







机器学习应用的典型领域有网络安全、搜索引擎、产品推荐、自动驾驶、图像识别、语音识别、量化投资、自然语言处理等。
以下为7个领域的例子:
1. 艺术创作
图像处理方面的应用较多。
主要的技术就是:卷积神经网络 (CNN) 。CNN 最擅长的就是图片的处理。它受到了人类视觉神经系统的启发。
机器学习在图像处理领域应用非常广泛,除了图像识别、照片分类等,最近几年图像处理方面的创新应用已经涉及了图片生成、美化、修复和图片场景描述等(具体来说比如:人脸识别、自动驾驶、美图秀秀、安防等等)。
具体的项目比如:

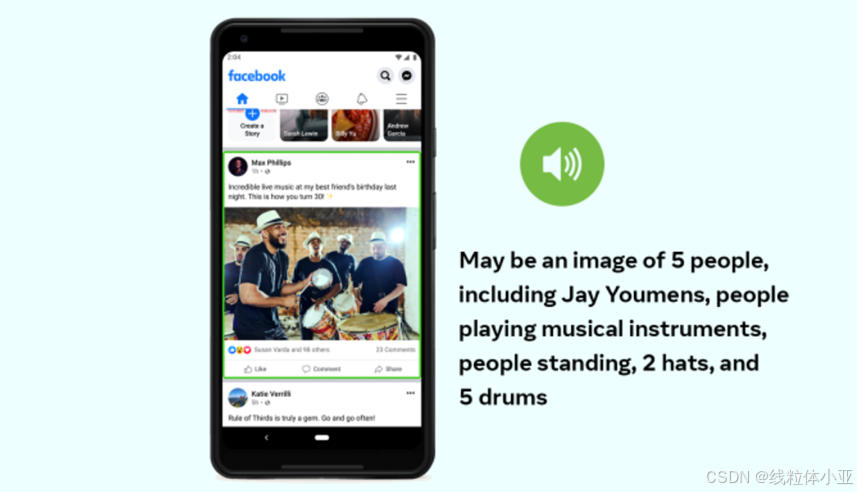
脸书(Facebook)公司开发的一款可以描述图片内容的应用。
这个应用在2021 年 11 月 2 日有个更新:就是他们公司会大幅减少面部识别技术的使用。意思就是他们会删除之前的面部识别模板。所以说,他的这个应用,还是可以识别照片中的人,但它不再包含人名(估计是涉及到了隐私问题)。
当时他们的这个应用就是想让盲人或视障用户也可以“看”到图片(或者说了解到图中的内容)。
所以,他们就使用了图像识别技术,然后用合成语音来描述图片的内容,这样就可以让盲人能够理解Facebook / Instagram里的图片是什么。
他们的这个应用在2018 年获得美国盲人基金会的海伦凯勒成就奖。

Neural Doodle(神经涂鸦)
Neural Doodle项目就是使用了深度神经网络,让大家可以通过合成的方式绘制一幅非常厉害的画。
原理:使用卷积神经网络,提取模板图片中的绘画特征,然后对你画的涂鸦图片再进行处理,最后合成一张新的图画。
下图就是这个项目的应用效果,按顺序,最上面是油画模板,中间是用户涂鸦的作品,下面是合成之后的新作品。



图像修复
神经网络还可以用于图像修复。
主要涉及的技术:对抗神经网络(GAN = Generative Adversarial Networks)和卷积神经网络进行结合。可以对图片中的缺失部分进行修复。
下图就是两个例子(都是在2016年发表的论文里的例子)。


PlaNet 神经网络模型
谷歌公司的 PlaNet (Deep Planning Network = 深度规划网络) ,是一个神经网络模型,它可以识别照片中的地理位置。
其实,照片地理定位是一项非常具有挑战性的任务。因为许多照片只提供很少的信息,可以用来推断他们的位置。例如,海滩的图像可以被带到世界各地的许多海滩。
下图的例子:
上面的3张照片是查询照片(要输入到模型里的照片)。
下面3张地图是结果输出:在地图上的大概位置(和他们的概率分布)。
首先第一组照片,你可以看到模型把埃菲尔铁塔,非常自信地分配给了巴黎。
第二组照片:你可以看到,这个模型觉得这张峡湾的照片,是在新西兰或者挪威拍摄的。
然后第三组照片,就是一张海滩的照片。模型把最高的概率分配给南加州(这个是正确的答案),但也把一些概率分配给有类似这样的海滩的地方,如墨西哥和地中海。
这个例子可以看出来,模型把地图进行了网格化,使图片对应于某一网格单元。
他这个模型的识别的误差距离大约为1131 千米。
而且虽然训练样本数量很大,但最终的神经网络模型的大小只有377MB。


2. 金融领域
机器学习在金融领域也有非常多的应用,比如:可以用来信用评分,用来检测欺诈,用来做股票市场的趋势预测,还有客户关系管理。
信用评分
信用评分是衡量人们信用的数字表示。银行业通常用它作为支持贷款申请决策的方法。
基本上,会审核你的职业、薪酬、所处行业、历史信用记录等信息确定客户的信用评分。

欺诈检测
机器学习可以检测和识别,用户购买过程中的数千种模式。 通过历史数据,可以预测出交易中的欺诈行为。

股票市场的趋势预测
预测股市是一件非常困难的事情。因为包含很多因素:比如物理或心理因素、理性或者不理性行为因素等等。所有这些因素结合在一起,就会使股价波动剧烈,很难准确预测。但是,你还是可以使用机器学习算法,分析上市公司的三大财务报表(资产负债表、现金流量表等)。你还可以分析,和企业相关的第三方资讯,如政策法规、新闻等等,让你的预测结果更准确。
具体的方法就比如:
- 用无监督学习,可以分析股票市场的影响因素。
- 强化学习,可以通过算法来找到最大化收益的策略。
客户关系管理
客户关系管理(CRM)是一个软件系统,专门用于管理公司和客户之间的关系。
当CRM 系统和机器学习结合起来,他们的应用就是优化营销和聊天机器人(智能对话)。

3. 医疗领域
糖尿病视网膜病变
糖尿病视网膜病变是一个非常严重的问题。 早期筛查和及时治疗可以降低视网膜病变的风险。
目前就可以通过深度学习,来检查视网膜图像,就可以确定哪些患者有致盲性眼病,这样就可以及时转诊给眼科医生。
具体的应用,就比如 Open Indirect Ophthalmoscope(开放式间接眼膜镜),可通过机器学习进行糖尿病性视网膜病变检测。

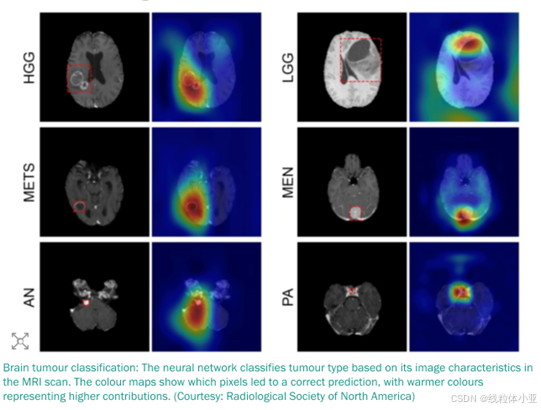
脑瘤
还有一种机器学习系统(运用了深度学习),可以把未经处理的大脑样本进行“柒色”,然后就可以诊断患者是否得了脑瘤。
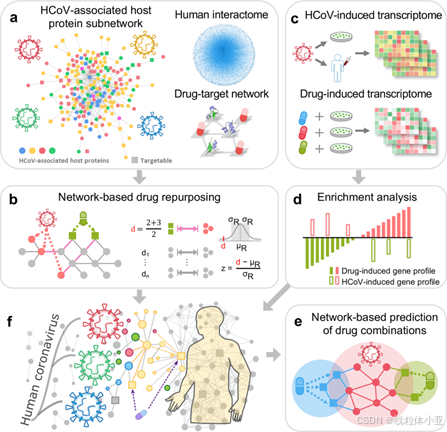
生物制药
麻省理工学院计算机科学与人工智能实验室 (CSAIL) ,利用深度学习,来发现新的药物组合,用来对抗新冠。
机器学习提供了一些解决方案,可以加速新抗病毒药物的发现和优化。原理就是:通过对药物和生物靶标之间的相互作用,然后进行建模。
这个模型不仅只限于一种新冠毒株,它还可能用艾滋病毒和胰腺癌。
心脏病
研究人员从大量心脏病患者的电子病历库,调取患者的医疗信息,如疾病史、手术史、个人生活习惯等,把这些信息进行建模,来预测患者的心脏病风险因素。
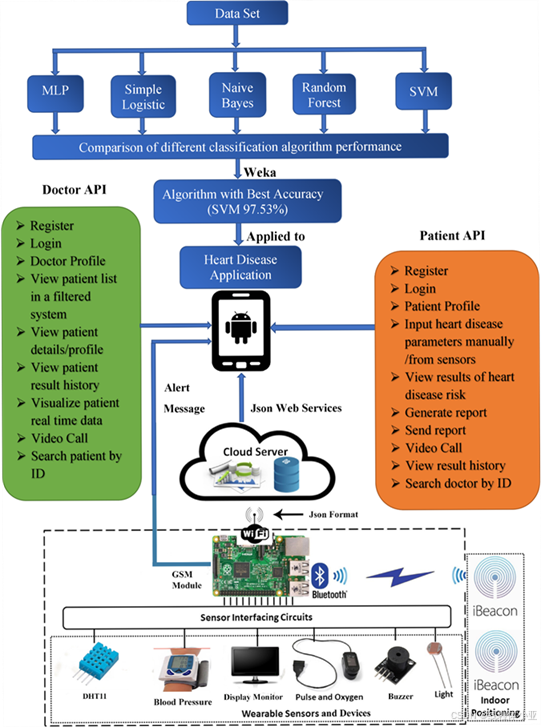
4. 自然语言处理(Natural Language Processing,NLP)
自然语言处理是人工智能和语言学领域的分支学科。
之前文章的SHRDLU,就是一个发展特别成功的NLP系统,那个ELIZA也是一个NLP的应用。
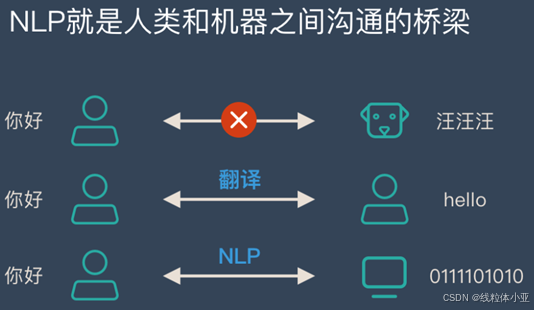
NLP ,简单来说,就是人类和机器之间沟通的桥梁。
因为叫自然语言处理,其中,这个自然语言就是大家平时在生活中常用的表达方式。意思就是平时说的「讲人话」。
举个例子:自然语言:我背有点驼 (非自然语言:我的背部呈弯曲状)。
一些NLP面临的问题的例子:
比如有两个句子:
“我们把香蕉给猴子,因为(它们)饿了”
“我们把香蕉给猴子,因为(它们)熟透了”
这两个句子有同样的结构。但是代词“它们”在第一句中指的是“猴子”,在第二句中指的是“香蕉”。如果不了解猴子和香蕉的属性,无法区分。
这就是NLP要解决的其中一个问题。
NLP 的2大核心任务:自然语言理解 和 自然语言生成。
自然语言理解 (NLU,Natural Language Understanding)
自然语言理解就是希望机器像人一样,具备正常人的语言理解能力,重在理解。具体来说,就是理解语言、文本等,提取出有用的信息,用于下游的任务。比如分词、词性标注、句法分析、文本分类、信息提取等等。
目前, NLU 是至今还远不如人类的表现。
自然语言生成(NLG,Natural Language Generation)
NLG就是要把非语言格式的数据(比如:文本、图表、音频、视频等)转换成人类可以理解的语言格式。
NLG又可以分为三大类:
文本到文本(text—to—text),如翻译、摘要等
文本到其他(text—to—other),如文本生成图片
其他到文本(other—to—text),如视频生成文本
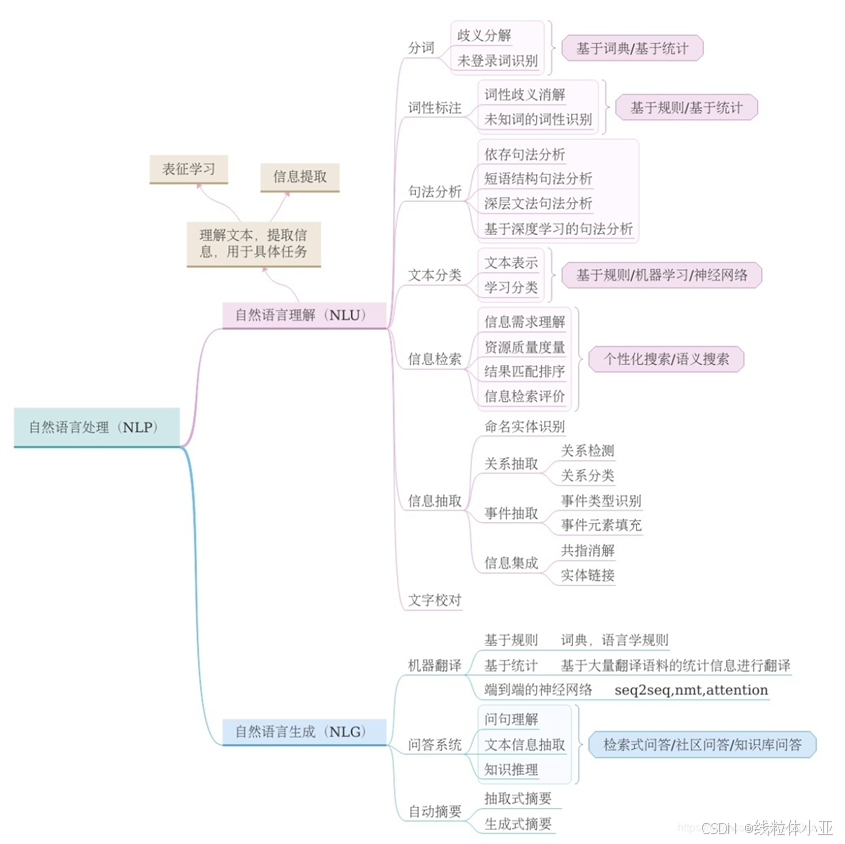
自然语言处理具体涉及的内容:
(1)分词 (Word Segmentation)
分词就是将句子等等比较长的文章,分解成以字词为单位的数据结构,为了方便后续的处理分析工作。
分词的方法大致分为 3 类:
基于词典匹配
基于统计
基于深度学习

(2)词性标注
词性标注(part of speech tagging):
词性就是词语的类别:例如:名词、动词、形容词等。
标注词性的原因就是:词性在很大程度上告诉了我们一个词的句法功能,和它周围可能出现的词。
比如:动词(verb)通常出现在名词(noun)后面。

(3)句法分析
句法分析就是分析句子的句法结构(主谓宾结构)和词汇间的依存关系(并列,从属等)。

(4)文本分类(Text categorization)
文本分类:就是按照一定的分类体系,自动标注类别。
文本分类的应用场景很多,比如:
1. 新闻主题分类(文章分类):根据文章内容,给新闻等其他文章一个类别,比如财经、体育、军事、明星等等。
2. 情感分析:比如他是正面情绪、负面情绪、还是中性情绪。一般在影评(比如豆瓣、淘票票)、商品评价(比如淘宝、京东的商品评价)等用的比较多。
3. 舆情分析:和情感分类类似,政府或者金融机构用的比较多。
4. 邮件过滤:比如判断一封邮件是不是垃圾邮件。
(5)信息检索 (Information Retrieval)
从存储在计算机中的文本中,找到满足信息需求的材料。
信息检索的应用领域:网页搜索,邮件搜索等等。
(6)信息抽取 (Information Extraction)
信息抽取就是从文本中,抽取出特定的事件或信息,可以帮助我们把内容进行自动分类、提取和重构。这些信息通常包括实体(entity)、关系(relation)、事件(event)。
比如:从体育新闻中抽取体育赛事信息:主队、客队、赛场、比分等。
从医疗文献中:抽取疾病信息:病因、病原、症状、药物等。
信息抽取是中文信息处理和人工智能的基础核心技术。
(7)文本校对 (Text-proofing)
文本校对就是对文本进行检测和修复。
采用的技术包括应用词典和语言模型等。
(8)问答系统 (Question Answering)
自动问答:就是对于人们用自然语言提出的问题,计算机可以自动地给出答案或者答案列表。
自动问答是自然语言处理领域的一个非常重要研究方向。
到目前为止,最著名的问答系统就是刚才讲的IBM的沃森系统。
(9)机器翻译 (Machine Translation)
机器翻译产生的原因之一就是,语言障碍在一定程度上,制约了全球化的发展。
机器翻译涉及了计算机科学、语言学、数学和其他别的学科,具有重要的科学意义。
机器翻译不是一种NLP的方法,而是一种NLP的应用。
第一个机器翻译的项目就是之前文章里的,1954 年 ,美国乔治城大学与 IBM 公司合作的项目。
(10)自动摘要 (Automatic Summarization)
自动摘要:就是用计算机把大量的文本进行处理,然后产生更简洁、精炼内容。
自动摘要目前有提取(Extraction)和抽象(Abstraction)两种方法。
1. 提取:是通过提取文档中已存在的关键词,形成摘要。
2. 抽象:通过建立抽象的语意表示,使用自然语言生成技术,形成摘要。
目前主流是采用基于抽取式的方法,因为这个方法比较容易实现。
5. 网络安全
网络安全包括反垃圾邮件、反网络钓鱼、上网内容过滤、反诈骗等等。
然后,机器学习在网络安全领域的应用,比较常见的3个就是:
-
垃圾邮件检测
-
入侵检测
-
恶意软件检测

垃圾邮件检测:
机器学习一直都是垃圾邮件检测的重要组成部分,有很多早期的机器学习方法现在还在使用。
具体的方法比如,从邮件提取一些技术细节(如:IP地址和服务器信息等等)。
或者是,建立垃圾邮件分类器。
或者是,使用深度学习模型,来确定含有品牌的电子邮件,是不是来自真实的公司。
入侵检测:
从表格可以看出来,机器学习在入侵检测领域历史也很悠久,涵盖很多方面。在二十多年的研究过程中,不同的机器学习方法也已经适用于多种类型的入侵检测。
恶意软件检测:
恶意软件检测系统:就是检查特定文件,来确定它们是不是恶意的。
具体的应用比如:1996年,IBM的研究人员使用神经网络,对引导扇区病毒(这是一种针对机器启动指令的特殊类型病毒)进行分类。
6. 工业领域
机器学习在工业领域的应用:主要在质量管理、灾害预测、缺陷预测、故障感知等方面。
具体的应用比如:用工业机器人来实现全自动化。
特斯拉(Tesla)的智能工厂,它们公司的生产线,都是由工业机器人完成,并且他们的仓储、物资管理、订单与销售环节都是高度智能化的。

机器学习在工业领域遇到困难的就是:
1. 数据质量的问题:其实就是 “垃圾进,垃圾出” 的问题,差的数据质量,也会导致差的模型。
2. 工程师经验:因为要了解机器学习的相关算法和方法是有一定的门槛。
3. 计算能力:机器学习对计算资源 (GPU)要求越来越高。
4. 机器学习的不可解释性:就是有些算法是很容易给外行的人解释的(比如:决策树,是可以可视化的)。但是有些复杂的算法,很难用语言或者可视化的方式进行解释。
7. 机器学习在娱乐行业的应用
Cinelytic
有一个美国的公司,Cinelytic,这个公司有很多电影的历史数据。
所以他们能做到的就是把电影主题和关键演员的信息进行交叉引用,然后用机器学习来梳理数据中的隐藏模式。
这个软件就可以让用户,输入想要的演员阵容,然后将一个演员换成另一个演员,然后就可以看到换不同的演员是怎么影响电影的预计票房。他们的票房预测模型准确率为是85%。
他们公司的重点业务就是,帮助导演等专业人士,更好的选角和营销他们的电影。

Valossa
Valossa是一个视频分析平台。
这个平台还可以自动从视频内容中提取亮点。比如:分析视频信息,根据行动、重要人物、活动来识别视频里的亮点。
这个平台还会检查视频文件,并且可以对每个已经识别的人、物体、场景和音频声音进行索引。然后你就可以使用索引还查找对应的视频片段。比如:你拍摄了一段吃饭的视频,但是你忘了具体这段视频是在你的影片的哪一个时间点上,这个视频索引功能就可以很方便的帮助你查找片段。
广告计划管理器
IRIS.TV公司开发了一个工具叫:广告计划管理器(Campaign Manager)。可以让观众在视频停留的时间更长。
基本上,这个软件就是帮助视频平台实现内容精准分发,然后提升视频播放次数。


















 2256
2256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









