






我是跟着bilibili黑马程序员学习的,以下是我的学习笔记。
一、初识
4个步骤:创建项目、创建文件、编写代码、运行程序。
从祖传代码hello world开始
#include <iostream>//单行注释
using namespace std;
/*
多行注释
*/
int main()
{
cout<<"hello world"<<endl;
system("pause");
return 0;
}变量:方便我们管理内存空间
创建变量的语法:数据类型 变量名=初始值;
常量:2种表示方式
#define 常量名 常量值
const 数据类型 常量名=常量值
//第一种 宏常量
#define day 7
//第二种 const
const int day=7关键字:
起名字不能用关键字
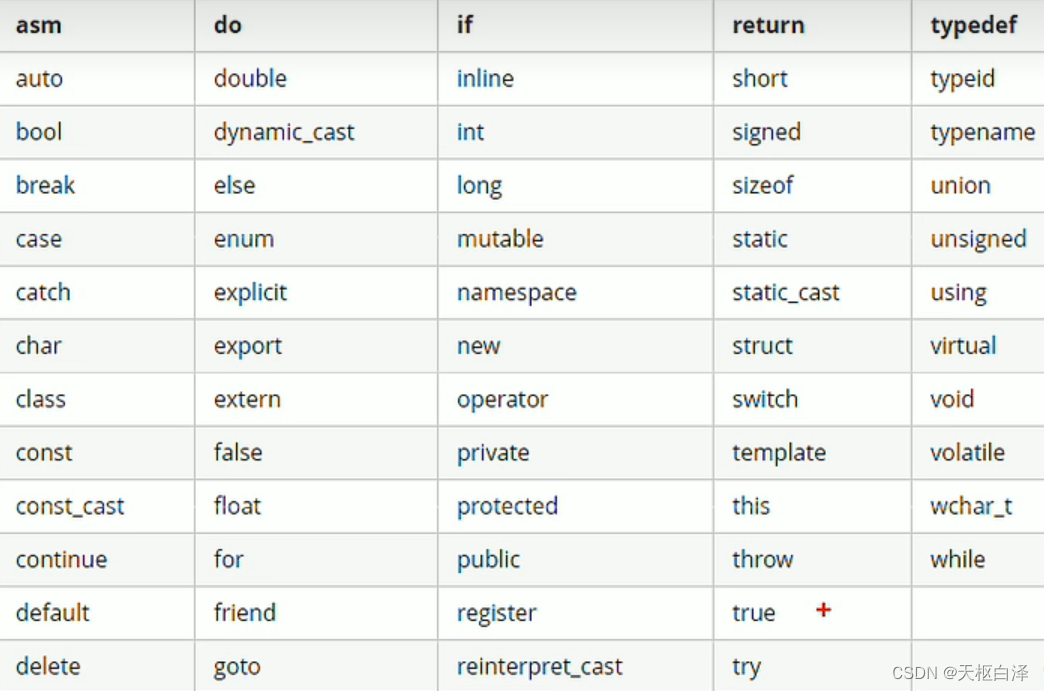
标识符命名规则:不能用关键字;由字母、数字、下划线组成;第一个字符不能为数字;区分大小写。
二.数据类型
整形:
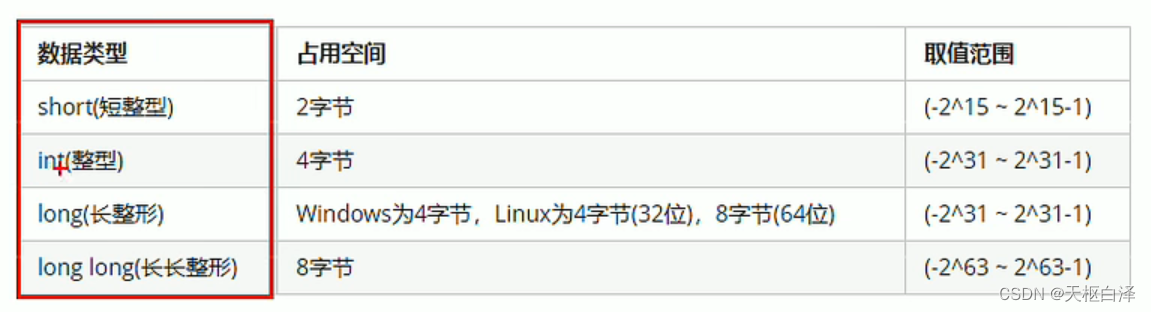
sizeof关键字:统计数据类型所占空间的大小
sizeof(数据类型/变量)
实型(浮点型):用来表示小数
就2种:单精度float和双精度double

科学计数法
float f=3e2; //3*10^2
字符型:显示单个字符
关键字:char(只占用一个字节)
注意:用单引号将字符括起来;单引号内是一个字符而不是字符串。
字符型变量只占用一个字节,将ASCII编码放入存储单元
字符型变量对应ASCII码:a-97,A-65,0-48
cout<<(int)ch<<endl;
强制类型转换:(数据类型)变量名;
转义字符:用来表示一些不能表示出来的ASCII字符
常用的是\n \\ \t
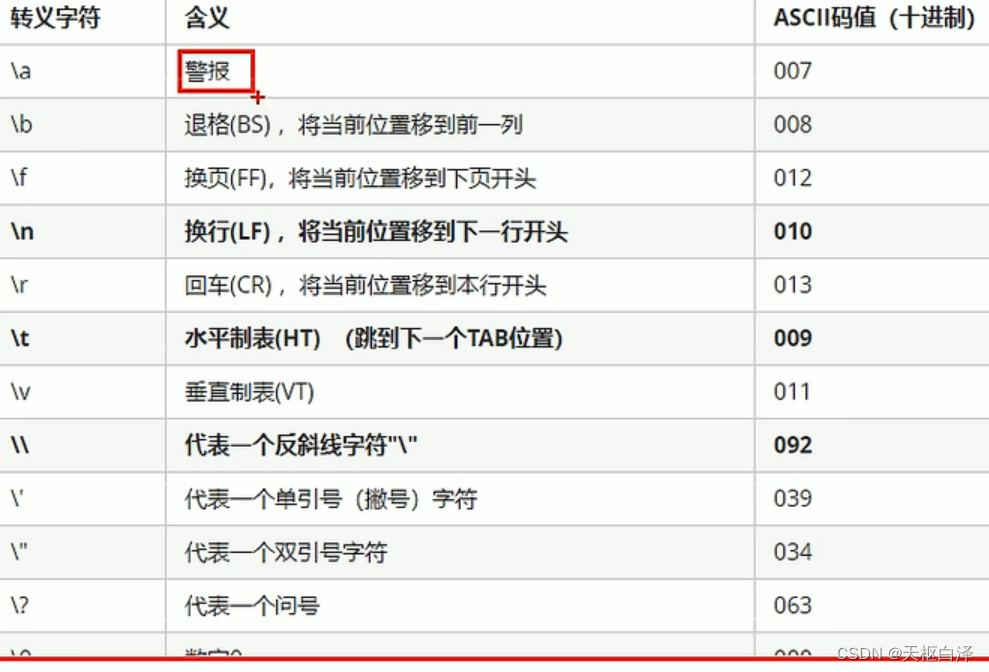
说一下\t
cout<<"aaaa\thelloworld"<<endl;//1
cout<<"aa\thelloworld"<<endl;//2
cout<<"aaaaaa\thelloworld"<<endl;//3结果如下:

所以,\t可以让后面的内容更整齐。
字符串型:用于表示一串字符
两种风格:
1.C风格
char 变量名 [] ="字符串值”
注意:要加中括号,记得双引号!
举例
#include <iostream>
using namespace std;
int main()
{
char str[]="hello world";
cout<<str<<endl;
return 0;
}2.C++风格
要包含头文件的!!!
#include <string>
语法:
string 变量名=“字符串值”
举例:
#include <iostream>
#include <string>//就是这个头文件!别忘!
using namespace std;
int main()
{
string std2="hello world";
cout<<std2<<endl;
return 0;
}布尔类型:代表真(1)、假(0)。占一个字节。非零值都为真。
bool flag=true;
cout<<flag<<endl;数据输入
cin>>变量
//整型如下
int a=0;
cin>>a;
//浮点型如下
float f=3.14f;
cin>>f;
//字符型如下
char ch='a';
cin>>a;
//字符串型如下
//记得#include <string>
string str="hello world";
cin>>str;
//布尔类型
bool flag=false;
cin>>flag;三.运算符
用于执行代码的运算
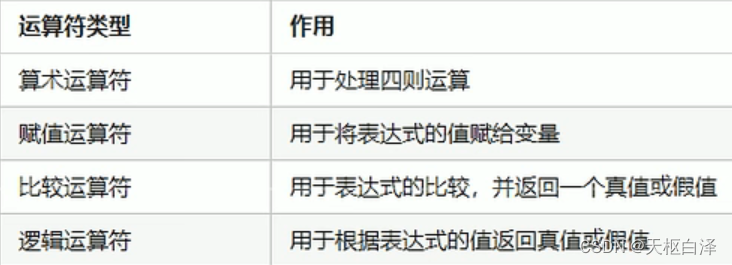
算术运算符

2个小数可以相除,运算结果也可以是小数。不能非法运算。取模不能用0。2个小数不能取模运算,只有整型变量才能取模运算。
前置递增:先+1,再运算表达式;后置递增;先运算表达式,再+1。
赋值运算符:
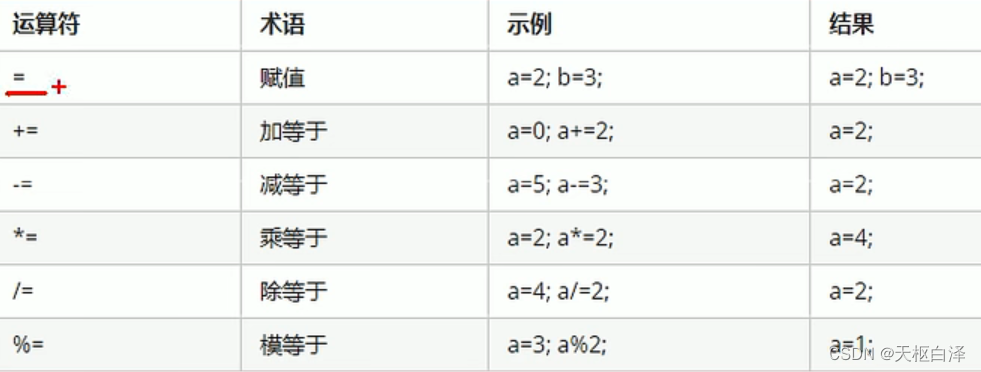
比较运算符:比较完之后返回一个真值或假值
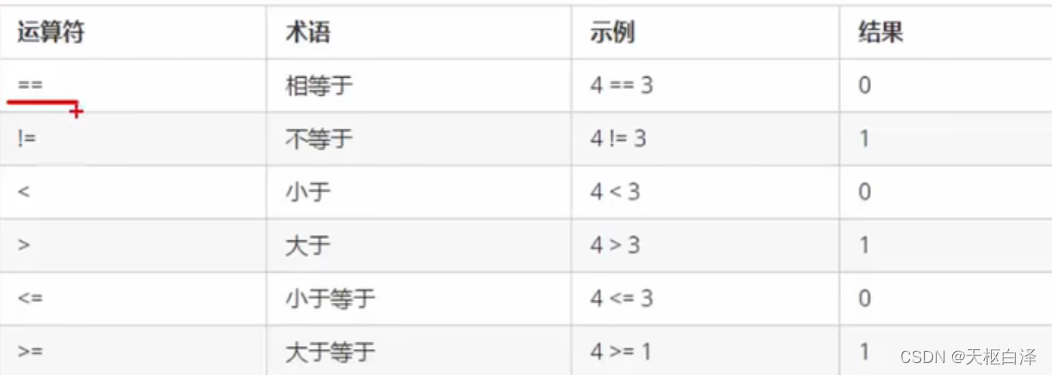
逻辑运算符: 根据表达式的值返回真值或假值

与 :同真为真,其余为 假
或:同假为假,其余为 真
四.程序流程结构
顺序结构、选择结构、循环结构
1.选择结构
if语句
单行格式if语句
if(条件){条件满足执行的语句};
if条件后面不要加分号!!!否则,不管是否满足条件,大括号里面的代码都会执行。那你不就白写了嘛!
多行格式if语句
if(条件){条件满足执行的语句} else{条件不满足执行的语句};
多条件的if语句
if(条件1){满足条件1执行的语句} else if (条件2){满足条件2执行的语句}......else{都不满足执行的语句}
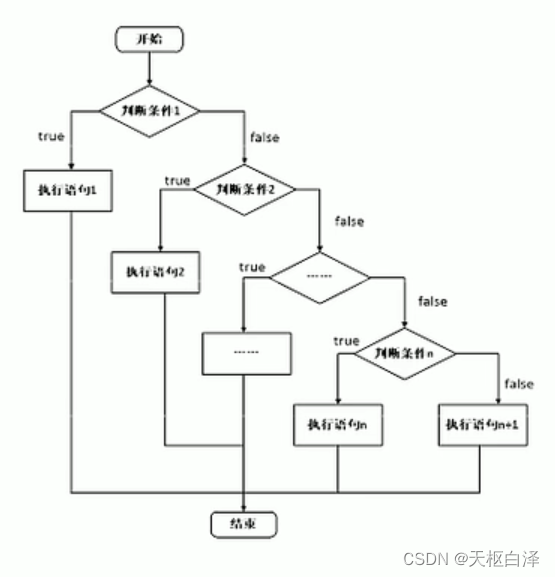
嵌套if语句,比较三个数的大小,自己试敲。
三目运算符:
表达式1?表达式2:表达式3;
符合表达式1执行表达式2,不符合表达式1执行表达式3。也可以进行赋值操作。
switch语句:执行多条件分支语句。
缺点:判断时只能是整型或字符型,不能是区间。
注意:没有break,会从入口一直向下执行
switch(表达式)
{
case 1 结果1:执行语句;break;
case 2 结果2:执行语句;break;
......
dafault:执行语句;break;
}
举个例子(doge)
int score;
cin>>score;
switch(score)
{
case 5:
cout<<"狠狠表扬你";
break;
case 4:
cout<<"表扬你但不会狠狠";
break;
case 3:
cout<<"有饭吃";
break;
case 2:
cout<<"家法伺候";
break;
case 1:
cout<<"是亲生的咩";
break;
}
2.循环结构
while循环结构
while(循环条件){循环语句}
条件为真,执行循环语句
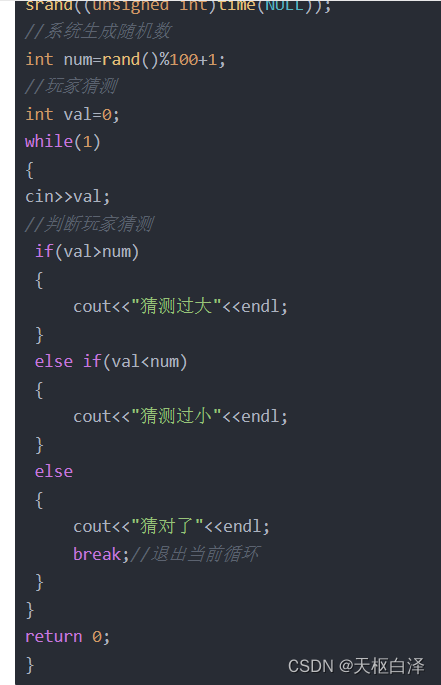
例子:猜数字
#include <iostream>
using namespace std;
//time系统时间头文件的包含
#include <ctime>
int main()
{//添加随机数种子,用当前系统时间生成随机数,防止每次随机数都一样
srand((unsigned int)time(NULL));
//系统生成随机数
int num=rand()%100+1;
//玩家猜测
int val=0;
while(1)
{
cin>>val;
//判断玩家猜测
if(val>num)
{
cout<<"猜测过大"<<endl;
}
else if(val<num)
{
cout<<"猜测过小"<<endl;
}
else
{
cout<<"猜对了"<<endl;
break;//退出当前循环
}
}
return 0;
}do...while循环语句
do{循环语句} while(循环条件);
至少执行一次
举例:水仙花数(指一个三位数,它每个位上的数字的3次幂之和等于它本身)如1*1*1+5*5*5+3*3*3=153
#include <iostream>
using namespace std;
int main()
{
//打印所有三位数字
int num=100;
do
{
//先从从所有三位数字中找到找水仙花数
int a=0;
int b=0;
int c=0;
a=num%10;//个位
b=num/10%10;//十位
c=num/100;//百位
if(a*a*a+b*b*b+c*c*c==num)//只打印水仙花数
{
cout<<num<<endl;
}
num++;
}while(num<1000);
system("pause");
return 0;
}for循环:满足循环条件,执行循环语句。
for(起始表达式;条件表达式;末尾循环体){循环语句;}
例子:
#include <iostream>
using namespace std;
int main()
{
for(int i=0;i<10;i++)
{
cout<<i<<endl;
}
system("pause");
return 0;
}注意:for循环表达式中,用分号隔开。
举例:敲桌子(从1数到100,如果数字个位有7或十位有7或该数字是7的倍数,打印敲桌子,其余数字直接打印输出)
//先输出1到100
//找到特殊数字,改为“敲桌子”
#include <iostream>
using namespace std;
int main()
{
for(int i=1;i<=100;i++)//遍历
{
if(i%10==7||i/10%10==7||i%7==0)//条件
{
cout<<"敲桌子"<<endl;
}
else
{
cout<<i<<endl;
}
}
system ("pause");
return 0;
}嵌套循环:顾名思义,不多解释。
举例:星星图
#include <iostream>
using namespace std;
int main()
{
for(int j=0;j<10;j++)//10行
{
for(int i=0;i<10;i++)//一行
{
cout<<"* ";
}
cout<<"*"<<endl;
}
system("pause");
return 0;
}效果如下:

外层执行一次,内层执行一周
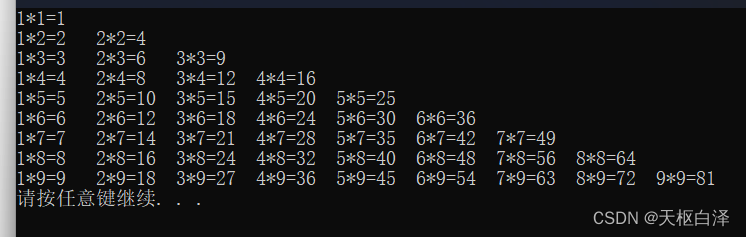
举例进阶:乘法口诀表
//列数*行数=计算结果且列数<=当前行数
#include <iostream>
using namespace std;
int main()
{
for(int i=1;i<=9;i++)//行循环
{
for(int j=1;j<=i;j++)//行内循环 一行
{
cout<<j<<"*"<<i<<"="<<i*j<<"\t";
}
cout<<endl;
}
system("pause");
return 0;
}
效果如下:
3.跳转语句
break语句:用于跳出选择结构或循环结构
3个使用时机:(1)在switch语句中,终止case并跳出switch;(2)循环语句中,跳出当前循环语句;(3)嵌套循环中,跳出最近的内层循环语句。
switch和循环在前面选择结构循环结构那里说过了,不再赘述。(截图放这)

continue语句:在循环语句中,跳过本次循环中尚未执行的语句,继续执行下一次循环。
#include <iostream>
using namespace std;
int main()
{
for(int i=0;i<=100;i++)
{//奇数不输出,偶数输出
if(i%2==0)
{
continue;
}
cout<<i<<endl;
}
system ("pause");
return 0;
}作用:可以筛选条件,执行到此就不再向下执行,执行下一次循环。break会退出循环,continue不会。
goto语句:无条件跳出代码
goto 标记;
如果标记的名称存在,执行到goto语句时,会跳转到标记的位置。
虽然很方便,但是影响代码结构。平时少用。如非必要。
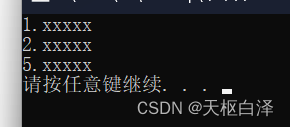
cout<<"1.xxxxx"<<endl;
cout<<"2.xxxxx"<<endl;
goto flag;
cout<<"3.xxxxx"<<endl;
cout<<"4.xxxxx"<<endl;
flag:
cout<<"5.xxxxx"<<endl;输出结果:
五.数组
特点:每个数据元素的数据类型相同,由连续的内存位置组成(连续的内存空间)。
注意:下标是从0开始的
1.一维数组
3种定义方式:
数据类型 数组名 [数组长度];
数据类型 数组名 [数组长度]={值1,值2,......};
数据类型 数组名 [ ]={值1,值2,......};
//第一种
int arr[5];
//给数组中的元素赋值
arr[0]=10;
arr[1]=20;
arr[2]=30;
arr[3]=40;
arr[4]=50;
//访问数组元素
cout<<arr[0]<<endl;
cout<<arr[1]<<endl;
cout<<arr[2]<<endl;
cout<<arr[3]<<endl;
cout<<arr[4]<<endl;
//第二种
//在初始化的时候,如果没有全部填写完,用0来填补剩余数据
int arr2[5]={10,20,30,40,50};
/*
cout<<arr2[0]<<endl;
cout<<arr2[1]<<endl;
cout<<arr2[2]<<endl;
cout<<arr2[3]<<endl;
cout<<arr2[4]<<endl;
*/
//利用循环 输出数组中的元素
for(int i=0;i<5;i++)
{
cout<<arr2[i]<<endl;
}
//第三种 定义数组的时候,必须有初始长度
int arr3[]={90,80,70,60,50,40,30,20,10};
for(int i=0;i<10;i++)
{
cout<<arr3[i]<<endl;
}数组名和变量名不要重名。
一维数组名称用途:可以统计数组在内存中的长度;获取数组在内存中的首地址。(用好sizeof)
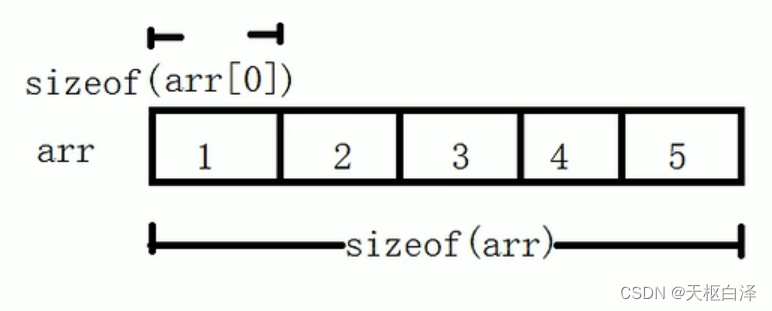
int arr[]={1,2,3,4,5,6,7,8,9,10}
cout<<“数组的长度为”<<sizeof(arr)<<endl;
cout<<“数组首地址长度为”<<sizeof(arr[0])<<endl;
cout<<“数组中元素的个数为”<<sizeof(arr)/sizeof(arr[0])<<endl;
cout<<“数组首地址为”<<arr<<endl;
//或者用十进制 cout<<“数组首地址为”<<(int)arr<<endl;
//这个也可cout<<“数组中第一个元素的首地址为”<<&arr[0]<<endl;举例1:在数组中找最大值
#include <iostream>
using namespace std;
int main()
{
int arr[5]={300,350,200,400,250};
//打擂台
int max=0;
for(int i=0;i<5;i++)
{
if(max<arr[i])
{
max=arr[i];
}
}
cout<<max<<endl;
system("pause");
return 0;
}举例2:数组元素逆置
#include <iostream>
using namespace std;
int main()
{
int arr[5]={1,3,2,5,4};
cout<<"数组逆置前:"<<endl;
for(int i=0;i<5;i++)
{
cout<<arr[i]<<endl;
}
int start=0;//起始下标
int end=sizeof(arr)/sizeof(arr[0])-1;//结束下标
while(start<end)
{
//元素互换
int temp=arr[start];
arr[start]=arr[end];
arr[end]=temp;
//下标更新
start++;
end--;
}
cout<<"数组元素逆置后:"<<endl;
for(int i=0;i<5;i++)
{
cout<<arr[i]<<endl;
}
system("pause");
return 0;
}冒泡排序:
排序总轮数=元素个数-1
每轮对比次数=元素个数-排序轮数-1
举例:对 4,2,8,0,5,7,1,3,9 进行冒泡排序
#include <iostream>
using namespace std;
int main()
{
//用冒泡排序实现升序排列
int arr[9]={4,2,8,0,5,7,1,3,9};
//排序总轮数=元素个数-1
//每轮对比次数=元素个数-排序轮数-1
//开始
for(int i=0;i<9;i++)//总共排序轮数
{
for(int j=0;j<8-i;j++)//内层循环对比
{
//如果第一个数字大于第二个数字,交换
if(arr[j]>arr[j+1])
{
int temp;
temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
cout<<"排序后的结果为:";
for(int i=0;i<9;i++)
{
cout<<arr[i]<<" ";
}
cout<<endl;
system("pause");
return 0;
}2.二维数组
4种定义方式:
数据类型 数组名[行数][列数];
数据类型 数组名[行数][列数]={{数据1,数据2},{数据3,数据4}};
数据类型 数组名[行数][列数]={数据1,数据2,数据3,数据4};
数据类型 数组名[ ] [列数]={数据1,数据2,数据,数据4};
第二种更直观
//第二种 直观,可读性高
int arr2[2][3]=
{
{1,2,3},
{4,5,6}
};
//第三种
int arr3[2][3]={1,2,3,4,5,6};
//第四种
int arr4[][3]={1,2,3,4,5,6};
二维数组的数组名:查看二维数组所占空间,获取二维数组首地址。
int arr[2][3]=
{
{1,2,3},
{4,5,6}
};
cout<<"二维数组占用的内存空间为:"<<sizeof(arr)<<endl;
cout<<"二维数组第一行占用的内存为:"<<sizeof(arr[0])<<endl;
cout<<"二维数组第一个元素占用的内存为:"<<sizeof(arr[0][0])<<endl;
cout<<"二维数组的行数为:"<<sizeof(arr)/sizeof(arr[0])<<endl;
cout<<"二维数组的列数为:"<<sizeof(arr[0])/sizeof(arr[0][0])<<endl;
cout<<"二维数组的首地址为"<<(int)arr<<endl;
cout<<"二维数组第一行的首地址为:"<<(int)arr[0]<<endl;
cotu<<"二维数组第二行的首地址为:"<<(int)arr[1]<<endl;
cout<<"二维数组第一个元素的首地址为:"<<(int)&arr[0][0]<<endl;举例:考试成绩的统计(分别输出三个同学的总成绩)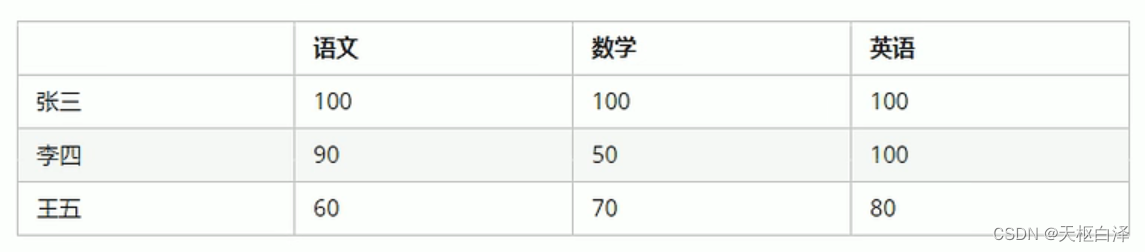
#include <iostream>
using namespace std;
#include <string>
int main()
{
int scores[3][3]=//创建二维数组
{
{100,100,100},
{90,50,100},
{60,70,80}
};
//统计每个人的总分
string name[3]={"张三","李四","王五"};
for(int i=0;i<3;i++)
{
int sum=0;
for(int j=0;j<3;j++)
{
sum+=scores[i][j];
}
cout<<name[i]<<"的总分为:"<<sum<<endl;
}
system("pause");
return 0;
}六.函数
作用:将一端经常使用的代码封装,减少重复代码
函数定义
函数定义的5个步骤:1.返回值类型 2.函数名 3.参数列表 4.函数体语句 5.return 表达式。
返回值类型 函数名(参数列表)
{
函数体语句
return 0
}

int add(int num1,int num2)
{
int sum=num1+num2;
return sum;
}函数调用
使用定义好的函数。
函数名(参数);
让我们使用例子来更好的理解一下
//定义加法函数
//在函数定义的时候num1和num2没有真实数据,是形参
int add(int num1,int num2)
{
int sum=num1+num2;
return sum;
}
int main()
{
//main函数中调用add函数
int a=10;
int b=20;
//函数调用语法:函数名称(参数)
//a和b为实参!
//当调用函数的时候,实参的值会传递给形参,即a给num1,b给num2
c = add(a,b);
a=100;
b=500;
c=add(a,b);
return 0;
}值传递
指 函数调用时实参将数值传入给形参。值传递时,如果形参发生改变,不影响实参。
如果函数不需要返回值,用void声明函数。
//定义函数,实现两个数字进行交换函数
void swap(int num1,int num2)
{
int temp=num1;
num1=num2;
num2=temp;
}
int main()
{
int a=10;
int b=20;
swap(a,b);
cout<<"a="<<a<<endl;
cout<<"b="<<b<<endl;
system ("pause");
return 0;
}函数的常见样式:无参无返,无参有返,有参无返,有参有返。
//无参无返
void test01()
{
cout<<"test01"<<endl;
}
//无参无返函数调用
int main()
{
test01();
return 0;
};
//有参无返
void test02(int a)
{
cout<<"test02="<<a<<endl;
}
//有参无返函数调用
int main()
{
test02(100);
return 0;
}
//无参有返
int test03()
{
cout<<"test03"<<endl;
return 1000;
}
//无参有返函数调用
int main()
{
int num1=test03();
cout<<"num1="<<num1<<endl;
return 0;
}
//有参有返
int test04(int b)
{
cout<<"test04 b="<<b<<endl;
return 2000;
}
//有参有返函数调用
int main()
{
int num2=test04(10000);
cout<<"num2="<<num2<<endl;
return 0;
}函数的声明
声明可以多次,定义只能一次。告诉编译器函数名以及如何调用函数。函数的实际主体可以单独定义
//比较函数,实现两个整型数字的比较,返回较大值
//提前告诉编译器函数的存在
//函数声明:
int max(int a,int b);
int main()
{
int a=10;
int b=20;
cout<<max(a,b)<<endl;
return 0;
}
int max(int a,int b)
{
return a>b?a:b;
}函数的分文件编写
4个步骤:
1.创建后缀名为.h的文件
2.创建后缀名为.cpp的源文件
3.在头文件中写函数声明
4.在源文件中写函数定义
举例:
#include <iostream>
using namespace std;
//包含swap的头文件,头文件自己写
#include <swap.h>
//函数的分文件编写
//实现两个数字进行交换的函数
//函数的声明
void swap(int a,int b);
//函数的定义
void swap(int a,int b);
{
int temp=a;
a=b;
b=temp;
cout<<"a="<<a<<endl;
cout<<"b="<<b<<endl;
}
int main()
{
int a=10;
int b=20;
swap(a,b);
system ("pause");
return 0;
}七.指针
基本概念
可以间接访问内存
内存编号从0开始,16进制表示。可以用指针变量保存地址。
指针变量的定义:
数据类型 * 变量名;
//定义指针
int a=10
int *p;
//让指针记录变量a的地址
p=&a;
cout<<"a的地址为:"<<&a<<endl;
cout<<"指针p为:"<<p<<endl;
//通过解引用的方式找到指针指向的内存
//指针前加*代表解引用,指的是 找到指针指向内存中的数据,用*p来修改内存
*p=1000;
cout<<a<<endl;
cout<<*p<<endl;32位操作系统下,占4个字节,64位操作系统下,占8个字节。与数据类型无关。
空指针和野指针
空指针:指向内存中编号为0的空间。用来初始化指针变量。
空指针指向的内存空间不可访问!因为0-255的内存编号是系统占用的。
野指针:指针变量指向非法的内存空间。
int *p=(int*)0x1100;//这是野指针const修饰指针
有三种情况:
1.const修饰指针--常量指针
2.const修饰常量--指针常量
3.const即修饰指针,又修饰常量
const int * p=&a;
这是常量指针。指针的指向可以修改,但是指针指向的值不能修改。
比如*p=20是错的,p=&b是对的。
int *const p=&a;
指针常量。指针的指向不能改,指针指向的值可以改。可以理解为作用在*,所以指针指向不能改。比如比如*p=20是对的,p=&b是错的。
const int *const p=&a;
修饰指针修饰常量。指针的指向和指向的值都不能修改。
指针和数组
利用指针访问数组中的元素
int arr[10]={0,1,2,3,4,5,6,7,8,9};
int *p=arr;
p++;//指针向后偏移4个字节
//利用指针遍历数组
int *p2=arr;
for(int i=0;i<10;i++)
{
cout<<*p2<<endl;
p2++;
}指针和函数
利用指针作函数参数,可以修改实参的值
1.值传递
不能修改实参
void swap01(int a,int b)
{
int temp=a;
a=b;
b=temp;
}
int main()
{
int a=10;
int b=20;
swap01(a,b);
cout<<a<<" "<<b<<endl;
return 0;
}2.地址传递
可以修改实参
void swap01(int *p1,int *p2)
{
int temp=*p1;
*p1=*p2;
*p2=temp;
}
int main()
{
int a=10;
int b=20;
swap01(&a,&b);
cout<<a<<" "<<b<<endl;
return 0;
}指针、数组、函数
案例:封装一个函数,利用冒泡排序,实现对整型数组的升序排序。
#include <iostream>
using namespace std;
//封装一个函数,利用冒泡排序,实现对整型数组的升序排序
void bubble(int *arr,int len)//首地址和长度
{
for(int i=0;i<len-1;i++)
{
for(int j=0;j<len-i-1;j++)
{
if(arr[j]>arr[j+1])
{
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
}
//打印数组
void printarray(int *arr,int len)
{
for(int i=0;i<len;i++)
{
cout<<arr[i]<<endl;
}
}
int main()
{
//创建一个数组
int arr[10]={4,3,6,9,1,2,10,8,7,5};
int len=sizeof(arr)/sizeof(arr[0]);
//创建函数,实现冒泡排序
bubble(arr,len);
//打印排序后的数组
printarray(arr,len);
system("pause");
return 0;
}八.结构体
属于用户自定义的数据类型,允许存储不同的数据类型。结构体可以用来表示复杂的数据结构,例如包含多个属性的对象。
定义和使用
struct 结构体名 {结构体成员列表};
3种方式通过结构体创建变量:
struct 结构体名 变量名
struct 结构体名 变量名={成员1值,成员2值...}
定义结构体时顺便创建变量
#include <iostream>
#include <string>
using namespace std;
struct student
{
//成员列表
string name;//姓名
int age;//年龄
int score;//分数
}stu3;//结构体变量创建方式3
//通过类型创建具体的学生
int main()
{
//第一种
struct student stu1;//struct关键字可省略
stu1.name="张三";
stu1.age="18";
stu1.score=100;
cout<<stu1.name<<stu1.age<<stu1.score<<endl;
//第二种
struct student s2={"李四",19,80};
cout<<s2.name<<s2.age<<s2.score<<endl;
//第三种
s3.name="王五";
s3.age="20";
s3.score="60";
cout<<s3.name<<s3.age<<s3.score<<endl;
}总结:定义结构体时的关键字是struct,不能省略;创建结构体变量时,struct可以省略;结构体变量利用操作符“.”访问成员。
结构体数组
将自定义的结构体放入数组中方便维护。
struct 结构体名 数组名 [元素个数]={ { },{ }......{ } };
#include <iostream>
#include <string>
using namespace std;
//定义结构体
struct student
{
string name;
int age;
int score;
}
int main()
{
struct student arr[3]
{
{"张三",18,100}
{"李四",19,80}
{"王五",20,60}
}
//给结构体数组中的元素赋值
student[2].name="赵六";
student[2].age=30;
student[2].score=70
//遍历结构体数组
for(int i=0;i<3;i++)
{
cout<<student[i].name
<<student[i].age
<<student[i].score<<endl;
}
system("pause");
return 0;
}结构体指针
通过指针访问结构体中的成员。
利用操作符->可以通过结构体指针访问结构体属性
#include <iostream>
#include <string>
using namespace std;
struct student {
string name;
int age;
int score;
};
int main()
{
struct student s={"张三",18,100};
struct student *p=&s;
cout<<p->age<<endl;
return 0;
}结构体嵌套结构体
结构体的成员是结构体
结构体做函数参数
值传递和地址传递,改变形参,值传递实参不变,地址传递实参改变。
如何访问结构体成员?
在 C++ 中,可以使用成员访问运算符(.)来访问结构体的成员。
//访问单个成员
struct Person {
std::string name;
int age;
};
Person person1;
person1.name = "LiMing"; // 访问结构体成员 name
person1.age = 25; // 访问结构体成员 age//访问成员变量的指针
struct Person {
std::string name;
int age;
};
Person person1;
std::string* namePtr = &person1.name; // 获取成员 name 的指针
int* agePtr = &person1.age; // 获取成员 age 的指针
*namePtr = "LiMing"; // 通过指针访问成员 name
*agePtr = 25; // 通过指针访问成员 age//访问结构体数组
struct Person {
std::string name;
int age;
};
Person people[3];
people[0].name = "ZhangSan"; // 访问数组中第一个结构体的成员 name
people[1].age = 30; // 访问数组中第二个结构体的成员 age那什么情况下使用结构体呢?结构体有什么用处呢?
组织相关数据:结构体可以将相关的数据成员组合在一起,方便对数据进行管理和操作。例如,可以定义一个表示学生信息的结构体,包括姓名、年龄、性别和成绩等。
实现面向对象编程:虽然 C++ 本身不是纯粹的面向对象编程语言,但可以使用结构体来模拟类的一些特性。通过结构体,可以定义成员函数来操作结构体的属性。
数据封装和隐藏:结构体可以将数据和相关的操作封装在一起,提供了一定程度的数据隐藏和保护。
传递结构体参数:可以将结构体作为函数参数进行传递,使得函数能够操作和处理结构体的数据。
存储数据:结构体可以用于在内存中存储和组织数据。例如,在链表、树、图等数据结构中,常常使用结构体来表示节点或边。
映射到数据库表:在某些情况下,可以将结构体与数据库表进行映射,方便数据的存储和检索。
九.引用
引用是一种特殊的变量类型,它提供了对另一个变量的别名或别名访问。引用并非对象本身,而是对象的别名。对引用的操作会直接影响到目标变量。此外,引用必须在定义时初始化,并且引用的类型必须与目标变量的类型相同。
类型 & 引用名 = 已定义的变量名;
//共享同一内存单元,相同的地址
#include <iostream>
using namespace std;
int main()
{
int i=10
int &j=i;
cout<<"i的地址:"<<&i<<endl;
cout<<"j的地址:"<<&j<<endl;
return 0;
}在 C++ 中,引用和指针都是用于处理变量的别名或间接访问的工具。
以下是一些情况下使用引用的建议:
传递参数:当需要将一个变量作为函数参数传递,并在函数内部修改该变量的值时,使用引用通常是更好的选择。这可以避免额外的拷贝操作,提高性能。
返回值:如果函数需要返回一个复杂的对象或结构,并且你希望在返回时避免拷贝操作,可以考虑使用引用返回。
成员函数:在类的成员函数中,使用引用可以方便地访问和修改类的成员变量。
以下是一些情况下使用指针的建议:
动态分配内存:当需要在运行时动态分配内存时,使用指针是常见的选择。
处理数组:如果需要处理数组,可以使用指针来操作数组元素。
函数指针:使用函数指针可以将函数作为参数传递给其他函数。
正确使用引用的一些要点:
初始化引用:引用在定义时必须立即初始化,并且引用的对象在其生命周期内不能被销毁。
避免循环引用:避免在引用之间创建循环引用,这可能导致内存泄漏或其他问题。
使用const 引用:如果不想在函数中修改传递的参数,可以使用 const 引用,这样可以确保参数不会被意外修改。
常引用是一种引用类型,它限制对引用对象的修改。常引用的主要特点是:
不能修改引用对象:通过常引用,只能读取引用对象的值,而不能对其进行修改。
const 特性可传递:如果常引用指向一个 const 对象,则不能通过常引用来修改该对象;如果常引用指向一个非 const 对象,则不能通过常引用来修改该对象的 const 部分。
#include <iostream>
using namespace std;
void swap(int &a, int &b)//使用引用传递参数的主要优势是可以避免不必要的数据复制,提高性能,并允许函数对原始变量进行修改
{
int temp = a;
a = b;
b = temp;
}
int a[]={1,3,5,7,9};
int index(int i)
{
return a[i];
}
int main()
{
int a=3,b=5;
swap(a,b);
cout<<"a="<<a<<"b="<<b<<endl;
cout<<"index(3)="<<index(3)<<endl;
index(3)=3;//通过函数参数的引用修改了数组a中的值
return 0;
}注意:不允许建立void类型的引用;不能建立引用的数组;不能建立引用的引用,不能建立指向引用的指针;可以将引用的地址赋值给一个指针,指针指向原来的变量;可以用const对引用加以限定,不允许改变该引用的值。
十.类和对象
类声明的内容包括数据和函数,分别称为数据成员和成员函数。可以分为公有、私有、保护3种。
#include <iostream>
using namespace std;
//类声明的内容包括数据和函数,分别称为数据成员和成员函数。可以分为公有、私有、保护3种
class MyClass {
public:
// 公有数据成员
int m_X;
int m_Y;
// 公有成员函数
void SetX(int x) { m_X = x; }
void SetY(int y) { m_Y = y; }
int GetX() { return m_X; }
int GetY() { return m_Y; }
};
int main() {
MyClass myObject;
myObject.SetX(10);
myObject.SetY(20);
std::cout << "X: " << myObject.GetX() << std::endl;
std::cout << "Y: " << myObject.GetY() << std::endl;
return 0;
}一般来说,一个类的数据成员应该声明为私有成员,成员函数声明为公有成员。如果私有部分在类的第一部分时,关键字private可以省略。不能在类声明中给数据成员赋初值。
成员函数
定义
返回值类型 类名::成员函数名(参数表)
{
函数体
}
class Score{
private:
int mid_exam;
int fin_exam;
public:
void setscore(int m,int t);
void showScore();
};
void Score::setsvore(int m,int t)
{
mid_exam=m;
fin_exam=t;
}
void Score::showScore()
{
cout<<mid_exam<<endl;
cout<<fin_exam<<endl;
}内联成员函数的定义
内联成员函数是一种将成员函数的定义直接嵌入到类声明中的方法。这样做可以在调用该函数时避免函数调用的开销,提高程序的运行效率。
注意! 内联成员函数的定义通常应该放在类的声明中,而不是在类的外部定义。如果你将内联成员函数的定义放在类的外部,你需要在函数声明前加上inline关键字,以指示该函数是内联的。
内联成员函数主要用于函数体较小、执行频率较高的情况,可以提高程序的性能。但过度使用内联成员函数可能会导致代码膨胀,增加编译时间和内存消耗。因此,需要根据实际情况合理使用内联成员函数。
class MyClass {
public:
// 内联成员函数的声明
int add(int a, int b);
};
int MyClass::add(int a, int b) {
// 内联成员函数的定义
return a + b;
}1.隐式声明
隐式声明是将函数体直接放在类体内
//隐式声明
class Score
{
public:
void Score::setsvore(int m,int t)
{
mid_exam=m;
fin_exam=t;
}
void Score::showScore()
{
cout<<mid_exam<<endl;
cout<<fin_exam<<endl;
}
private:
int mid_exam;
int fin_exam;
}class A {
public:
void func(int x, int y) { i = x; j = y; } // 隐式声明的内联函数
void print() { cout << "两数相乘为:" << i * j << endl; } // 隐式声明的内联函数
private:
int i, j;
};2.显式声明
显式声明是使用关键字inline进行声明
//显式声明
class Score
{
public:
inline void setScore(int m,int f);
inline void showScore();
private:
int mid_exam;
int fin_exam;
};
inline void Score::setScore(int m,int f)
{
mid_exam=m;
fin_exam=f;
}
inline void Score::showScore()
{
cout<<mid_exam<<endl;
cout<<fin_exam<<endl;
}class A {
public:
void func(int x, int y); // 显式声明的内联函数
void print(); // 显式声明的内联函数
private:
int i, j;
};
inline void A::print() { cout << "两数相乘为:" << i * j << endl; }无论是隐式声明还是显式声明,效果都是一样的,都会在编译时将函数体插入到每一个调用它的地方,以提高运行效率。但是要注意,只有相对简单的成员函数才适合声明为内联函数,因为这样会增加编译后代码的长度。
用inline定义内联函数时,必须将类的声明和内联函数的定义放在同一个文件或头文件中。
对象的定义和使用
对象的定义:类的对象可以看成是该类类型的一个实例,它具有类定义的属性和行为。可以通过定义类来创建对象。类定义包括数据成员(属性)和成员函数(行为)。
对象的使用:创建对象:使用类名和构造函数来创建对象。对象的成员访问:使用点运算符(.)来访问对象的成员,包括属性和成员函数。对象的操作:通过调用成员函数来执行对象的操作。
#include <iostream>
using namespace std;
class Score
{
public:
void setScore(int m,int f);
void showScore();
private:
int mid_exam;
int fin_exam;
}op1,op2;
对象名 . 数据成员名对象名 . 成员函数名 [ (参数表) ] op1 . setScore(89 , 99) ;
op1 . showScore ();
class Car {
public:
// 构造函数
Car(int speed, string brand) : speed(speed), brand(brand) {}
// 成员函数
void accelerate(int acceleration) {
speed += acceleration;
}
int getSpeed() const {
return speed;
}
private:
int speed;
string brand;
};
int main() {
Car myCar(100, "BMW");
// 调用成员函数加速
myCar.accelerate(50);
// 获取汽车速度
int currentSpeed = myCar.getSpeed();
cout << "当前速度: " << currentSpeed << endl;
return 0;
}-
类的成员函数:
- 定义:可以在类定义中声明成员函数,也可以在类外部定义。
- 访问权限:成员函数可以是公共(public)、私有(private)或保护(protected)的。
- 内联函数:可以使用关键字
inline将函数定义为内联函数,以提高性能。
-
对象的拷贝和赋值:
- 拷贝构造函数:用于创建对象的副本,通常使用
拷贝赋值运算符或拷贝构造函数进行拷贝操作。 - 赋值运算符:用于将一个对象的值赋给另一个对象。
- 拷贝构造函数:用于创建对象的副本,通常使用
-
对象的生命周期:
- 对象的创建和销毁:使用
new操作符创建对象,使用delete操作符销毁对象。 - 自动对象:局部对象在其作用域结束时自动销毁。
- 动态分配的对象:需要手动释放内存。
- 对象的创建和销毁:使用
-
继承和多态:
- 继承:一个类可以从另一个类继承属性和行为。
- 多态:通过虚函数和继承实现,允许基类指针或引用指向派生类对象,并根据实际对象类型调用相应的函数。
-
类的封装和信息隐藏:
- 封装:将类的内部实现细节隐藏起来,只公开必要的接口。
- 信息隐藏:通过访问权限控制来限制对类成员的访问。
成员函数在类外定义的一般形式
返回值类型 类名::成员函数名(参数表){ 函数体}
在建立对象的同时,采用构造函数给数据成员赋值,通常由以下两种形式
类名 对象名[(实参表)]
类名 *指针变量名 = new 类名[(实参表)]
成员初始化列表实现对数据成员的初始化。
类名::构造函数名([参数表])[:(成员初始化列表)]
{
//构造函数体
}
带默认参数的构造函数
Score(int m = 0, int f = 0); //带默认参数的构造函数
自定义拷贝构造函数
类名::类名(const 类名 &对象名) {
拷贝构造函数的函数体;
}
















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











