







 本文详细介绍了HTTP协议的基础知识,包括名词解释、一次完整的HTTP事务流程、TCP连接的建立与释放、HTTP header详解、cookie与session的区别以及Keep-Alive的工作原理。通过本文,读者将深入理解HTTP协议的工作机制和关键概念。
本文详细介绍了HTTP协议的基础知识,包括名词解释、一次完整的HTTP事务流程、TCP连接的建立与释放、HTTP header详解、cookie与session的区别以及Keep-Alive的工作原理。通过本文,读者将深入理解HTTP协议的工作机制和关键概念。
名词解释
HTTP:超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准(默认端口为80)。
HTTPS : HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲就是HTTP的安全版。承载于TLS或SSL协议层之上,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。(默认端口为443)。
HTTP和HTTPS的区别
- HTTP协议采用明文传输信息,存在信息窃听、信息篡改和信息劫持的风险。HTTPS基于HTTP开发,使用安全套接字层(SSL)进行信息交换,是使用TLS/SSL加密的HTTP协议,简单讲就是HTTP的安全版。
- http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- HTTP 的URL 以http:// 开头,而HTTPS 的URL 以https:// 开头。
- HTTP无需证书,而HTTPS 需要认证证书(SSL数字证书)。
一次完整的HTTP事物
当我们在浏览器的地址栏输入一个域名并回车之后,正常情况下,我们浏览器就会显示出我们想要的内容,那么这个过程就是一次完整的HTTP事物了。
我们知道为了找到一台主机最终需要通过硬件地址才能找到,但是这样有太繁琐,所以在TCP/IP协议的网络层,也就是我们常说的IP层,有一个地址解析协议(ARP协议),它能自动的从IP地址解析出硬件地址,所以我们只需要找到主机对应的IP地址就可以了。但是如何找到这个IP地址呢,IP地址是一个全世界范围内唯一的32位的标识符,4个字节(例如:127.0.0.1),但是如果我们要访问很多个网站,是不是就要记住这么多的数字呢, 当然不用,伟大的人类发明了“域名”这个东西,通过域名服务器就可以找到对应的IP地址,所以你只要记住网站的域名就可以开心的上网了不是吗?
言归正传,那么当我们在地址栏输入www.google.com时,浏览器和服务器都会经历些什么呢?
- 浏览器搜索自身的DNS缓存,看是否有www.google.com 对应的条目,如果有且没有过期则解析到此结束,否则进入下一步。
- 如果没有找到对应的条目,那么浏览器会搜索操作系统自身的DNS缓存,如果找到且没过期则停止搜索解析到此结束,否则进入下一步。
- 如果在操作系统的DNS缓存中也没有找到,那么尝试读取hosts文件,看有没有该域名对应的IP地址,如果有则解析成功,否则进入下一步。
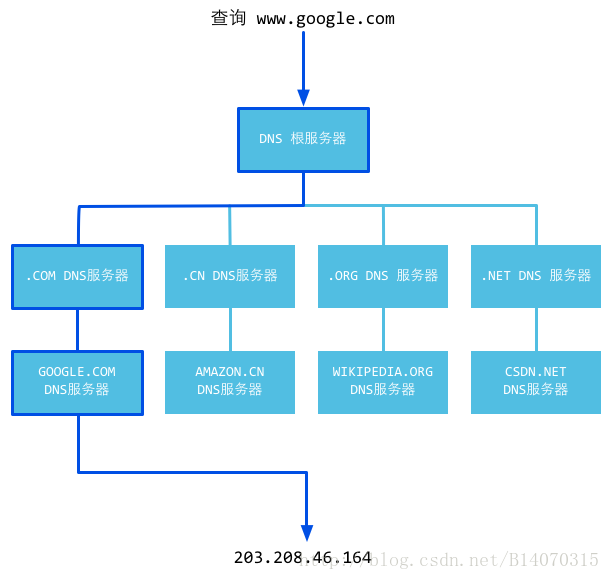
如果在hosts文件中也没有找到对应的条目,浏览器就会发起一个DNS的系统调用,就会向本地配置的首选DNS服务器发起域名解析请求,之后的解析过程如下图所示。
- 找到对应的服务器后,浏览器发送请求要求建立TCP连接,请求服务器里的资源文档,等浏览器发送完HTTP Request(请求)包后,服务器接收到请求包之后才开始处理请求包,此时服务器调用自身服务,返回HTTP Response(响应)包;客户端收到来自服务器的响应后开始渲染这个Response包里的主体(body),如果请求的资源包含有动态语言的内容,那么服务器会调用动态语言的解释引擎负责处理“动态内容”,并将处理得到的数据返回给客户端,等收到全部的内容随后断开与该服务器之间的TCP连接,由浏览器解释HTML文档,在客户端屏幕上渲染图形结果。
此时一次完整的HTTP事物就处理完了,需要注意的是客户机与服务器之间的通信是非持久连接的,也就是当服务器发送完应答后就与浏览器断开连接,等待下一次请求。
TCP连接的建立与释放
上面讲到在进行域名解析时的第五步,浏览器与服务器建立连接,浏览器发送请求,服务器应答请求,然后断开的过程,就是传说中非常经典的三次握手与四次握手了。
TCP连接的建立
最初两端的TCP进程都处于关闭状态,首先客户端会主动打开连接,服务器将会被动打开连接,并处于监听状态。
1. 浏览器向服务器发出连接请求报文段,这是报文段首部中的同部位SYN=1,同时选择一个初始序号seq=x,TCP规定,SYN报文段不能携带数据,但要消耗掉一个序号,之后TCP客户端会进入SYN-SENT(同步已发送)状态。
2. 服务器收到连接请求报文段后,如果同意建立连接,则向客户端发送确认,在确认报文段中应把SYN位和ACK位都置1,确认号是ack=x+1,同时也为自己选择一个初始序号seq=y,这个报文段也不能携带任何数据,同样要消耗一个序号,此时服务器的TCP进程就会进入SYN-RCVD(同步已收到)状态。
3. 客户端收到服务器的确认后,还要在发送一次确认,为什么?(防止已失效的连接请求报文段又传到了服务器),确认报文段的ACK置1,确认号ack=y+1,自己的序号seq=x+1,此时TCP连接已经建立,客户端进入ESTABLISHED(已建立连接)状态,当服务器收到客户端的确认后,也进入ESTABLISHED(已建立连接)状态。
上面TCP连接建立的过程就叫做三次握手(three-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









