







随着ChatGPT的迅速出圈,加速了大模型时代的变革。对于以Transformer、MOE结构为代表的大模型来说,传统的单机单卡训练模式肯定不能满足上千(万)亿级参数的模型训练,这时候我们就需要解决内存墙和通信墙等一系列问题,在单机多卡或者多机多卡进行模型训练。
最近,我也在探索大模型相关的一些技术,下面做一个简单的总结,后续争取每一个季度更新一次,目前最新更新为2023.07.03,本文主要涉及AI集群、AI集群通信、大模型训练(参数高效微调)、大模型推理加速、大模型评估、大模型生态相关技术等相关内容,同时,也对之前写过的一些大模型相关的文章进行了汇总,文档及配套代码均整理并放置在GitHub: llm-action,篇幅太长,建议先收藏后再阅读。

AI 集群
由于目前只有3台A800 GPU服务器(共24卡),基于目前现有的一些AI框架和大模型,无法充分利用3台服务器。比如:OPT-66B一共有64层Transformer,当使用Alpa进行流水线并行时,通过流水线并行对模型进行切分,要么使用16卡,要么使用8卡,没法直接使用24卡,因此,GPU服务器最好是购买偶数台(如:2台、4台、8台)。
具体的硬件配置如下:
- CPUs: 每个节点具有 1TB 内存的 Intel CPU,物理CPU个数为64,每颗CPU核数为16。
- GPUs: 24 卡 A800 80GB GPUs ,每个节点 8 个 GPU(3 个节点)。

目前使用Huggingface Transformers和DeepSpeed进行通过数据并行进行训练(pretrain),单卡可以跑三百亿参数(启用ZeRO-2或ZeRO-3),如OPT-30B,具体训练教程参考官方样例。
使用Alpa进行流水线并行和数据并行进行训练(fine tuning)时,使用了3台共24卡(PP:12,DP:2)进行训练OPT-30B,具体训练教程参考官方样例。但是进行模型训练之前需要先进行模型格式转换,将HF格式转换为Alpa格式的模型文件,具体请参考官方代码。如果不想转换,官网也提供了转换好的模型格式,具体请参考文档:Serving OPT-175B, BLOOM-176B and CodeGen-16B using Alpa。

20230703:前几天对H800进行过性能测试,整体上来说,对于模型训练(Huggingface Transformers)和模型推理(FasterTransformer)都有30%左右的速度提升。但是对于H800支持的新数据类型FP8,目前很多开源框架暂不支持,虽然,Nvidia自家一些开源框架支持该数据类型,目前不算太稳定。

AI处理器(加速卡)-新增(2023.06.30)
目前,主流的AI处理器无疑是NVIDIA的GPU,NVIDIA的GPU产品主要有GeForce、Tesla和Quadro三大系列,虽然,从硬件角度来看,它们都采用同样的架构设计,也都支持用作通用计算(GPGPU),但因为它们分别面向的目标市场以及产品定位的不同,这三个系列的GPU在软硬件的设计和支持上都存在许多差异。其中,GeForce为消费级显卡,而Tesla和Quadro归类为专业级显卡。GeForce主要应用于游戏娱乐领域,而Quadro主要用于专业可视化设计和创作,Tesla更偏重于深度学习、人工智能和高性能计算。
- Tesla:A100(A800)、H100(H800)、A30、A40、V100、P100…
- GeForce:RTX 3090、RTX 4090 …
- Quadro:RTX 6000、RTX 8000 …
其中,A800/H800是针对中国特供版(低配版),相对于A100/H100,主要区别:
- A100的Nvlink最大总网络带宽为600GB/s,而A800的Nvlink最大总网络带宽为400GB/s。
- H100的Nvlink最大总网络带宽为900GB/s,而A800的Nvlink最大总网络带宽为400GB/s。
其他的一些国外AI处理器(加速卡):
- AMD:GPU MI300X
- Intel:Xeon Phi
- Google:TPU
国产AI处理器(加速卡):
- 华为:昇腾910(用于训练和推理),昇腾310(用于推理)。采用自家设计的达芬奇架构。
- 海光DCU:8100系列(深算一号),以GPGPU架构为基础。
- 寒武纪:思元370、思元590。
- 百度:昆仑芯,采用的是其自研XPU架构。
- 阿里:含光800。
大模型算法
模型结构:
目前主流的大模型都是Transformer、MOE结构为基础进行构建,如果说Transformer结构使得模型突破到上亿参数量,MoE 稀疏混合专家结构使模型参数量产生进一步突破,达到数万亿规模。
大模型算法:
下图详细展示了AI大模型的发展历程: 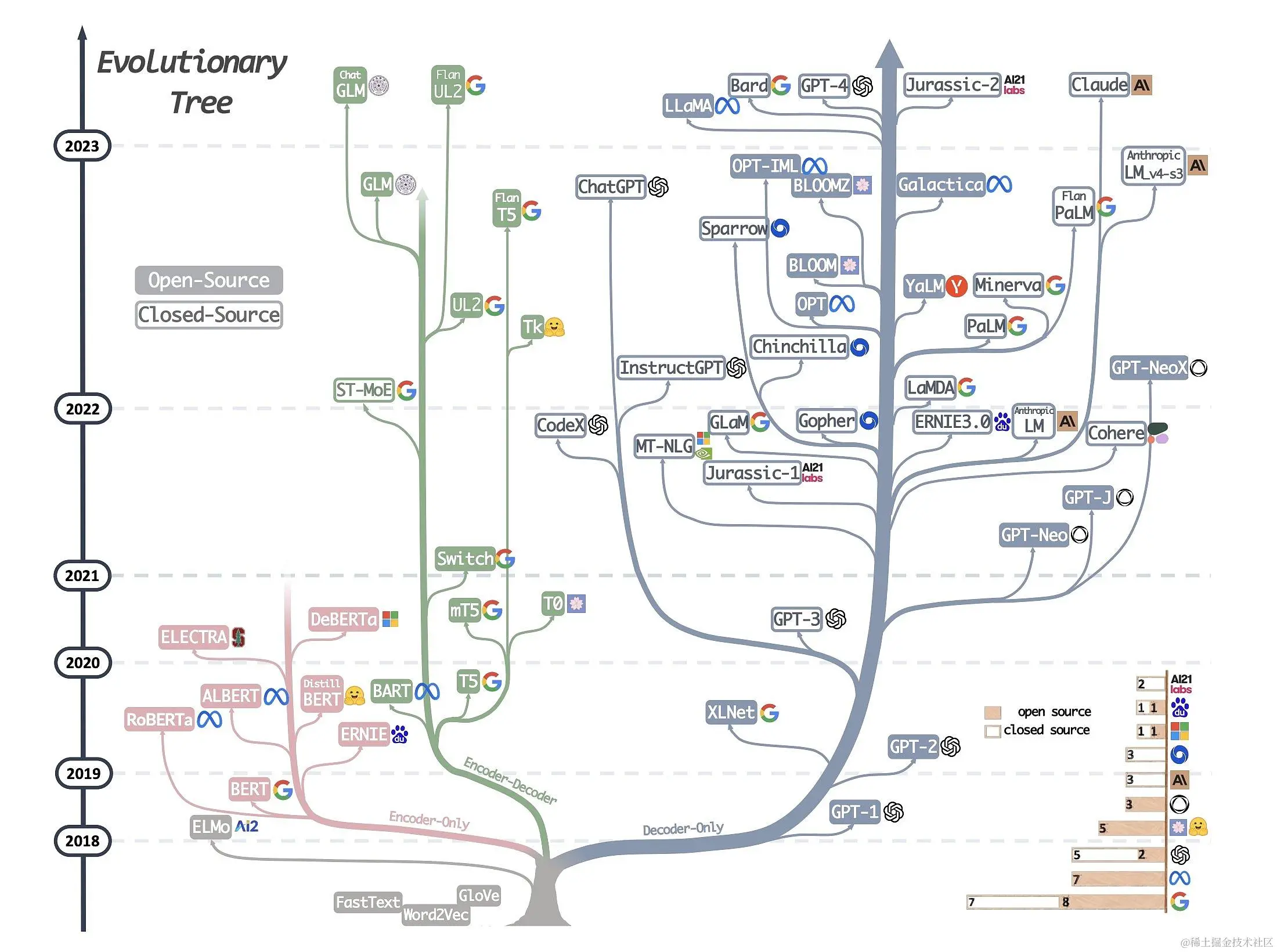
可以说,Transformer 开创了继 MLP 、CNN和 RNN之后的第四大类模型。而基于Transformer结构的模型又可以分为Encoder-only、Decoder-only、Encoder-Decoder这三类。
- 仅编码器架构(Encoder-only):自编码模型(破坏一个句子,然后让模型去预测或填补),更擅长理解类的任务,例如:文本分类、实体识别、关键信息抽取等。典型代表有:Bert、RoBERTa等。
- 仅解码器架构(Decoder-only):自回归模型(将解码器自己当前步的输出加入下一步的输入,解码器融合所有已经输入的向量来输出下一个向量,所以越往后的输出考虑了更多输入),更擅长生成类的任务,例如:文本生成。典型代表有:GPT系列、LLaMA、OPT、Bloom等。
- 编码器-解码器架构(Encoder-Decoder):序列到序列模型(编码器的输出作为解码器的输入),主要用于基于条件的生成任务,例如:翻译,概要等。典型代表有:T5、BART、GLM等。
大语言模型
目前业界可以下载到的一些大语言模型:
- ChatGLM-6B / ChatGLM2-6B :清华开源的中英双语的对话语言模型。目前,第二代ChatGLM在官网允许的情况下可以进行商用。
- GLM-10B/130B :双语(中文和英文)双向稠密模型。
- OPT-2.7B/13B/30B/66B :Meta开源的预训练语言模型。
- LLaMA-7B/13B/30B/65B :Meta开源的基础大语言模型。
- Alpaca(LLaMA-7B):斯坦福提出的一个强大的可复现的指令跟随模型,种子任务都是英语,收集的数据也都是英文,因此训练出来的模型未对中文优化。
- BELLE(BLOOMZ-7B/LLaMA-7B/LLaMA-13B):本项目基于 Stanford Alpaca,针对中文做了优化,模型调优仅使用由ChatGPT生产的数据(不包含任何其他数据)。
- Bloom-7B/13B/176B:可以处理46 种语言,包括法语、汉语、越南语、印度尼西亚语、加泰罗尼亚语、13 种印度语言(如印地语)和 20 种非洲语言。其中,Bloomz系列模型是基于 xP3 数据集微调。 推荐用于英语的提示(prompting);Bloomz-mt系列模型是基于 xP3mt 数据集微调。推荐用于非英语的提示(prompting)。
- Vicuna(7B/13B):由UC Berkeley、CMU、Stanford和 UC San Diego的研究人员创建的 Vicuna-13B,通过在 ShareGPT 收集的用户共享对话数据中微调 LLaMA 获得。其中,使用 GPT-4 进行评估,发现 Vicuna-13B 的性能在超过90%的情况下实现了与ChatGPT和Bard相匹敌的能力;同时,在 90% 情况下都优于 LLaMA 和 Alpaca 等其他模型。而训练 Vicuna-13B 的费用约为 300 美元。不仅如此,它还提供了一个用于训练、服务和评估基于大语言模型的聊天机器人的开放平台
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









