:信息越有序,信息熵越低。例如:火柴有序放在火柴盒里,熵值很低,相反,熵值很高。
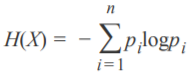
条件熵:在某一条件下,随机变量Y的不确定性。
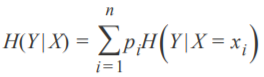
信息增益:在得知特征X的信息下,使得Y信息的不确定性减少的程度。 在划分数据集前后信息发生的变化。

所以,我们可以用信息增益作为准则来选择特征。不同的特征划分数据集有不同的信息增益,选择信息增益最大的特征。但信息增益存在偏向于选择取值较多的特征,比如ID这类数据。可以用信息增益比来对这个问题进行校正。
信息增益比:将HA(D)放在分母,可有效降低以上的问题。比如对于ID这个特征。它的HA(D)的值就会很大,因为特征中类别数量较多。

Gini系数:也表示数据集的不确定性。Gini系数越大,不确定性就越高,数据集纯度越低。与熵类似。


ID3算法是在决策树各个结点上用信息增益来选择特征。
C4.5是利用信息增益比。
CART利用Gini系数来选择特征的。可用于分类和回归,假定决策树是二叉树。
决策树的生成:确定特征选择的标准后,就能够生成一颗决策树。但会过度细分,产生过拟合。因此需要对决策树进行剪枝。
决策树的修剪:可以在生成树之前设定参数,进行剪枝。也可以在树生成后,逐渐调整参数进行剪枝。
工作原理:
ID3算法:计算所有特征的信息增益,从中选择最好的对数据集进行划分。对划分后的子集,再分别计算剩下的特征的信息增益,从中分别选择最好的对各个子集进行划分。不断重复该步骤,直到所以特征的信息增益达到阈值后者没有特征可选为止。

CART算法:利用Gini系数来选
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2981
2981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









