






一、多模态大模型快速发展****
1.1多模态是AI 大模型的新方向
多模态模型是指将不同类型的数据(例如图像、文字、视频、语音等)结合起来进行分析处理的模型。其通过不同数据类型的相互关联和结合,可以大幅提高模型的准确性和鲁棒性,应用场景进一步拓展。其次,多模态更接近人类学习的模式,在物理世界中,人类认知一个事物并不是通过单一模态,例如认知一只宠物,可以从视觉(宠物形貌)、听觉(宠物叫声)、嗅觉(宠物体味)、触觉(宠物毛发、宠物体温等)等多模态全面立体认知,是未来人工智能的发展方向。
1.2大模型开启新时代,多模态技术发展迅速。
2020 年大模型时代到来,多模态技术的发展得到进一步推进。大模型时代的核心在于构建能够处理海量数据的大规模模型,从而使得多模态模型在处理复杂任务时展现出了更高的性能和智能。最近,OpenAI 发布的GPT-4V 已经具备了强大的图片理解、逻辑推理以及情感感知能力,预计将在各产业得到广泛应用。
 GPT 大模型的发展历程
GPT 大模型的发展历程
1.3多模态模型五大方向:视觉理解、视觉生成、统一视觉、LLM 支持、多模态Agent
近期,微软多位研究员联合撰写文章,对多模态模型进行了全面的研究和分类,并关注了模型从专业性向通用性转变的特点。在模型分类中,研究员们将模型研究方向分为两大类五个主题:1)目前已成熟、完善的研究主题,包括包括视觉理解、视觉生成;2)具备探索性、开放性的前沿研究领域,包括统一视觉模型、受LLM(大语言模型)支持的多模态大模型以及多模态agent。
**方向一:视觉理解。**在AI 领域,视觉理解是指使计算机系统能够解释和理解视觉信息的能力。视觉理解的核心问题是通过预训练使得神经网络的主干架构backbone 获得强大的图像理解能力。模型训练方法可根据监督信号的不同分为三类:标签监督、语言监督和纯视觉自监督。其中,纯视觉自监督的监督信号来源为图像本身,相关方法有对比学习、非对比学习和掩码图像建模。在这些方法之外,常用的预训练方法还有多模态融合、区域级和像素级图像理解等。
**方向二:视觉生成。**这是AI 图像生成与理解的核心,不仅包括图像生成,还包括视频、3D 点云图等多种内容的生成。视觉生成不仅可以应用于艺术、设计等内容创作领域,它还在合成训练数据方面发挥着巨大作用,从而促进多模态内容理解与生成的闭环发展。视觉生成的重点在于如何生成与人类意图一致的图像,常见的四类相关研究方向为:有空间可控生成、基于文本再编辑、遵循文本提示生成和生成概念定制(concept customization)。当前研究趋势和未来短期研究方向是创建通用的文生图模型,以更好地满足人类意图,并提升上述方向的可替代性。
**方向三:统一视觉模型。**构建统一视觉模型具有多重挑战。在计算机视觉领域,各任务的差异很大,这为建立统一的视觉模型带来了巨大挑战:1)输入类型不同,输入内容可包括静态图形、动态视频、纯视觉输入、模糊图像等;2)不同的任务需要不同的粒度,如图像级任务、区域级任务、像素级任务等,因此输出的空间信息和语义信息也要求不同的格式;3)在建模之外,数据也有挑战,比如不同类型的标签注释成本差异很大,收集成本比文本数据高,这导致视觉数据的规模通常比文本语料库小得多。
未来统一视觉模型是非常有价值的研究方向。CV 领域对于开发通用、统一的视觉系统具有很高的兴趣,实现这一目标的关键研究方向包括:1)从闭集模型到开集模型,可以更好地将文本和视觉匹配;2)从特定任务到通用能力,减少新模型/垂直细分模型的开发成本;3)从静态模型到可提示模型。未来通用视觉模型应具备强大的上下文学习能力,因此LLM 可以接受不同语言和上下文提示作为输入,并生成用户所需的输出,无需微调。
**方向四:LLM 支持的多模态大模型。**该领域的代表作为OpenAI 的多模态模型GPT-4V,模型具备较强大的能力:1)模型具有强大的通用性能力,能够处理不同输入模态的任意组合,包括图像、子图像、文本、场景文本和视觉指针。2)经过详细测试,研究人员发现GPT-4V 支持LLM 中的test-time 技术,如指令跟随、思维链、上下文少样本学习等。3)GPT-4V 在多个实验领域表现接近人类水平的能力,包括开放世界视觉理解、视觉描述、多模态知识、常识、场景文本理解、文档推理、编码、时间推理、抽象推理、情感理解等。LLM 支持的多模态模型仍有部分领域需要改进和迭代,包括更多超越视觉和语言的模态(Multitask Instruct with Established Academic Datasets/Tasks)、多模态的上下文学习( Multimodal In-Context-Learning 、参数高效训练(Parameter-Efficient Training)以及Benchmark 等内容。
 LLM 支持的多模态大模型,典型案例为GPT-4V,可以识别图像并详细叙述
LLM 支持的多模态大模型,典型案例为GPT-4V,可以识别图像并详细叙述
**方向五:多模态增强智能体。**多模态增强智能体(LMM Powered Agents)是将不同的多模态专家模型同LLM 联系起来,进而解决复杂多模态理解问题的办法,也是目前最前沿的多模态研究方向。大语言模型(LLM) 具有对各领域用户提示的通用性特点,以及利用少量提示快速适应新场景的学习能力。受到这种强大能力的启发,研究人员正在探索一种新的模型范式,该范式不再是针对解决有限预定义问题的独立模型,而是通过将多个工具或专家与LLM 协同来解决复杂的开放性问题。与方向四不同,这样的系统可以在没有任何训练的情况下构建,只需使用少量提示训练LLM,使其对现有工具进行调用。整体而言,多模态智能体在多模态理解方面能力较强,并可轻松扩展到潜在的数百万种工具中。
二、多模态大模型的应用
多模态大模型逐步从专用转向通用,应用领域不断扩展。多模态模型的潜在价值日益凸显,模型所具备的跨感知理解与生成能力为各种应用提供了广阔的新领域。在代码生成、文本生成、图像生成、音视频/游戏等领域已有部分应用,未来多模态模型将赋能教育、办公、医疗、机器人等赛道。
2.1****文生图:图片生成是目前AIGC 领域相对成熟的方向,已经达到商用水平。
 文生图应用
文生图应用
2.2****音视频/游戏领域:该领域起步较晚,对模型复杂度和算力要求更高,未来市场空间巨大。
2.3****教育领域:可先建立通用教育大模型,并通过后续任务调整为多种多模态教育模型,如自动生成教学资源、支持人机协作,辅助教师教学智能模型。
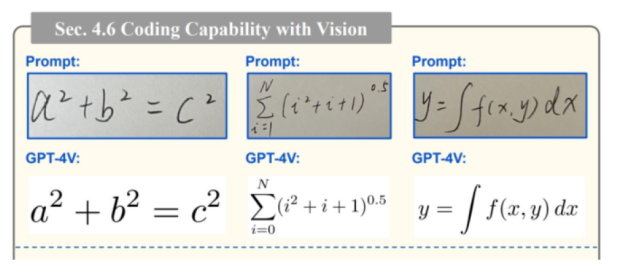 模型识别手写方程,可应用于教育领域
模型识别手写方程,可应用于教育领域
**2.4办公赛道:**多模态模型的语音识别与图像生成功能可以用于会议记录、语音识别、管理和制作多媒体内容等,为办公场景提供会议和协作支持、多媒体内容管理、文档自动化处理等。
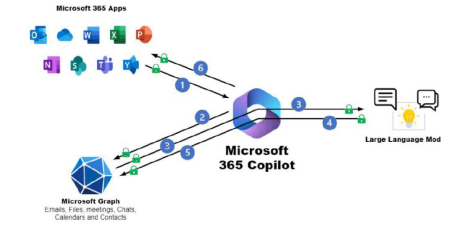
Microsoft 365 Copilot 为用户工作模式带来革命性变化
2.5遥感领域:多模态模型可用于对卫星图像、航空影像和其他遥感影像进行分类和解译,提供更全面、更精准的地理信息分析和环境监测能力。
 遥感图像处理
遥感图像处理
**2.6医疗领域:**多模态模型可以结合医学影像数据,如CT 扫描、MRI 和X 射线等,辅助医生进行疾病诊断和影像分析;还可用于医疗数据整合与分析、远程医疗咨询、个性化医疗方案定制等。
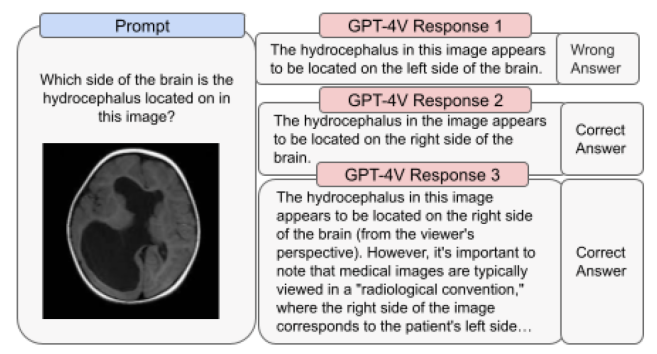 模型识别CT 影像,可应用于医疗领域
模型识别CT 影像,可应用于医疗领域
**2.7工业领域:**工业缺陷检测、安全检查等。工业缺陷检测。在制造业中计算机视觉技术发挥着至关重要的作用,缺陷检测是保证产品质量的一个重要步骤。
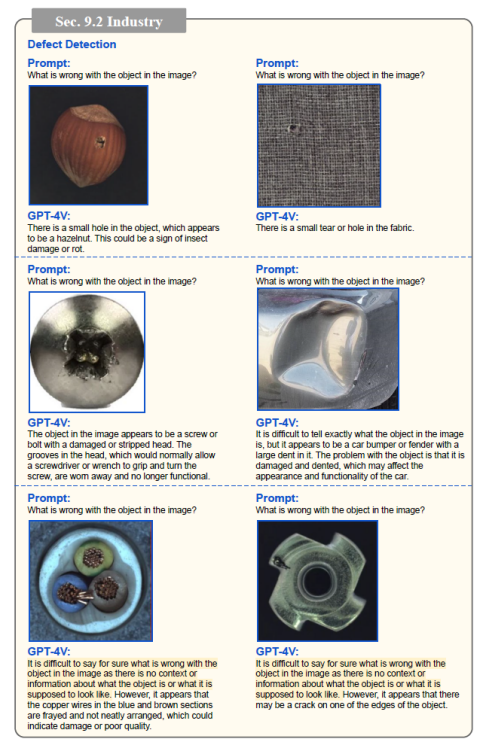
工业缺陷检测
安全检查。检测在建筑工地等工作环境中不充分使用或未穿戴个人防护设备(例如头盔、安全带和手套)的问题。
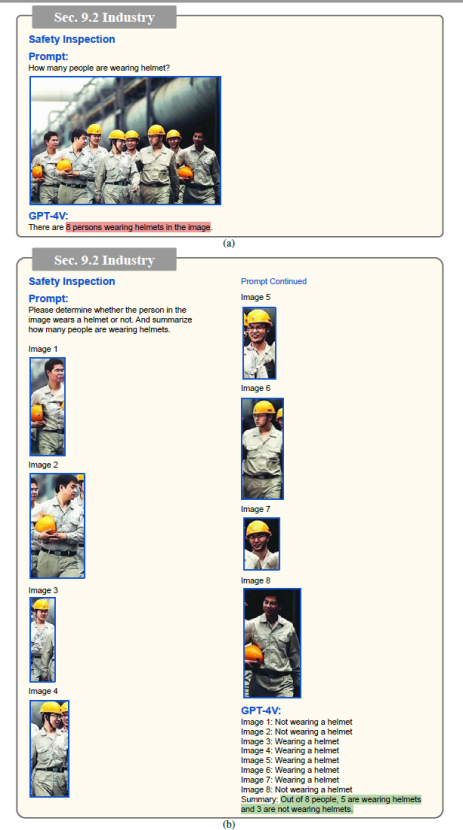
安全检查
**2.8机器人领域:**具身智能是基于物理身体感知和行动的智能系统。在大模型不断取得突破的背景下,科技大厂纷纷尝试将语言、视觉等模型嵌入机器人中,以帮助机器人处理复杂任务。
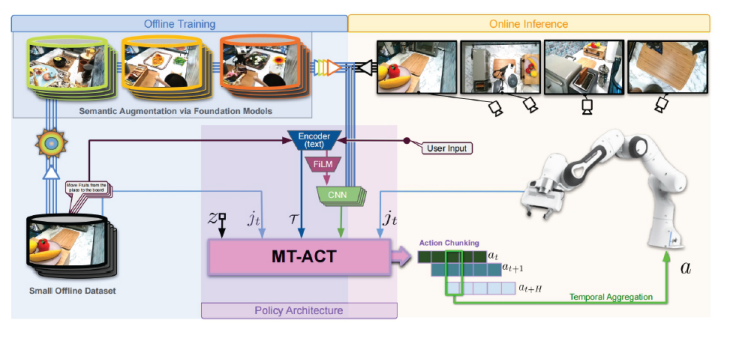
多模态大模型MC-ACT 赋能机器人,增强其通用性















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









