






这周速通数据结构,以下是个人产出。
一、数据结构三要素
包括逻辑结构,数据运算,存储结构。
1.逻辑结构
包括集合结构,线性结构,树形结构,图状结构。
集合结构:数据元素之间仅仅同属一个集合;
线性结构:数据元素之间是一对一的关系;
树形结构:数据元素之间是一对多的关系;
图状结构:多对多。
2.数据运算
基于特定的逻辑结构、实际需求来定义基本运算。
3.存储结构(物理结构)
顺序储存:逻辑上相邻的元素存储在物理位置相邻的存储单元中(邻接关系);
链式储存:元素逻辑相邻,物理位置不相邻。借用指针来表示逻辑关系;
索引存储:建立索引表来存放关键字,元素离散存放;
散列存储(哈希存储):根据关键字来计算地址。
所以,数据的存储结影响构内存分配的方便程度,从而影响数据运算的速度。因此,顺序存储的成本更高。
4.补充
数据类型:值的集合以及集合上的操作的总称
(1)原子类型:不可再分
(2)结构类型:能分解为若干分量,且各分量之间有一定的逻辑关系
抽象数据类型ADT:抽象数据组织以及相关操作,是对数据结构逻辑关系的描述。
二、算法
程序=算法+数据结构
算法是对特定问题求解步骤的描述。
1.算法的特性
有穷性:算法必须有穷,程序可以无穷。死循环不是算法!
确定性:相同输入得到相同输出。
可行性:通过基本元素实现有限次。
输入:0个或多个,取自于特定对象的集合。
输出:一个/多个。
2.什么是好算法?
正确求解问题,可读性(用好注释!!!),使之便于理解,健壮性(能应对非法数据,关注边缘问题),时间复杂度和空间复杂度低(省时省内存)。
3.时间复杂度
与机器性能,编程语言等等有关。
//以爱你一千遍和爱你三千遍为例
void loveyou(int n){//n为问题规模
int i=1;//爱你的程度 <1>
while(i<=n){ //<2>
i++;//每次+1 //<3>
printf("I Love You %d\n",i);//<4>
}
printf("I Love You More Than %d\n",n);//<5>
}根据语句频度,得:T(3000)=1+3001+2*3000+1,时间开销与问题规模的关系为
T(n)=3n+3
然而,当n足够大,只要考虑高阶的部分就行了。
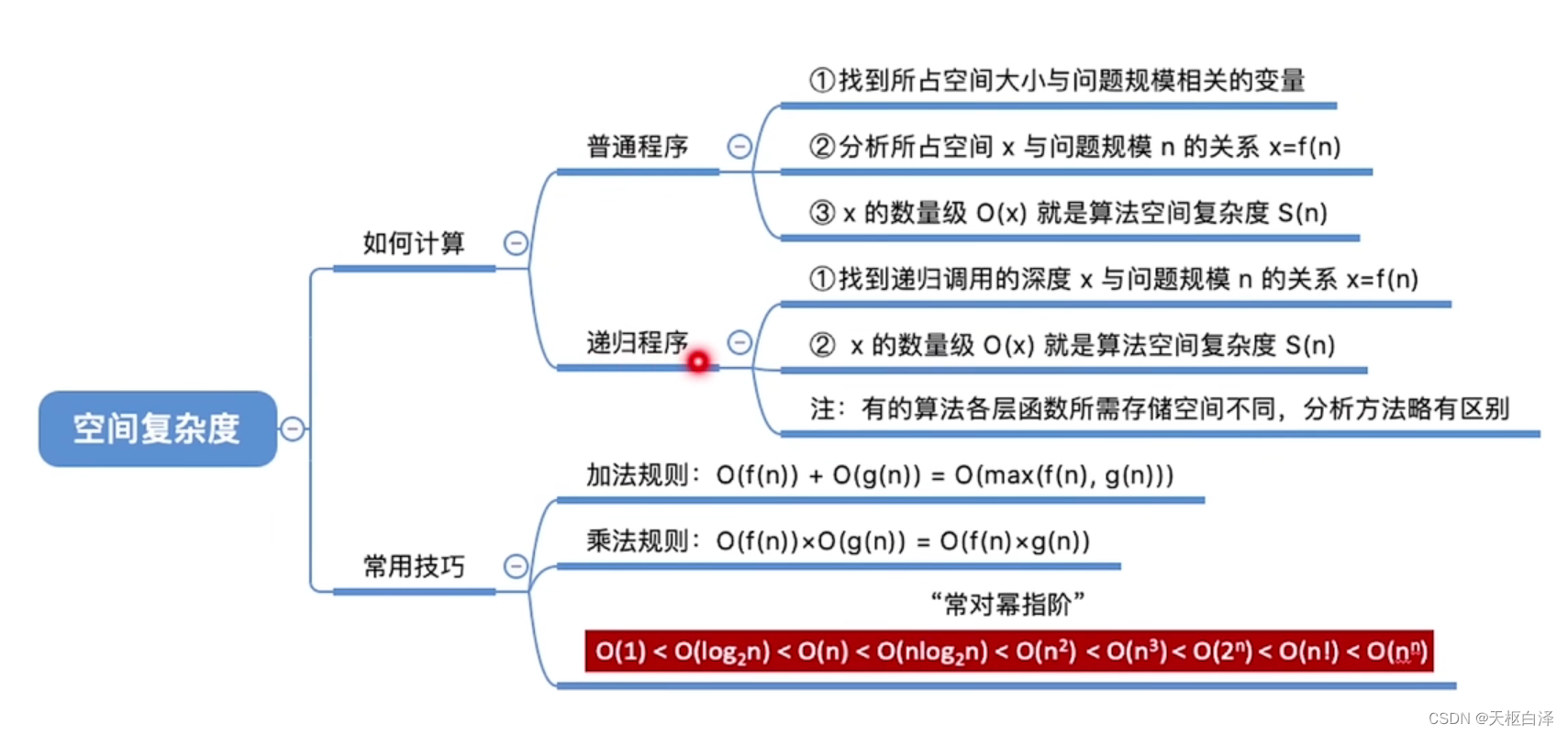
(1)加法规则
多项相加,只保留最高阶的项,系数变为1。
(2)乘法规则
多项相乘,都保留。
口诀:从小到大为常对幂指阶。
只用考虑循环语句,顺序执行的代码是常数项。多层循环只需关注最深层循环。只需挑选循环中一个基本操作分析即可。要度量最坏和平均时间复杂度。算法的性能问题只能在问题规模很大时才能暴露出来。
4.空间复杂度
以下是几个关键点:
这是空间开销与问题规模的关系。
只需关注与储存空间的大小有关的变量。
函数递归调用也会带来内存空间的开销。(函数调用栈)
空间复杂度=递归调用的深度。
三.线性表
是具有相同数据类型的n个数据元素的有限序列,其中n为表长,用L命名线性表。
要注意的点:
n=0 空表
L=(a1,a2,...,ai,...an)
每个数据元素所占空间一样大。
ai是该元素的位序,a1是表头元素,an是表尾元素
直接前驱和直接后驱
基本操作:
初始化(&L):分配内存空间
销毁(&L):释放内存空间
插入(&L,i,e):在表L第i个位置插入指定元素i
删除(&L,i,&e):同插入
按值查找(L,e):查找具有给定关键字值的元素
按位查找(L,i):获取表L中第i个位置的元素的值
求表长(L):即元素的数据个数
输出(L):按前后顺序输出L所有元素值
判空操作(L):空表返回true
tips:创销,增删改查;将常用的操作/运算进行封装;注意什么时候传入参数的引用
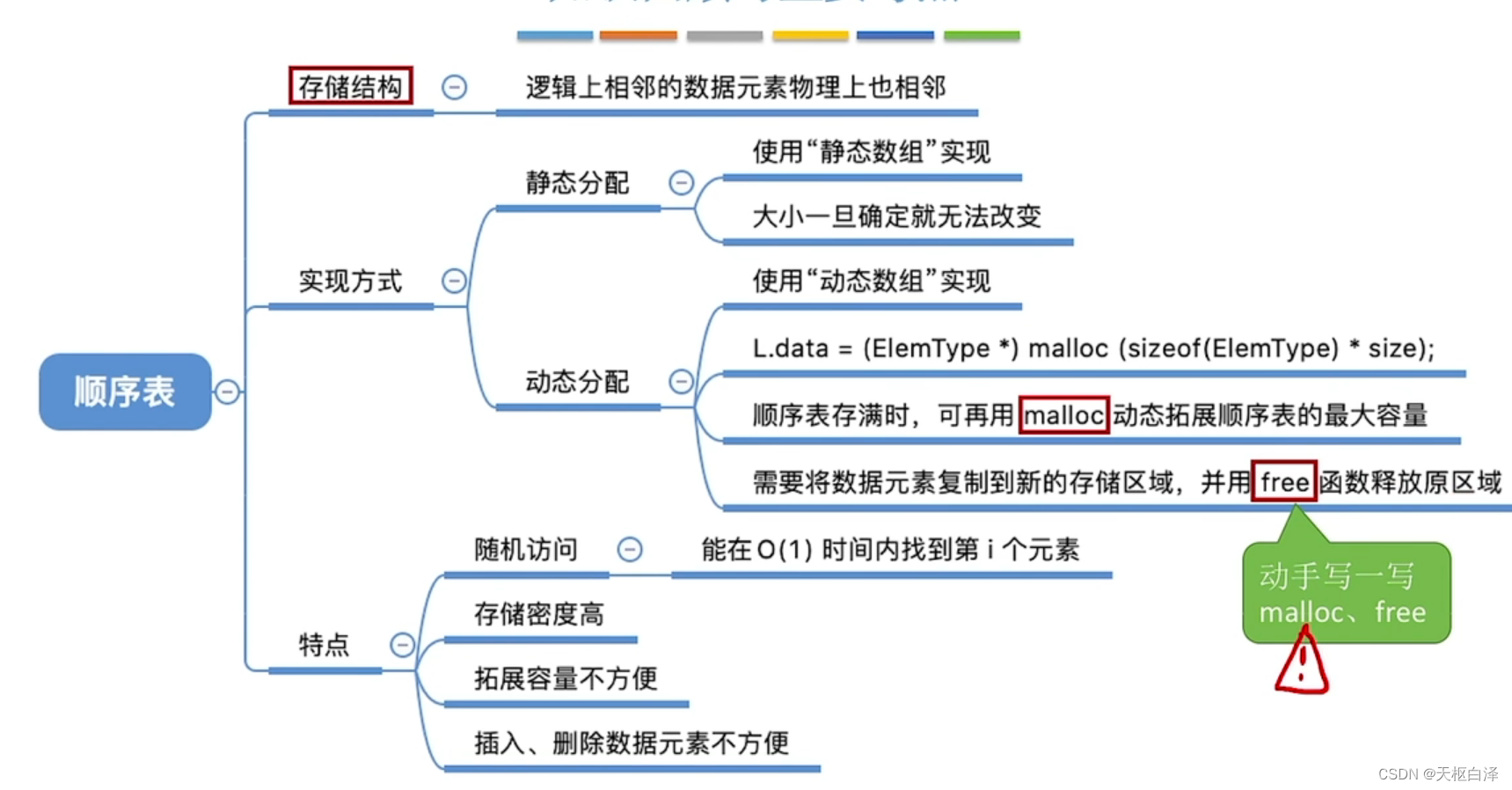
1.顺序表
用顺序存储的方式实现线性表
如何知道数据元素的大小?c语言用sizeof(数据元素类型)实现
1.静态分配
用静态的数组存放数据元素,要初始化一个数据表,储存空间是静态的。
2.动态分配
c语言——malloc,free函数,动态申请和释放内存空间
c++——new,delete关键字
顺序表特点:
随机访问:data[i-1] 在O(1)时间内找到第i个元素
存储密度高:每个节点存放数据元素,有的还存放指针
拓展容量不方便:只能动态分配,时间复杂度高
插入删除不方便:移动大量元素
c语言中,结构体的比较不能直接用==
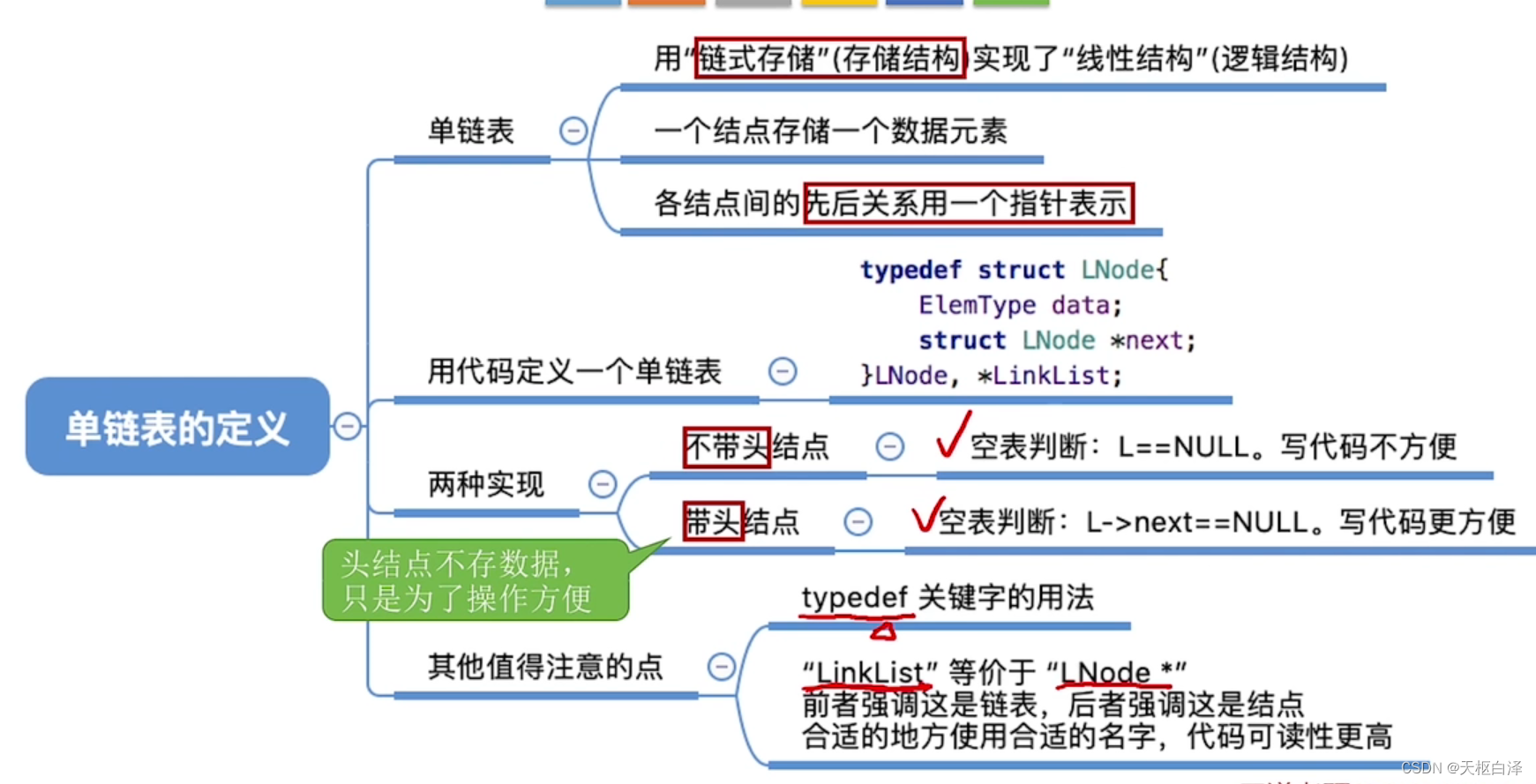
2.单链表
1.定义
链式存储,通过一组任意的存储单元来存储线性表中的数据元素
优点:不要求大片连续空间,改变容量方便
缺点:不能随机存取,耗费空间放指针
注意:结点,数据域,指针域
如何增加一个新节点?在内存中申请一个结点所需空间,用指针p指向这个节点
举例:
struct LNode{//定义单链表结点类型
ElemType data;//每个节点存放一个数据元素
struct LNode *next;//指针指向下一元素
};
struct LNode *p=(struct LNode*)malloc(sizeof(struct LNode));typedef关键字——数据类型重命名
typedef<数据类型><别名>
LinkLIst与LNode等价
LinkList——强调这是一个单链表
LNode——强调这是一个结点
空表无节点,防止脏数据。
判断单列表是否为空:看L==Null
头结点:代表链表上头指针指向的第一个结点,不带有数据
最好带头结点
2.插入和删除
前插结点用O(1)
删除指定结点:需要修改前驱结点的next指针
1.传入头指针循环寻找p的前驱结点
2.结点前插的实现

指定节点是最后一个节点时,要特殊处理
3.单链表的查找
基于带头结点
单链表不具备随机查找的特性,只能依次扫描
4.单链表的建立
尾插法和头插法
初始化一个单链表,取一个数据元素插入表头或表尾
核心是初始化和指定结点的后插操作
L->next=NULL//头插法有这样一句如果没有,就是野指针
3.双链表
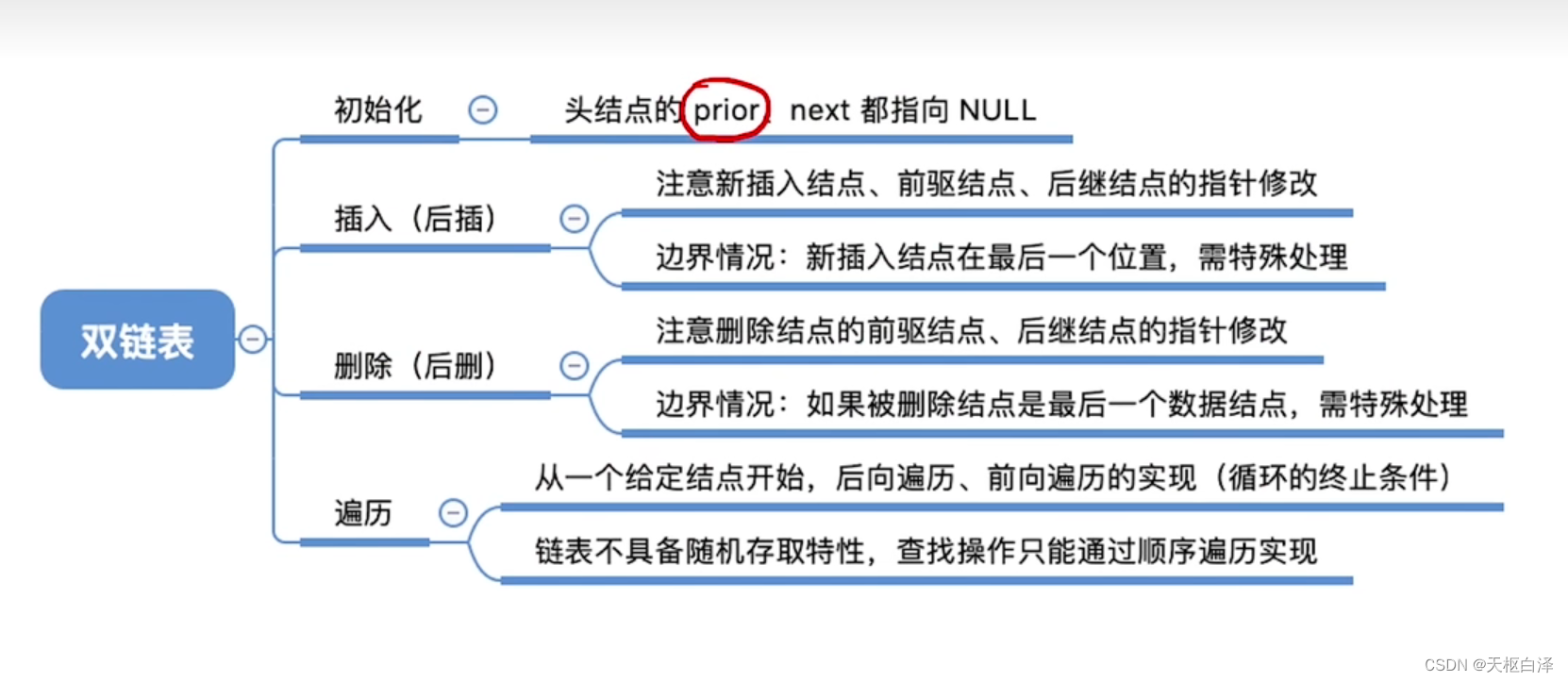
1.双链表的遍历
//后向遍历
while(p!=NULL){
p=p->next;//对结点p做相应处理
}//前向遍历
while(p!=NULL){
p->prior;//对结点p做相应处理
}//前向遍历(跳过头结点)
while(p->prior!=NULL){
P->prior;//对结点p做相应处理
}
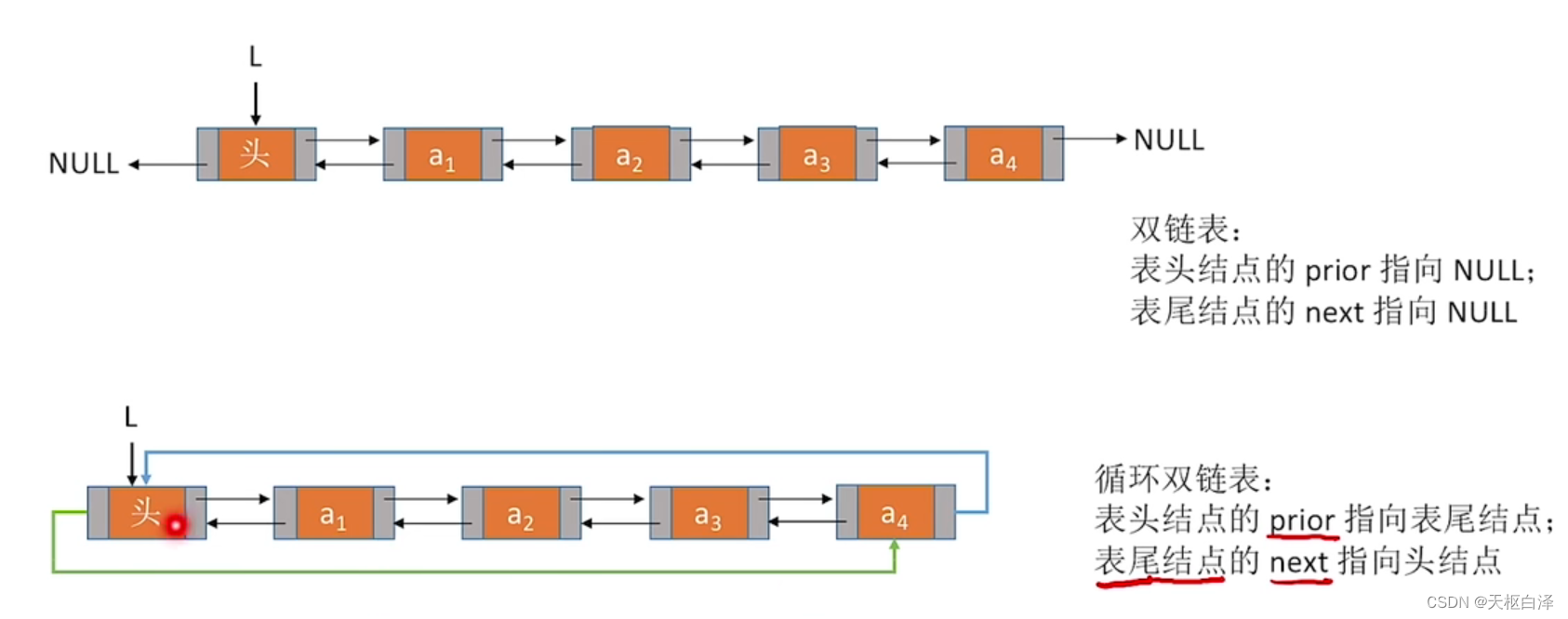
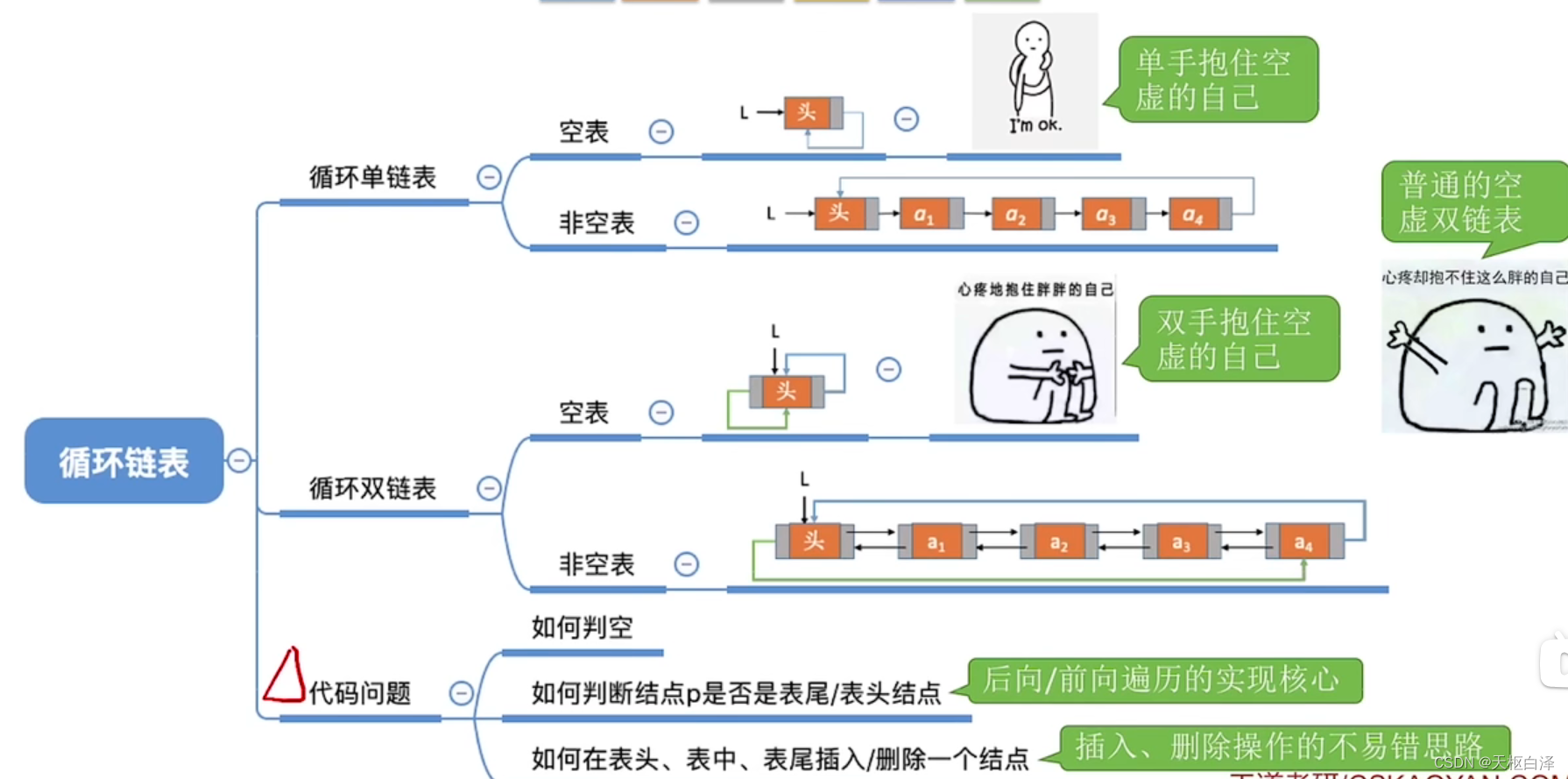
2.循环链表
很多时候对链表的操作都是在头部或尾部
可以让L指向表尾元素
3.静态链表
用数组的方式实现的链表,容量固定不可变,不能随机存取,适用于数据元素数量固定不变的链表。
分配一整片连续的内存空间,各个节点集中安置。0号结点充当“头节点”,游标充当指针。
查找:从头节点出发,遍历。
插入位序为i的结点:
1.找一个空结点,存入数据元素;
2.从头结点出发找到i-1 的结点;
3.修改新结点的next;
4.修改i-1号结点的next。
4顺序表和链表的比较
逻辑结构都是线性结构,都属于线性表;
二者存储结构不同,顺序存储/链式存储(特点/优点/缺点);
基本操作实现效率不同(初始化/插入/删除/查找......)。
四.栈
1.基本概念
栈是一种只允许在一端进行插入或删除操作的线性表。
术语:空栈、栈顶、栈底
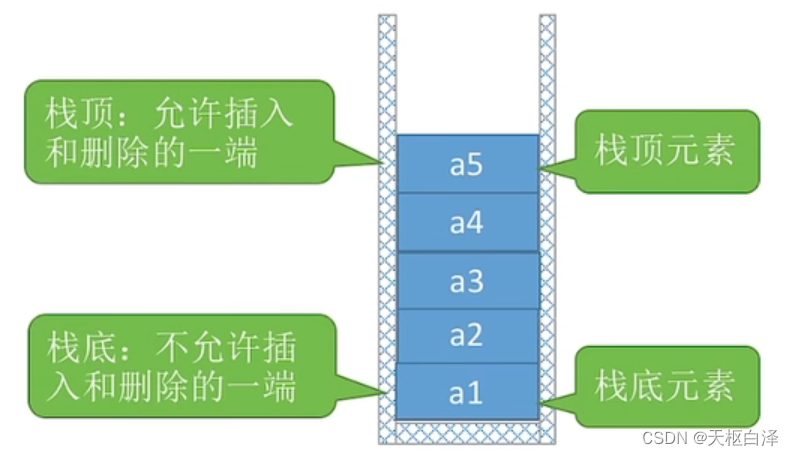
特点:后进先出(LIFO)
基本操作:
IintStack:初始化栈。构造空栈s,分配内存空间。
DestoryStack:销毁栈。销毁并释放栈S所占的内存空间。
Push:进栈。加入x成为新栈顶。
Pop:出栈。弹出栈顶元素并用x返回。
GetTop:读栈顶元素。访问栈顶元素,用x返回栈顶元素。
StackEmpty:判空。空则true。
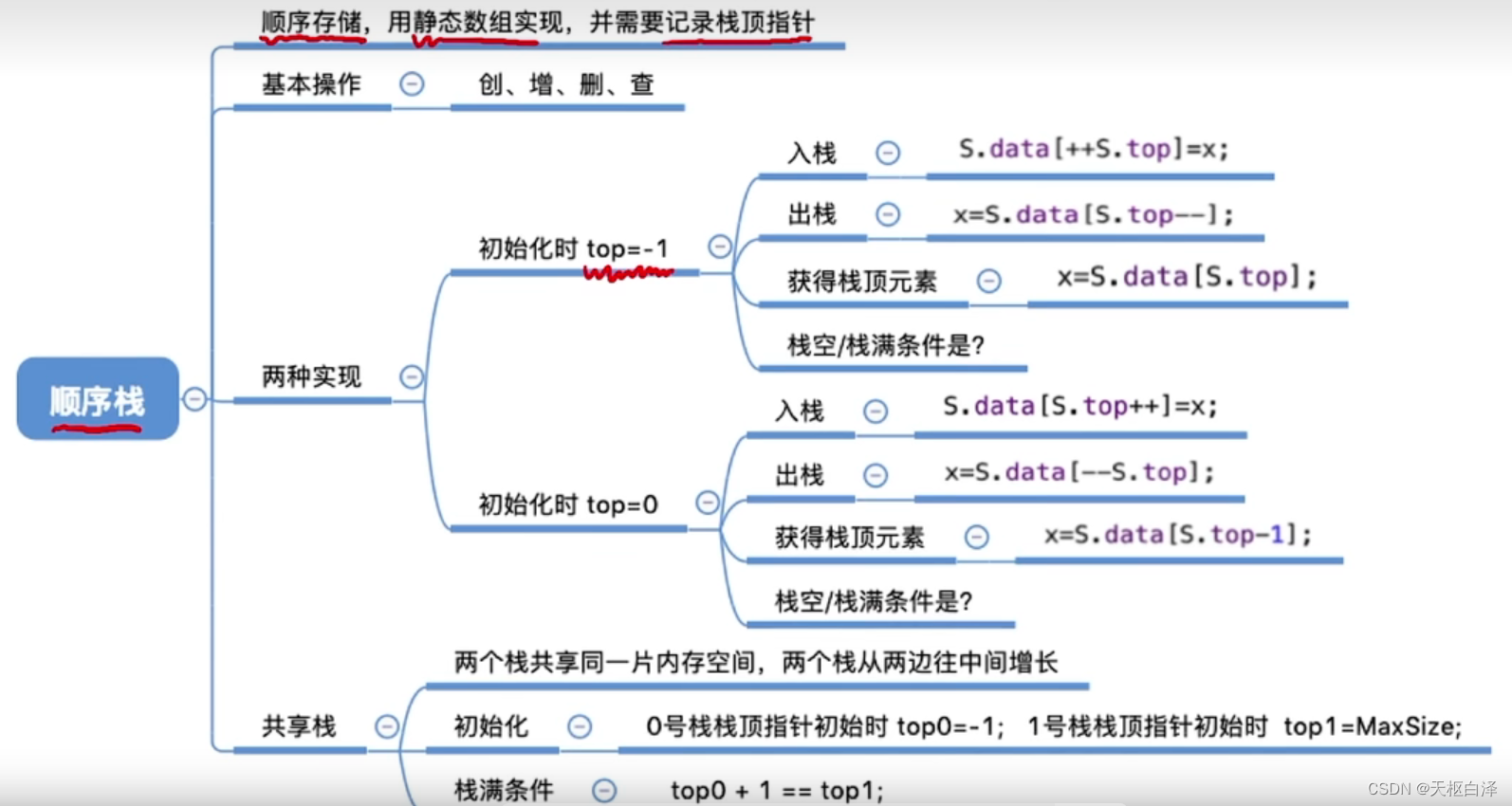
2.顺序存储
栈顶指针:记录数组下标
判断栈空只需top==-1(0号栈栈顶指针初始时)
指针先加1,新元素入栈
S.top=S.top+1;
S.data[S.top]=x;
//这两句等价于
S.data[++S.top]=x;注意:入栈错误写法为
S.data[S.top++]=x
而出栈正好相反:栈顶元素先出栈,指针再减1.
x=S.data[S.top--];//正确写法
x=S.data[--S.top];//错误写法读栈顶元素
x=S.data[S.top];
栈满的条件:top=MaxSize
顺序栈的特点:栈的大小不可改变。
解决办法:用链式存储/刚开始就分配一个较大的内存空间。但最优解还是共享栈。
共享栈:设置2个栈顶指针。两个栈从两边向中间增长
栈满的条件:top0+1==top1
3.链式存储
链栈推荐用不带头结点
同链表
4.队列
5.基本概念
定义:在一段插入、另一端删除的线性表。
特点:先进先出(FIFO)
术语:队头、队尾、空队列
队头:允许删除的一端
只能从队尾入队,判断为空返回true。(同栈)
6.顺序存储
队列已满:Q.rear=(Q.rear+1)%MaxSize
循环队列
取模运算将储存空间在逻辑上变成环状,所以队列已满的条件:对位指针的下一个位置是队头。
即(Q.rear+1)%MaxSize==Q.front
出队:只能让队头元素出队
先判断队空,队头指针后移
或者判断队列已满/已空:
int size=0//队列当前长度
插入成功size++,删除成功size--
其他出题办法:牺牲一个存储单元/增加辅助变量
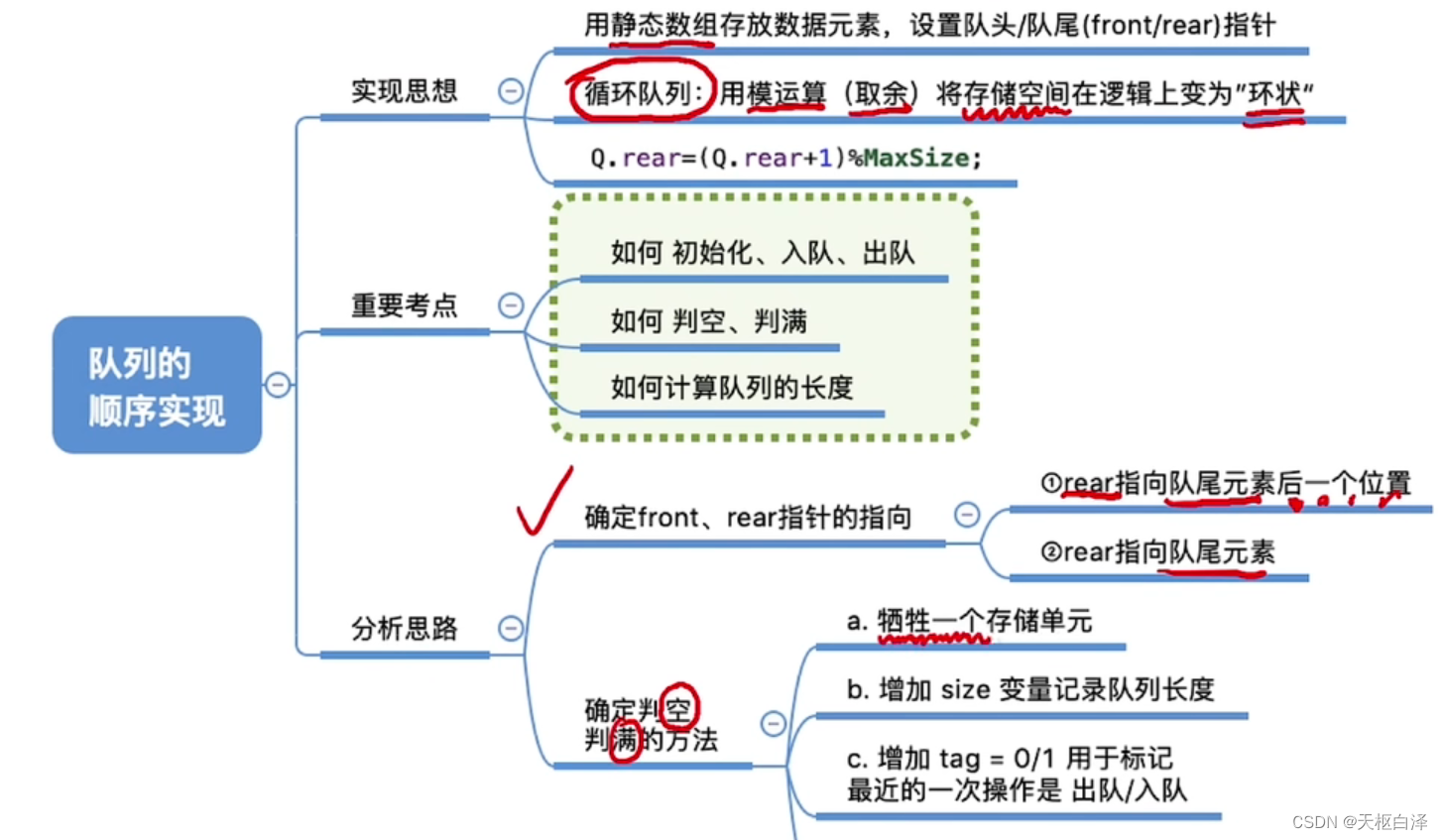
7.链式存储
带头结点和不带头结点
链队列:链式存储实现的队列
入队(带头结点):malloc申请一个新结点,新节点next指针域设为NULL,将rear指向的结点的next指针域指向新结点s
入队(不带头结点):第一个元素入队需要特殊处理
出队(不带头结点):最后一个结点出队,修改rear指针。恢复空队。
8.双端队列
输入受限和输出受限
卡特兰数
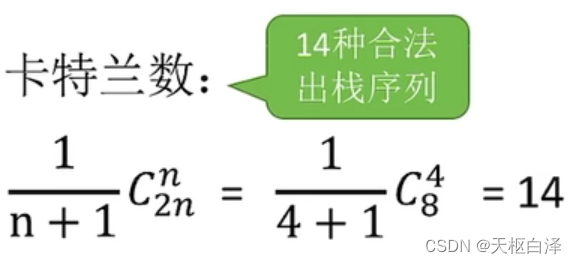
在栈中合法的输出队列,在双端队列中必定合法
9.栈的应用
括号
用注释的方式简要说明接口,扫描到左括号,入栈,扫描到右括号且当前栈空则匹配失败,若栈非空则弹出栈顶元素检查是否匹配。
用静态数组存放栈中元素可能会栈溢出so可用链栈。
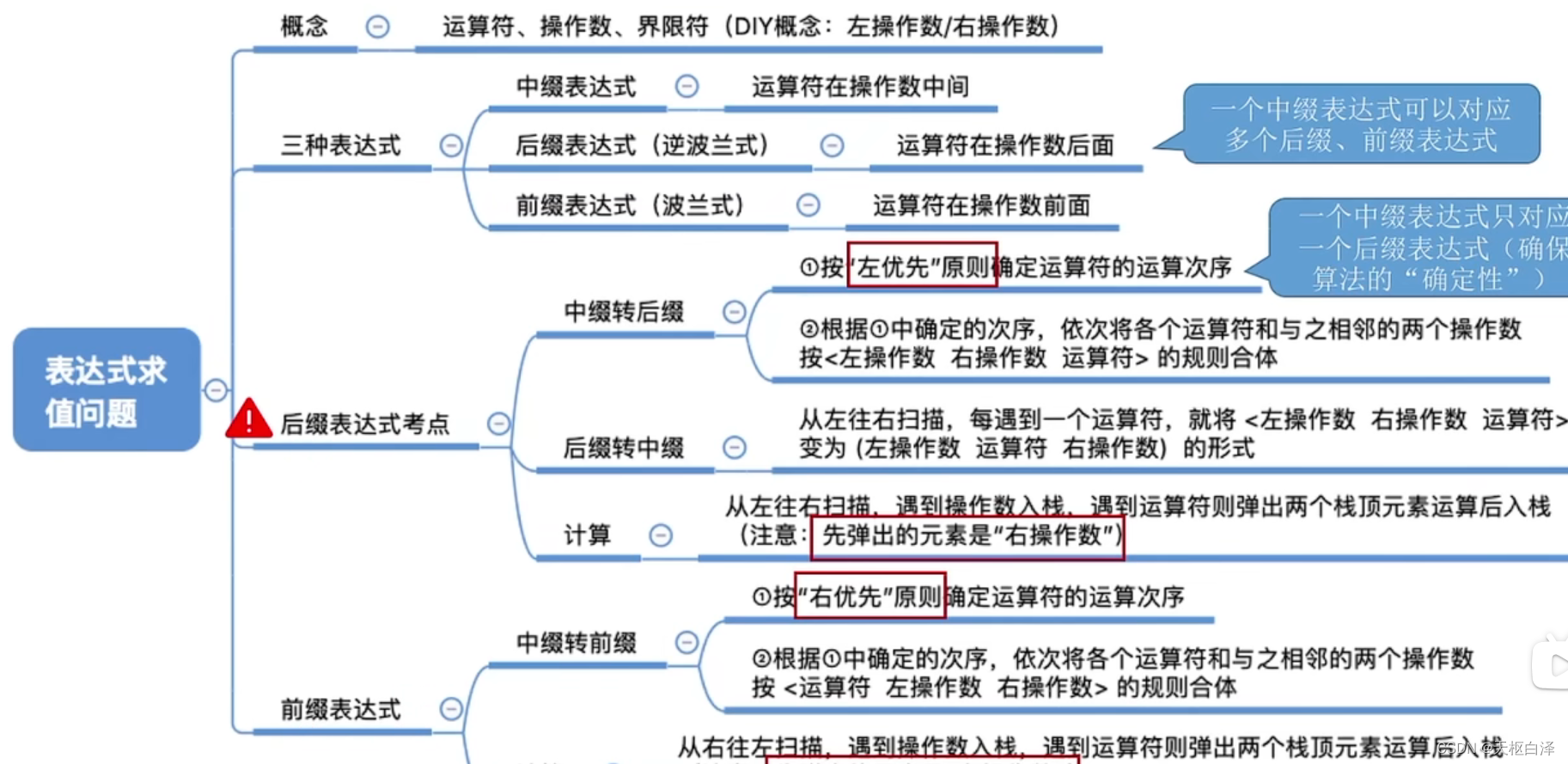
表达式求值
分为:前缀(波兰),中缀,后缀(逆波兰)
组成:操作数,界限符,运算符
中缀:a+b;a+b-c;a+b-c*d
前缀:+ab;ab+c-或abc-+;ab+cd*-
后缀:ab+;-+abc;-+ab*cd
“左优先”原则(中转后)
中转右:右优先,先出栈是左操作数

递归
递归表达式(递归体),边界条件(递归出口)
如果递归层数太多可能会导致栈溢出,效率低,重复计算。
可以自定义栈。
10.压缩存储
特殊矩阵
对称矩阵:aij=aji 主对角线i=j i<j上三角区 i>j下三角区
普通储存n*n二维数组
压缩存储策略:只存储主对角线+下三角区
按照行优先原则存入一维数组,数组大小为(1+n)*n/2
可以实现一个映射函数。
三角矩阵:行优先原则,最后一个位置存储常量c
三对角矩阵(带状矩阵):3(i-1)-1<=k<3i-1
稀疏矩阵:非零元素远远少于矩阵元素的个数
五.串
子串:串中任意个连续的字符组成的子序列
主串:包含子串的串
空串vs空格串
通常对子串增删改查,以子串为操作对象。
串的基本操作:赋值,复制,判空,求串长,清空,销毁,串链接,求子串,比较
注意:长串更大;S>T,返回值大于0,以此类推;串的数据对象限定为字符集;字符集编码。
1.顺序存储
静态数组来实现(定长);动态数组来实现(堆分配存储)【用完手动free】
2.链式存储
存储密度低so每个结点存多个字符
3.字符串的模式匹配
朴素模式匹配
将主串中所有长度为m的子串依次与模式串对比
主串指针i 模式串指针
i=i-j+2;
j=1;
最坏时间复杂度O(mn)
即暴力解法,遍历。
KMP算法
对朴素模式的优化
主串指针不回溯,只有模式串指针回溯
next数组是根据子串求出来的,当前面的字符串已知时若有重复的,从当前字符匹配即可。
求next数组:
next数组第1、2位分别为0、1,后面每一位根据前一位进行比较。后一位与前一位内容相等的话,next值加1,不等则继续寻找直到有相等的为止,如果没有相等 则为一。
next[1]=0表示模式串应右移一位,主串当前指针后移一位,在和模式串第一字符进行比较。
求next数组时间复杂度O(m)
KMP算法最坏时间复杂度O(m+n)。
六.树与二叉树
1.树基本概念
n个结点的有限集
空树n=0;根节点、分支节点、叶子结点、子树。
结点树=所有结点度数和+1;度为m的树第i层最多有m的i-1次方个结点。
2.二叉树
n个结点的有限集
每个结点不存在度数大于2的结点;二叉树可以是空集,根可以有空的左子树和空右子树;二叉树有左右之分次序不能颠倒。
二叉树和树是2个概念
特殊的二叉树:满二叉树、完全二叉树、二叉排序树、平衡二叉树。
3.二叉树存储方式
顺序存储:
要将二叉树的结点编号和完全二叉树对应起来。
链式存储:
找到指定结点p的左/右,和父结点;只能从根节点开始遍历。
n个结点的二叉链表共有n+1个空链域。
4.二叉树的遍历
先序遍历:二叉树为空,不用操作;二叉树非空,访问根节点再先序遍历左子树右子树
中序遍历:二叉树为空,不用操作;非空,先序遍历左子树,访问空节点,先序遍历右子树
后序遍历:二叉树为空,不用操作;非空,先序遍历左子树,先序遍历右子树,访问空节点
5.线索二叉树
在二叉树的结点加上线索。
先序线索二叉树:线索指向先序前驱、先序后继;后序线索二叉树:线索指向后序前驱、后序后继。
二叉树的线索化:中序、先序、后续。
6.树的存储结构
顺序存储:每个结点中保存指向双亲的指针。
数据域和双亲域
链式存储+顺序存储:n个头结点组成一个线性表,并用顺序表存储。
7.树和森林的遍历
树:
先根遍历:先访问根结点,再依次遍历
后根遍历:先对每个子树后根遍历,再返回根结点
层序遍历:若树非空,根结点入队;队列非空,队头元素出队并访问,该元素的孩子依次入队
直至队尾为空。
森林:
先序遍历等同于先根遍历
中序遍历等同于后根遍历
8.哈夫曼树
带权路径最短的树
注意:哈夫曼树的构造和哈度曼编码。
七.图
非线性结构,顶点之间关系任意,顶点前驱后继个数没有限制,任意两个顶点之间都可能相关。
1.存储结构
邻接矩阵
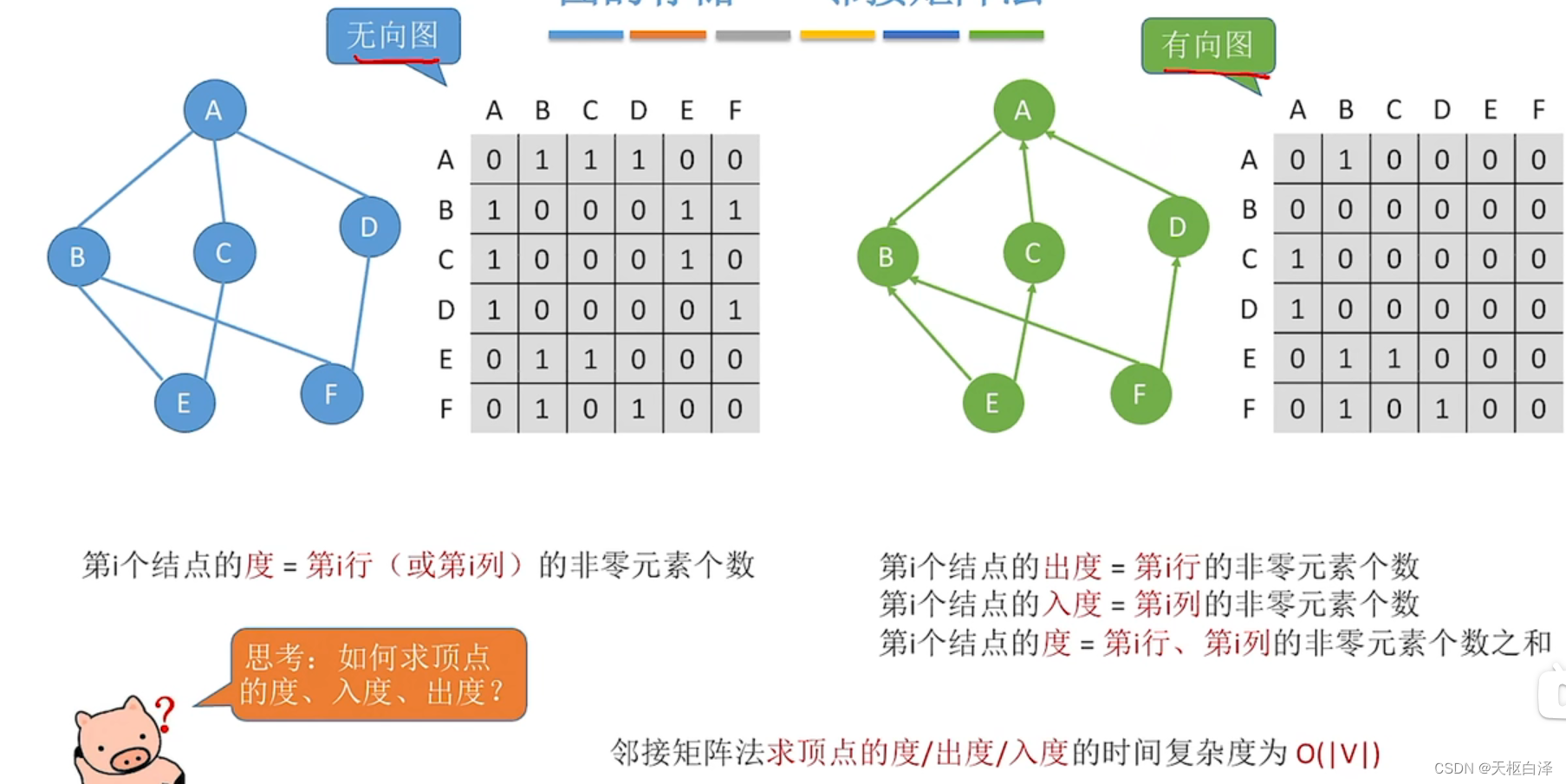
邻接表
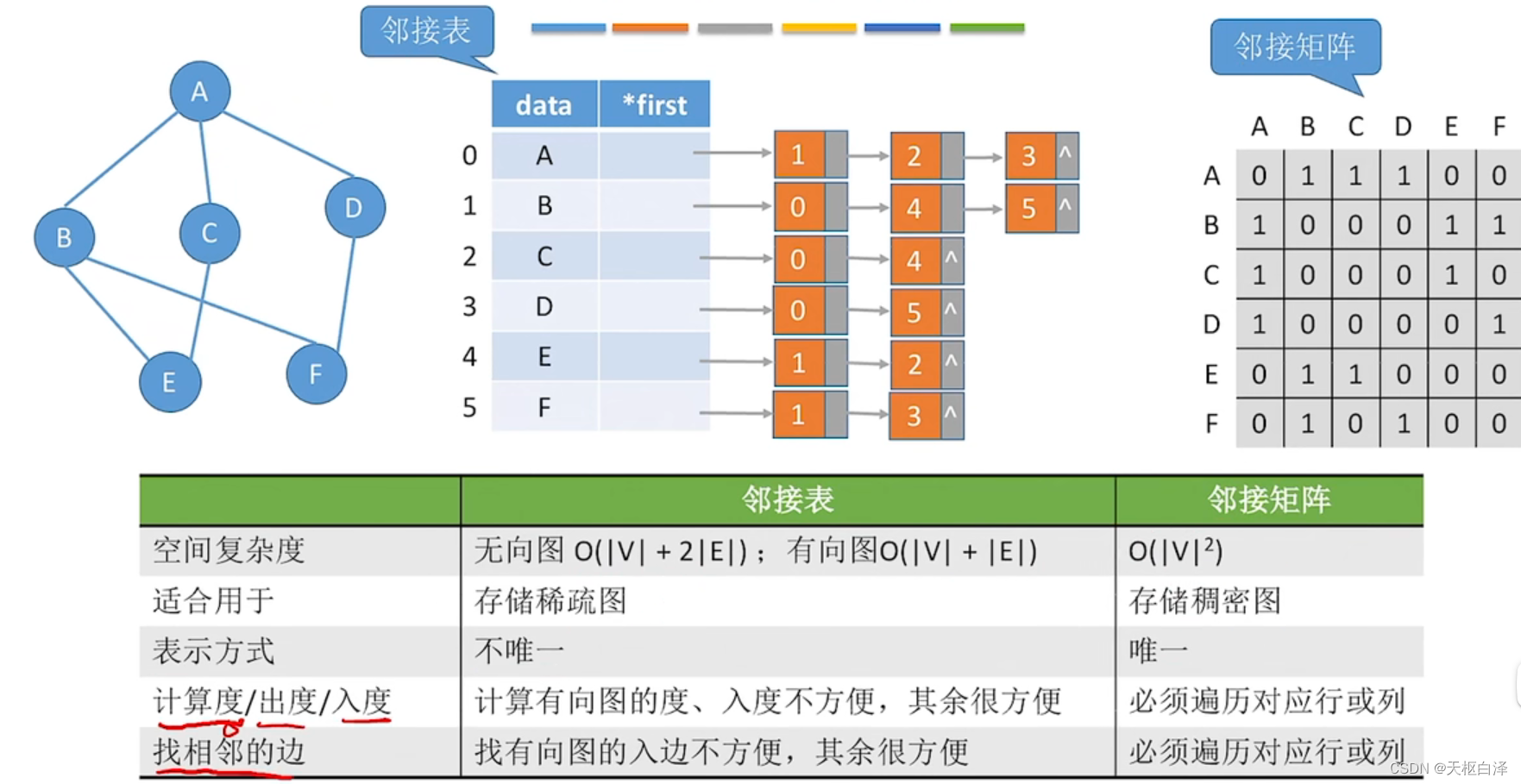
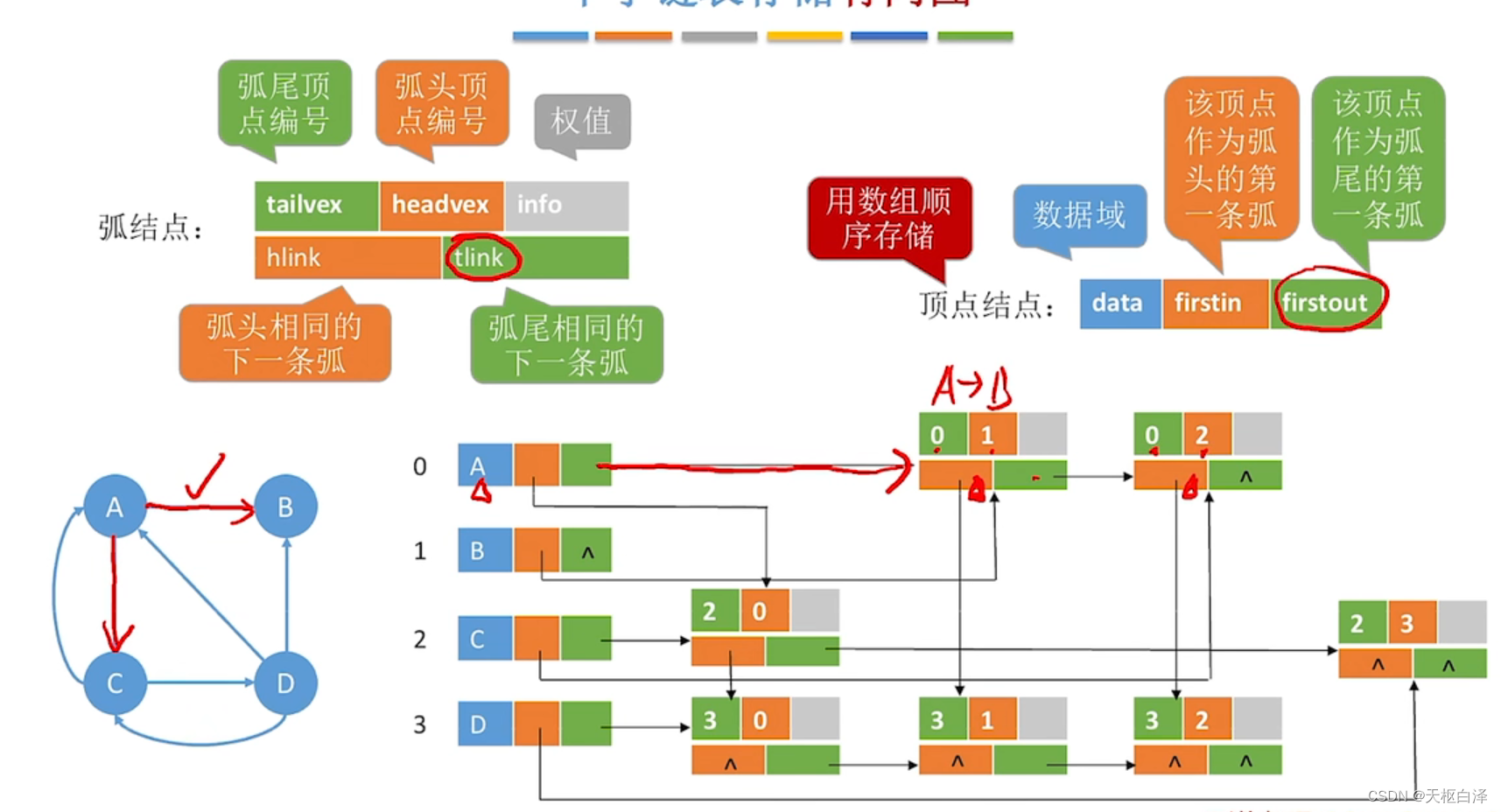
十字链表(存储有向图)
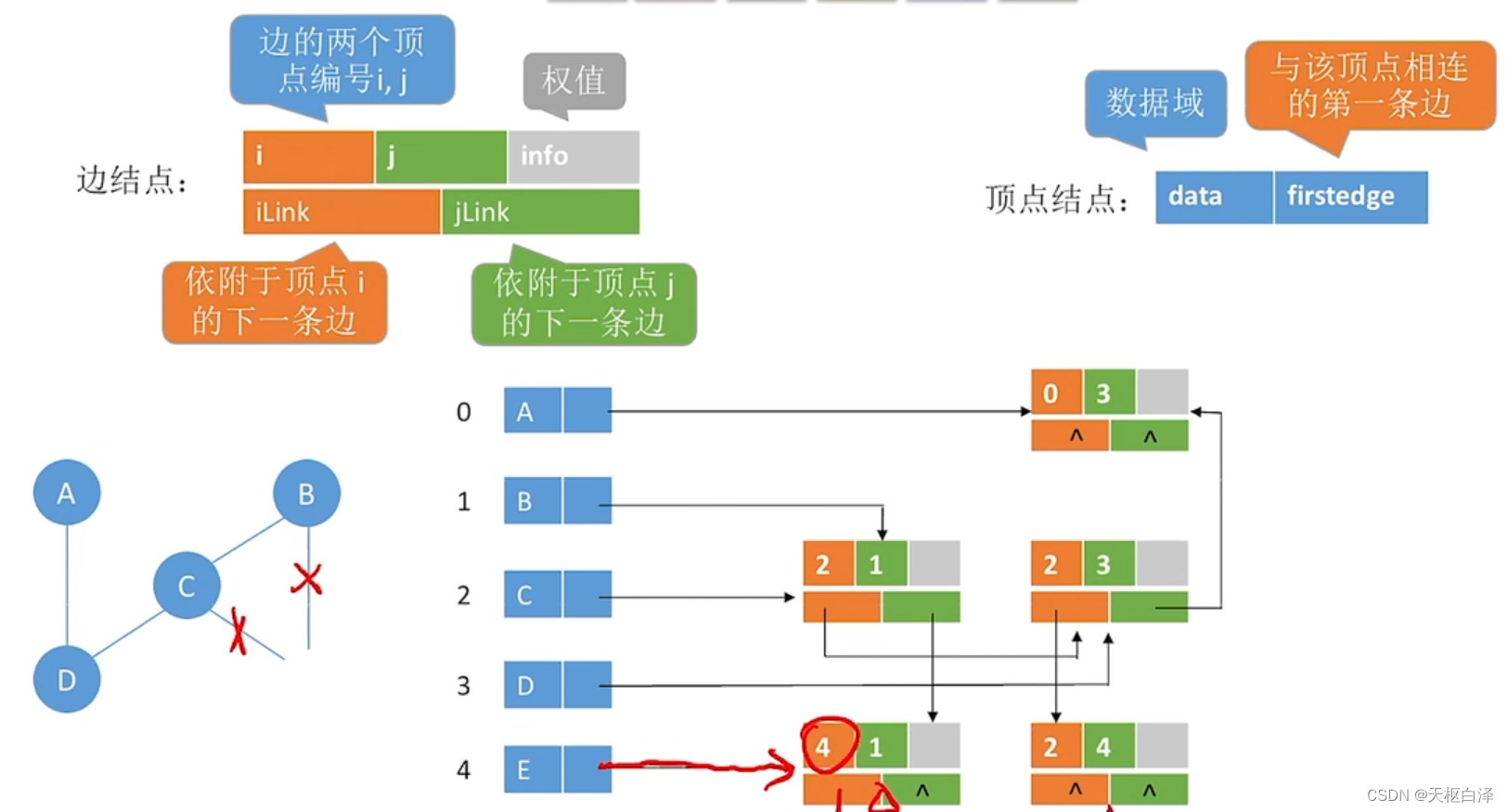
邻接多重表(存储无向图)
四种比较

2.图的遍历
从任意指定顶点出发按规则访问所有顶点,每个顶点只被访问一次。
分类:深度优先遍历/广度优先遍历
八.查找
查找表:由同一类型的数据元素构成的集合。
对查找表进行的经常操作为:查找、检索、增加、删除。
静态查找表:对查找表只进行前两种操作。
动态查找表:不仅限于前两种操作。
关键字:数据元素中某个数据项的值,用以标识一个数据元素,如果是唯一标识,则称为主关键字。
查找是否成功:根据给定的值,在查找表中确定一个其关键字等于给定值的元素,如果表中存在这样元素,则称查找成功。
分类:折半查找/索引查找
九.排序
重新排列表中的元素,使表中元素满足按关键字有序的过程(关键字可以相同)
评价指标:时间复杂度、空问复杂度;
稳定性:关键字相同的元素在排序之后相对位置不变,称为稳定的;
分类:
内部排序:数据都在内存一一关注如何使时间、空间复杂度更低;
外部排序:数据太多,无法全部放入内存。
几种排序(这里比较粗糙):
直接插入排序/折半插入排序/希尔排序;
冒泡排序/快速排序;
简单选择排序/堆排序;
归并排序/基数排序。
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











