






二十四年前,著名表演艺术家宋丹丹老师在显像管电视里对全国观众提出了一个经典的「还原主义」哲学思考:
想把大象装冰箱,一共分几步?
二十四年后,一群开发者面对着 mini-LED 屏幕,让由成百上千亿个参数组成的大模型解释出了这个「幽默的谜语」:

而对于这些开发者,除了让大模型解释脑筋急转弯外,面对名字一个比一个长的大模型,也有着属于 Ta 们自己的「大象与冰箱问题」——
想看懂大模型的名字,一共分几步?
看不懂的大模型名称
互联网时代,开发者们所使用项目和软件的命名突出一个简洁、优雅、易读,相信看到这里你的脑海里一定会蹦出那么几个十分具有代表性的名字,它们之中有的甚至一旦超过两个单词就会被嫌弃名字太复杂。
而在今天,当你看到一个叫做CLIP-ViT-H-14-laion2B-s32B-b79K的模型时,甚至不会觉得惊讶,反而会觉得这个模型是不是还有点别人不会的新本事。
如果按今天大模型的命名规则去命名曾经的项目,那你可能会看到诸如Node-V8JS-ECMAScript-macOS-v10.8.1这样的项目(虽然好像确实还挺直观)。

大模型的参数真的如此之大,大到起名也要搞的如此复杂吗?相信大家在刚接触大模型时会产生同样的疑惑:
各个大厂都是怎么给大模型起名字的?
我该怎么从名字里看懂这个模型是干嘛的?
如果我做了一个大模型,我该怎么给它起名字?
在研究了 Gitee AI 上一万多个大模型后,马建仓终于对大模型命名的学问有了粗浅的认识,如果你正巧刚进入 AI 领域,相信下面的内容一定可以帮你从名字上就看透一个模型有多大本事。
真的有必要这么长吗
通常来说,大模型的名字包含了名称及后缀两部分,通常以名称+后缀的方式结合在一起作为一个大模型的名字。
名称的部分告诉用户我是谁,再通过各种不同的后缀来表明更详细的身份信息,那么我们先从名称看起。
名称篇
大模型的名称往往是各大厂商最各显神通的部分,抽象的具象的,文艺的技术的,按照命名的方式,可以大致将它们分为以下两个派别:
技术派
一些大模型的名称源自不同的技术术语或技术概念,在起名的时候干脆直接把技术名称拿来当模型名。
例如大家最熟知的GPT就是Generative Pre-trained Transformer的缩写,这串术语的大义是生成式预训练 Transformer 模型。
再如谷歌团队 2018 年发布的BERT模型,它的名称也来自与采用的技术:Bidirectional Encoder Representations from Transformers,可以理解为基于 Transformers 的双向编码器表征技术。
著名的文生图模型Stable Diffusion的名字也是来自于深度学习模型中的「扩散模型」(Diffusion Model)。

GPT 和 BERT
此外,国产模型ChatGLM中的 GLM,是Generative Language Model的缩写,文心一言的英文名ERNIE Bot中的 ERNIE,则是Enhanced Representation through Knowledge Integration的缩写。
令人忍俊不禁是,Bert 和 Ernie 刚好也是儿童节目《芝麻街》当中一对好基友的名字,不知道百度起这个名字是否是为了再续和谷歌的缘分而有意为之呢?

芝麻街中的 Bert(右)和 Ernie
象征派
与简单粗暴的技术缩写相对应的,是相对更抽象的象征派。这些模型会使用具有象征意义的词汇作为名称,通常与智慧、理解、创造等相关,如 Anthropic 的Claude,就致敬了美国数学家、密码学家、信息论奠基人克劳德·香农博士(Claude Shannon)。

克劳德·香农博士
还有 OpenAI 的文生图模型DALL·E,它的名字就结合了西班牙超现实主义画家萨尔瓦多·达利(Salvador Dalí)和 2008 年的动画《机器人总动员》的角色瓦力(WALL·E),达利代表了艺术和幻想,WALL·E 代表了机器和未来。

达利和 WALL·E
曾经名噪一时的「阿尔法狗」AlphaGo,其中 Go 则是日文「碁」字发音转写,这也是是围棋的西方名称。
当然,现在的大模型多如牛毛,它们的名称也绝不会局限于这两类,如果你发现了新的起名派别,欢迎在评论区和大家分享。
后缀篇
相对于简单好记理解也不难的大模型名称,这些名称的后缀往往是真正令开发者们头疼的,毫无规律的字母和数字组合,后缀比命都长的各类信息,如何认识并分辨这些模型对于一个新入行的开发者无疑是巨大的挑战。
但耐下心来,经过比较和查阅,其实会发现大模型的后缀在多数情况下包含了以下几种信息:
参数数量
这是比较常见的后缀名之一,它们的名字中通常有 7B、175B、xB(x为数字)这样的后缀,这里它们通常代表参数的数量,单位是Billion(十亿)。
如下面的iFlytekSpark-13B模型,含义就是拥有 130 亿参数的讯飞星火开源模型。
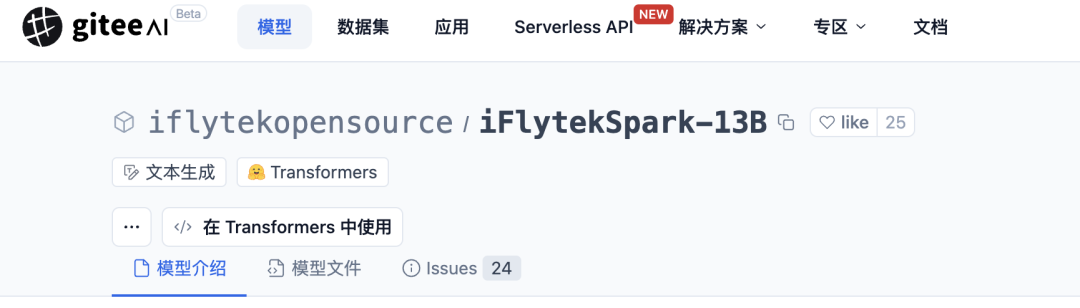
参数数量的大小直接影响了模型的性能和能力。较大的参数数量通常使模型能够学习和表达更复杂的信息,从而在各种任务中表现更优,同时也会带来计算资源需求增加、训练时间更长和潜在的过拟合风险。
因此,你可以根据自己的需求,从名字中就能看出模型的参数数量,从而快速找到满足自己需求的模型。
规模大小
除了用参数数量外,也有厂商使用更直观的英文单词来体现不同模型的规模和复杂性,如tiny、mini、base、large这样表示大小的词汇,能够让开发者更容易理解模型的规模和参数多少。

BERT-Base 和 BERT-Large 的参数区别
计算量和训练量
除了 xB 外,xext 也频繁地在一些模型的名字中出现,而这代表着模型的计算量和训练数据。
如下图中的stablelm-3b-4e1t模型,3B代表着其拥有 30 亿参数,4e1t则代表了不同的计量单位:

-
4e:指 4 Epochs(4 个 Epoch),意思是整个数据集被模型完整训练了 4 次。每个 Epoch 代表模型遍历整个数据集的一次完整过程。
-
1t:1 Trillion Tokens(1 万亿个 Tokens): 表示在训练中使用的 Token 的总数量。
所以4e1t的含义是,该模型是在包含 1 万亿个 Token 的数据集上,进行 4 次完整训练后得到的。
此外,有些大模型的名称中也会有INT4、INT6这样的描述,这代表了表示模型的权重和激活值被量化为 4 位整数或 6 位整数,这会影响模型的内存占用和资源需求。
版本号
版本号的概念就相对更容易理解,就是直接把版本号写在模型的名称里。
那么可能就有好奇宝宝问了,为什么大模型不能统一在一个项目下更新发布新版本呢?
事实上,不同于传统软件项目,大模型的版本更新通常不仅仅是简单的功能增强或修复,而是涉及多个核心方面的显著变化,这些变化对模型的性能、适用性以及实际应用都有重大影响。
如大家熟知的GPT-3.5-turbo就是GPT-3的一个显著改进版本,除了在基础架构上的优化外,GPT-3.5-turbo还在响应速度和计算资源的使用效率上进行了增强。这些改进使得GPT-3.5-turbo在处理复杂任务时表现得更加出色,也更适合需要高效计算的应用场景
模型的版本更新使它们在表达能力、训练数据广度和多样性上均有显著提升,导致不同版本之间的差异明显,因此直接在模型名称中标注版本号,能够清晰地传达这些变化,方便用户选择最合适的版本,而不是新版本出现后,老版本就被淘汰。
数据集语言
这也是个相对好理解的后缀,如Llama3-70B-Chinese-Chat就是首批专为中文微调的Llama3-70B模型之一。

所以,如果你在模型的名字中看到了某个国家或语言的缩写,那么它大概率是用这种语言(或包含该语言的数据集)训练的。
技术和方法
说到技术和方法类型的后缀,那可真就是八仙过海各显神通了,对开发者的知识储备也有了一定的要求。
比如 OpenAI 开发的clip-vit-large-patch14模型,如果没有一定的技术积累,你就很难直接从名字上看出来它是一个使用 Vision Transformer(名字中的 vit)架构的大型 CLIP 模型,并使用 14x14 像素的图像分块进行处理(名字中的 patch14)。
类似的例子还有很多,比如VAE代表Variational Autoencoder(变分自编码器,一种人工神经网络结构);Instruct通常表示模型经过Instruction Tuning(指令微调),意味着模型被优化用于更好地理解和执行明确的指令或任务描述;SFT则表示模型经过Supervised Fine-Tuning(监督式微调),优化了其在特定任务或领域的表现。
你看,没点知识储备,连大模型名字的解释都看不明白。以上这些例子也只是大模型技术中的冰山一角,更多内容还是要靠开发者们自己探索和学习了。

学吧,学无止境
当我们回过头来再看之前的问题:想看懂大模型的名字,一共分几步?
如果你看到这里,可能和马建仓有同样的答案:这比把大象装冰箱还要复杂一点。
确实,当我们在软件和互联网时代习惯了使用一个独立的名字然后详细分版本的命名方式后,再看大模型这样包含丰富信息的命名,虽然在有了一定程度了解后会觉得十分直观,但却并不怎么习惯。
如同英国科幻作家道格拉斯·亚当斯的科技三定律所说:
-
任何在我出生时已经有的科技,都是稀松平常的世界本来秩序的一部分。
-
任何在我 15-35 岁之间诞生的科技,都是将会改变世界的革命性产物。
-
任何在我 35 岁之后诞生的科技,都是违反自然规律,要遭天谴的。
在互联网时代,无数开发者从零开始,逐步掌握了前后端开发、数据库管理以及网络协议等关键技术,这些成为了构建和维护高效、可靠互联网应用与服务的基石。人们普遍认为,遵循这些技术规范和最佳实践是确保系统稳定性和安全性的必要条件,不容轻易违背或忽视。
然而,随着 AIGC 时代的到来,人类对于内容创作和信息处理的认知正在经历一场深刻的变革。AIGC 不仅展示了人工智能在自动化内容生成方面的巨大潜力,而且也促使我们重新评估现有的数据和信息的处理方法。这种转变就要求开发者们不断学习最新的理论与技术,以适应这一新兴领域所带来的机遇与挑战。
如果你想要成为躬身入局的开发者,那么就需要学习更基础的自然语言处理、生成对抗网络、向量数据库等等技术栈;但如果你只是想更好地利用大模型开发出更多有实用价值的应用,那么你就可以选择 Gitee AI 这样的平台,直接调用 Serverless API,省去十分耗费时间的本地搭建部署过程,让你更专注于发挥自己的想象力上。
总之,就如同辽北著名狠人范德彪先生所讲:学吧,学无止境,太深了,一个名字都有这么多学问,大模型要学的东西也太多了。

















 4048
4048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









