






Authors:
Manli Shu1∗ Weili Nie2 De-An Huang2 Zhiding Yu 2 Tom Goldstein 1 Anima Anandkumar2,3,† Chaowei Xiao2,4†
1 University of Maryland, 2 NVIDIA, 3 Caltech, 4 Arizona State University
Paper:https://arxiv.org/pdf/2209.07511.pdf
这篇文章CSDN上已经有人做过解读了,大家可以重点参考下 这篇blog ,本文在这篇博客上增添些自己的理解和看法。和各位大家们探讨下,欢迎指点!
Abstract
众所周知,预训练视觉-语言模型通过正当的文本提示设计已经在下游任务中显示了zero-shot的泛化性。取代原有手工设计的prompt,近期可学习的prompt通过训练数据运用于下游任务。但也受到特定域中数据训练的影响,这会大大降低模型原有的对未知类别的泛化能力。本文就提出一种TPT的优化方法。基于单张测试样本图像来训练自适应prompt,叫做Test-time prompt tuning。
图像分类任务:TPT通过最小化 置信度选择(confidence selection)交叉熵 来优化训练prompt,模型可以针对每个测试样本的不同的增广视图有相同的预测。
自然分布偏移(natural distribution shift):评估泛化性,1)TPT平均提升CLIP 3.6%,极大超过先前的需要附加任务具体训练数据的提示方法。 2)在评估跨数据集的未知数据分类的泛化性中,TPT表现与附加具体任务训练数据的SOTA方法相当。
这些文章除了分类 还有宁外一个任务 视觉推断(visual reasoning)
Context-dependent visual reasoning (文本独立的视觉推断):一个测试样本包含有两个集合的support images和一个query images用于评价。两个集合的support images强调人类物体交互的存在和缺失的概念。这个模型用来推理query image 包含的潜在的概念。每个概念可以是一个视觉关系,其中
表示物体,a表示行为,o表示物体。每个测试样本
通过陈述
在support images(正样本)中获取一个概念。也有负样本来不具备这个概念。
。其中
。请注意,o 和 a 都没有明确给出,它依赖于模型的推理
能够预测query image是否包含test image的特色概念 c。
Motivated
问题:CLIP包含了丰富的knowledge,但是如何有效利用仍是一个开放的问题。简单的策略是fine-tune,但是这回造成基础模型鲁棒性和泛化性的ood(out of distribution)。Prompts Tuning,通过改进模型文本输入,不会改变预训练的特征。
目的:本篇文章的目标是利用CLIP现有的知识来推动它zero shot模式的泛化性。因此,prompt tuning 是一个理想的方式来达到目标。将Test-time prompt tuning 为模型的单个测试图像量身提供文本。这可以帮助更精确的利用CLIP的知识。
Innovation
1.提出一种zs-shot prompt tuning 方案,在基于随机采样样本具有一致性的相同的预测结果。采用自监督的损失进行自我优化文本输入信息特征(与vote类似)。因而不需要训练标签和训练数据,直接对每一个样本进行提供专属prompt tuning。 Test-time prompt tuning
2.confidence selection
Approach
Test-time prompt tuning
详细处理:在推理阶段,基于单个样本不带标签,TPT优化prompt
。如公式所示。
TPT 图像分类:不需要标签,选择一个无监督损失用于prompt tuning. 假设模型在同一test image的不同Augmented View(AuV)中都预测一个一致性结果(这是个很强的假设,有些图像会发生畸变,有时候目标区域占比小畸变后识别概率会突变)。具体的,使用随机增广可以产生N个随机的(AuV)
, 同时最小化平均预测概率分布熵(entropy of the averaged prediction probability distribution)。
是模型的类别概率向量 通过prompt
和第i个AuV生成。
Confidence selection (置信度选择)
为减少随机增广的噪声,提出置信度选择(confidence selection)去提取AuV产生high-entropy预测。这些图像的视图可能缺少重要的信息用于正确分类。 因此,用prediction entropy 选择 confident samples。
用于每个测试样本。N 个增强视图的ρ 百分位数处的self-entropy从低到高排序, 所以confidence selection 相当于一张mask 将低于
的去掉。表示为
。H表示self-entropy.
Result
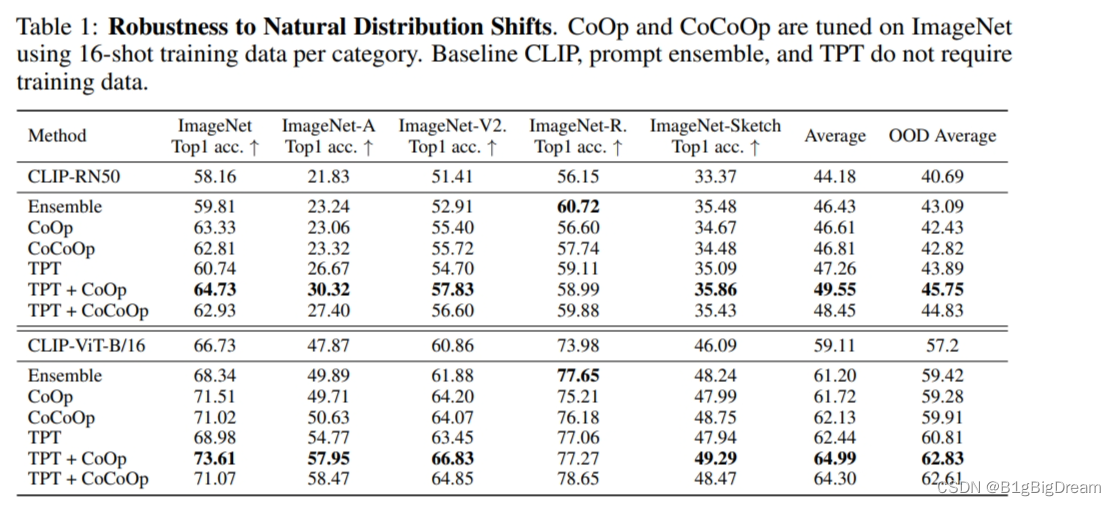
图1 中的TPT不需要训练数据表现比ZSCLIP要好。表现最好的反而是TPT+CoOp shot16 这个值得注意。在两个模型上都是这样。
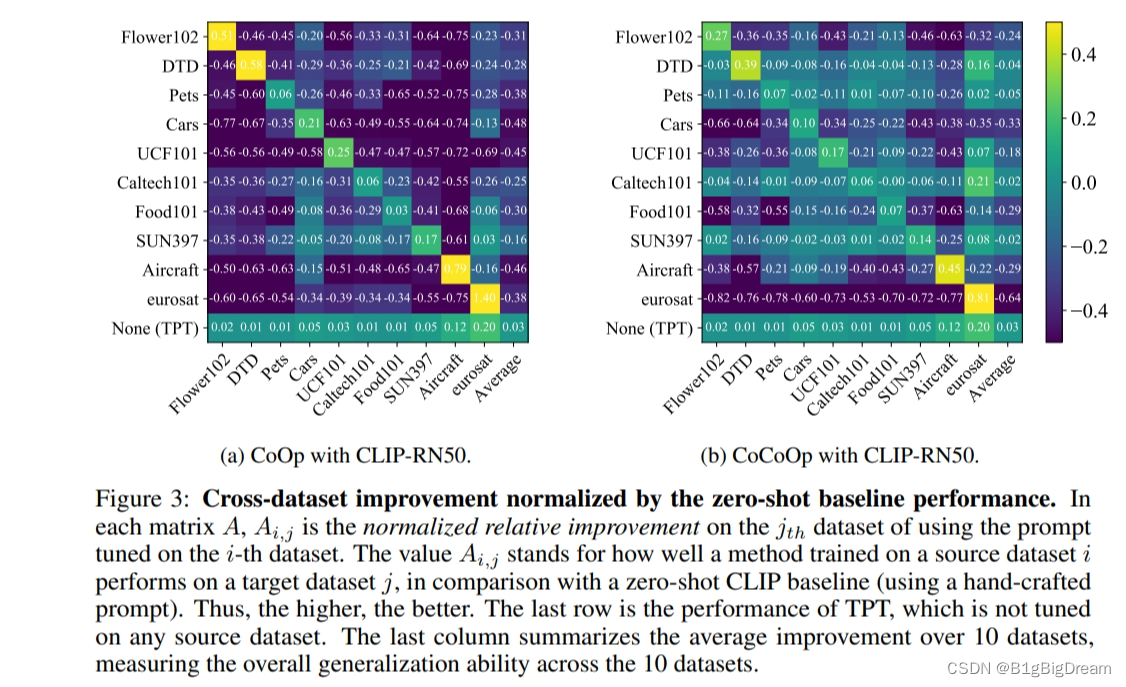
图2 表示了CoOp与CoCoOp的泛化性能表现不强,对训练集上的数据集有一定的偏见,而迁移到别的数据集上时是存在明显的下降趋势的,但是我很好奇的是为什么不放下CoOp+TPT的表现效果。 难道就是TPT?因该是的了,但是表1中为什么要单列出来?好奇中。
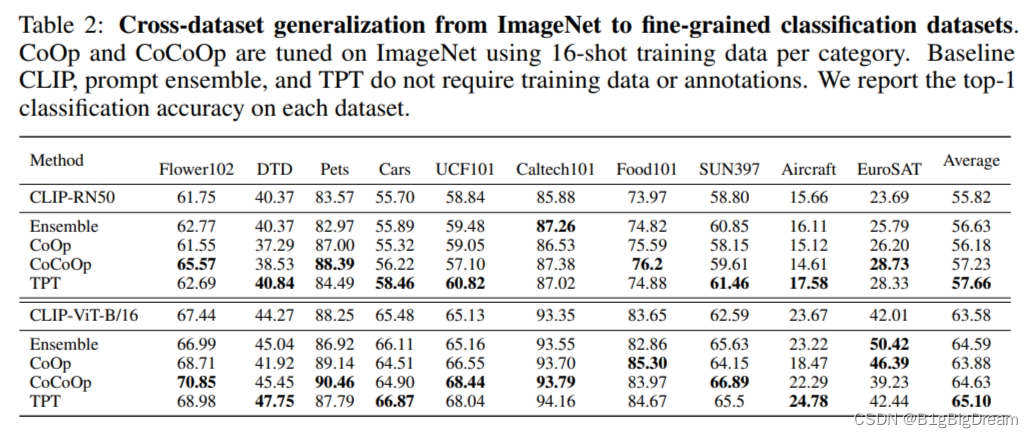
其中Ensemble应该是prompt ensemble,但是不知道是哪些集成在一起?TPT无训练平均表现比较好,CoCoOp 是基于16shot的。
消融实验:Test-time optimization on different parameter groups of CLIP
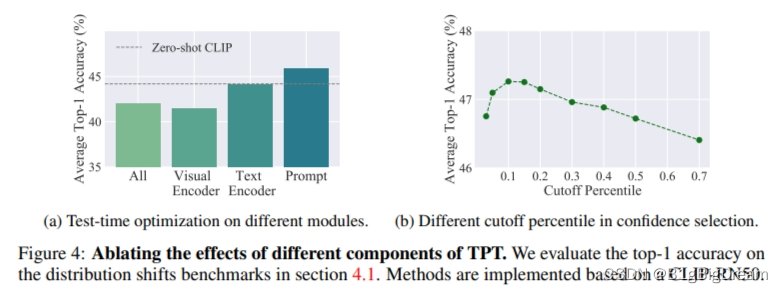
In Figure 4 (a), we evaluate different design choices of test-time optimization on CLIP. Inspired by MEMO [44], a single-point test-time optimization method that optimizes the entire network, we consider four different parameter groups: 1) the entire model, 2) the text encoder, 3) the visual encoder, and 4) the text prompt. For a fair comparison, we adopt the same setup as MEMO, using AugMix [67] as the data augmentation. Confidence selection is not used in this ablation study. For each design choice, we run a grid search for hyper-parameter tuning (on the learning rate and the number of optimization steps) and report the best result. From the results, we see that optimizing text prompts achieves the most performance gain compared to other parameter groups. In addition, we find optimizing the visual encoder to have the worst result. This observation is in alignment with previous work that suggests fine-tuning the image encoder can distort pre-trained features [68, 51].
Conclusion
此方法在zs上的表现比训练数据的提示SOTA方法要好很多,思维也从原有的TextEncode 的prompt的调整转移到了ImageEncode的训练。此外,在类被选择上选用了vote的思想。我认为这一部分是可以进一步的改进的,原有的机器学习无监督的方法是可以应用于此进行更好的应用。
本文的缺点:
1)当类别过多时,显存的占用空间会逐步的膨大。 100类时,显存的占用为5G,如400类左右时,显存占用为13G左右,类别为1000类时,显存占用为20G左右。一方面,这个与prompt有关,需要保存个维度的文本特征 ,其中C表示类别,prompt_tokens表示的是每个prompt的编码数。另一方面,设定增广的视图的特征为K,图像为N个。则矩阵的空间就从原有的 prompt_tokens x N 转变为
,则所需要的内存和显存都不小。(有点重复采样的嫌疑,哈哈哈)
2)有backpropagation调整prompt,作者文章强调说这个backpropagation这个是主要的原因增加运行时间和内存。(在实际的使用中,我测试了sun397 400类,内存大小大概是5G左右,显存是12.5G左右。)这些操作比起原生态的ZSCLIP效率要低一些。
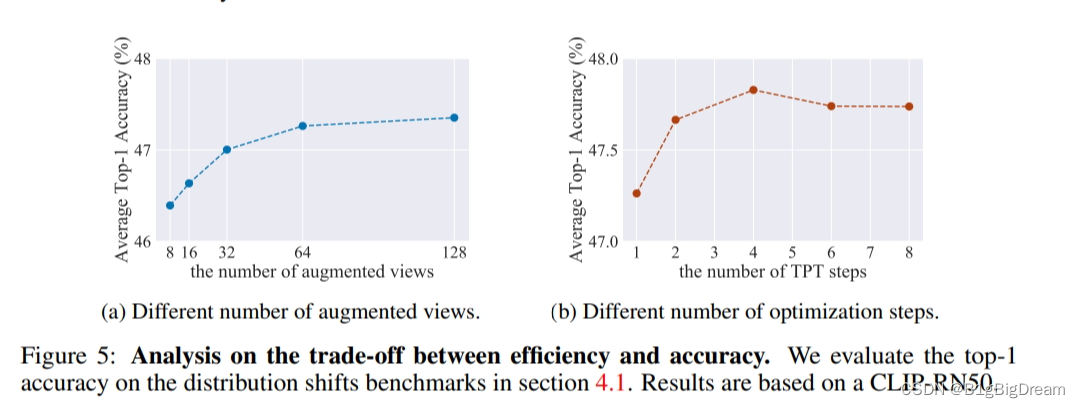
作者放图1来表示效率和精度对比。横坐标是指augmented的数量,这里记一下zsclip精度应该是44.18.所以aug =8时候就超过了2个多点把。64的时候是差不多已经接近收敛了,且总体增加也不多。TPT的设置1的话也已经高两个多点了,2应该是协调的比较好的,后续的增长意义是不大了。 尽管如此,但是图五也没有较好的说明上述存在的缺点的具体情况。
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









