







文章目录
分类与回归
- 分类
- 目标:预测类别标签,标签来自预定义的可选列表
- 分类问题
- 二分类(两个类别之间进行区分的一种特殊情况)
- 正类
- 反类
- 多分类(两个以上的类别之间进行区分)
- 二分类(两个类别之间进行区分的一种特殊情况)
- 回归
- 目标:预测一个连续值——浮点数/实数
- 例子:
- 根据教育水平、年龄和居住地来预测一个人的年收入,这就是回归的一个例子。在预测收入时,预测值是一个金额(amount),可以在给定范围内任意取值。
- 根据上一年的产量、天气和农场员工数等属性来预测玉米农场的产量。同样,产量也可以取任意数值。
区分分类任务和回归任务有一个简单方法,就是问一个问题:输出是否具有某种连续性。如果在可能的结果之间具有连续性,那么它就是一个回归问题。
与此相反,对于识别网站语言的任务(这是一个分类问题)来说,并不存在程度问题。网站使用的要么是这种语言,要么是那种语言。在语言之间不存在连续性,在英语和法语之间不存在其他语言。
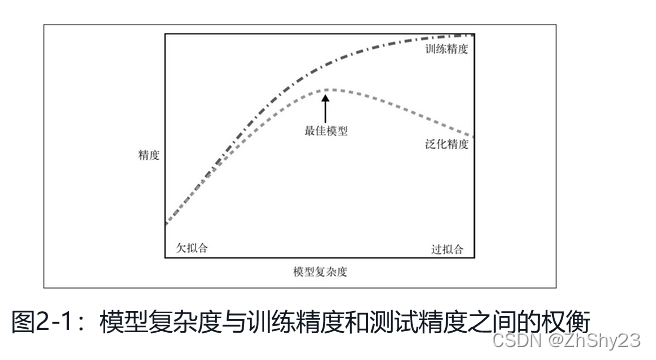
泛化、过拟合与欠拟合
如果一个模型能够对没有见过的数据进行准确预测,我们就说它能够从训练集泛化
到测试集。我们需要构建一个泛化精度尽可能高的模型
如果在拟合模型的时候过分关注训练集的细节,得到了一个在训练集上表现很好,但不能泛化到新数据上的模型,那么就存在过拟合。
如果模型过于简单,可能无法抓住数据的全部内容以及数据中的变化,在训练集上的表现就很差,被称为欠拟合
我们的模型越复杂,在训练数据上的预测结果就越好。但是,如果我们的模型过于复杂,我们开始过多的关注训练集上每个单独的数据点,模型就不能很好的泛化到新数据上。
二者之间存在一个最佳位置,可以得到最好的泛化性能,这就是我们想要的模型。
模型复杂度与数据集大小的关系
模型复杂度与训练数据集中输入的变化密切相关:数据集中包含的数据点的变化范围越大,在不发生过拟合的前提下你可以使用的模型就越复杂。
通常来说,收集更多的数据点可以有更大的变化范围,所以更大的数据集可以用来构建更复杂的模型。但是,仅复制相同的数据点或收集非常相似的数据是无济于事的。
收集更多数据,适当构建更复杂的模型,对监督学习任务往往特别有用。
监督学习算法
一些样本数据集
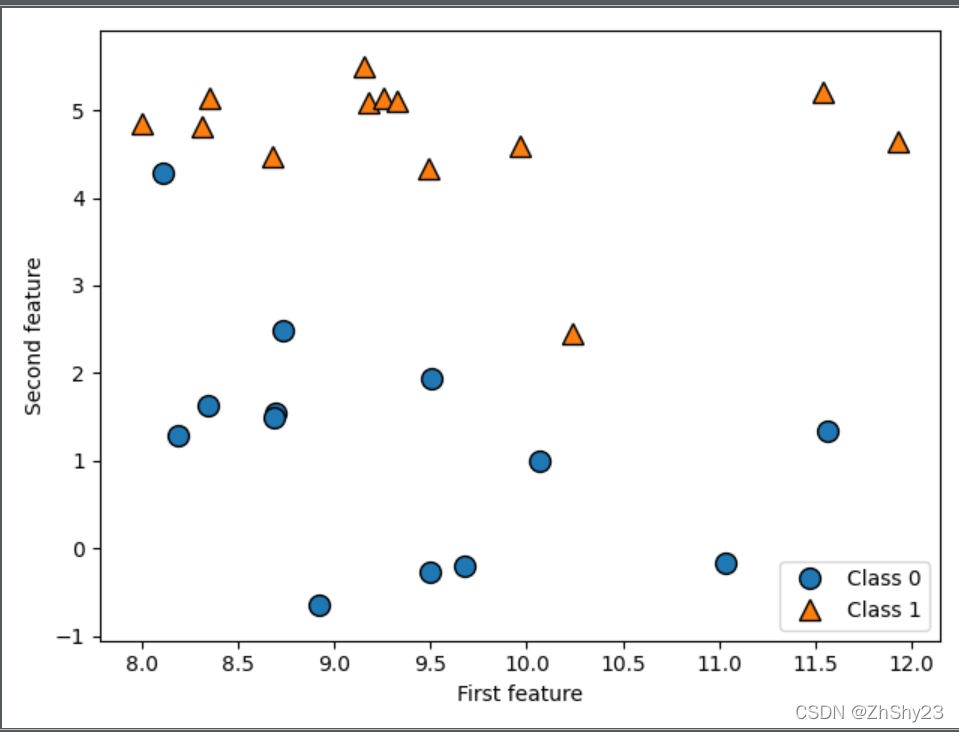
1. 二分类 - forge数据集
一个模拟的二分类数据集示例是forge数据集,它有两个特征。下列代码将绘制一个散点图(图2-2),将此数据集的所有数据点可视化。图像以第一个特征为x轴,第二个特征为y轴。正如其他散点图那样,每个数据点对应图像中的一点。每个点的颜色和形状对应其类别:
import mglearn as mglearn
import matplotlib.pyplot as plt
X, y = mglearn.datasets.make_forge()
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
plt.legend(["Class 0", "Class 1"], loc = 4)
plt.xlabel("First feature")
plt.ylabel("Second feature")
print("X.shape: {}".format(X.shape))
plt.show()
--------------------------------------
X.shape: (26, 2)
从X.shape可以看出,这个数据集包含26个数据点和2个特征。
2. 回归算法 - Wave数据集
我们用模拟的wave数据集来说明回归算法。wave数据集只有一个输入特征和一个连续的目标变量(或响应),后者是模型想要预测的对象。下面绘制的图像中单一特征位于x轴,回归目标(输出)位于y轴:
import mglearn as mglearn
import matplotlib.pyplot as plt
X, y = mglearn.datasets.make_wave(n_samples = 40)
plt.plot(X, y, 'o')
plt.ylim(-3, 3)
plt.xlabel("Feature")
plt.ylabel("Target")
plt.show()
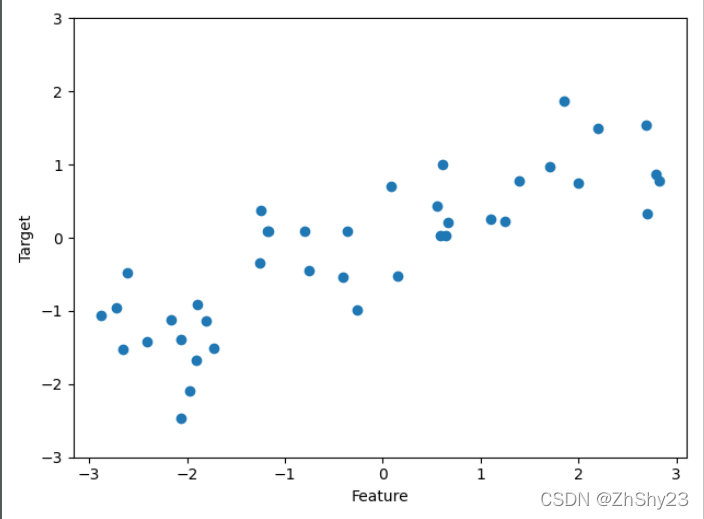
我们之所以使用这些非常简单的低维数据集,是因为它们的可视化非常简单——书页只有两个维度,所以很难展示特征数超过两个的数据。从特征较少的数据集(也叫低维数据集)中得出的结论可能并不适用于特征较多的数据集(也叫高维数据集)
3. 分类 - cancer数据集
威斯康星州乳腺癌数据集(简称cancer),里面记录了乳腺癌肿瘤的临床测量数据。每个肿瘤都被标记为“良性”(benign,表示无害肿瘤)或“恶性”(malignant,表示癌性肿瘤),其任务是基于人体组织的测量数据来学习预测肿瘤是否为恶性。
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
print("\ncancer.keys(): \n{}".format(cancer.keys()))
-------------------------------------------------------------
cancer.keys():
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
包含在scikit-learn中的数据集通常被保存为Bunch对象,里面包含真实数据以及一些数据集信息。关于Bunch对象,你只需要知道它与字典很相似,而且还有一个额外的好处,就是你可以用点操作符来访问对象的值(比如用bunch.key来代替bunch[‘key’])。
# 包含569个数据点,每个数据点有30个特征
print("\nshape of cancer data:{}".format(cancer.data.shape))
# 在569个数据点中,212个被标记为恶性,357个良性
print("\nSample counts per class: \n{}".format(
{n: v for n, v in zip(cancer.target_names, np.bincount(cancer.target))}
))
-----------------------------------
shape of cancer data:(569, 30)
Sample counts per class:
{'malignant': 212, 'benign': 357}
4. 回归 - boston数据集
波士顿房价数据集。与这个数据集相关的任务是,利用犯罪率、是否邻近查尔斯河、公路可达性等信息,来预测20世纪70年代波士顿地区房屋价格的中位数。这个数据集包含506个数据点和13个特征:
from sklearn.datasets import load_boston
boston = load_boston()
print("Data shape: {}".format(boston.data.shape))
----------------------
Data shape: (506, 13)
对于我们的目的而言,我们需要扩展这个数据集,输入特征不仅包括这13个测量结果,还包括这些特征之间的乘积(也叫交互项)。换句话说,我们不仅将犯罪率和公路可达性作为特征,还将犯罪率和公路可达性的乘积作为特征。像这样包含导出特征的方法叫作特征工程(feature engineering)
这个导出的数据集可以用load extended boston函数加载:
X, y = mglearn.datasets.load_extended_boston()
print("X.shape: {}".format(X.shape))
-----------------------------
X.shape: (506, 104)















 1745
1745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











