






Bang Yang1,2∗ , Fenglin Liu3∗ , Xian Wu4 , Yaowei Wang2 , Xu Sun5† , and Yuexian Zou1† 1ADSPLAB, School of ECE, Peking University 2Peng Cheng Laboratory
Abstract
监督视觉描述模型需要大量成对的图像或视频与描述具体语言用于描述。收集大尺度信息是耗时耗力的,因此,成对的标记基本不适用。为了解决标记短缺的问题。我们提出了一个简单且有效的zero-shot方法-MultiCapCLIP 方法,可以生成不同场景和语言下的视觉描述,且不需要任何成对标记的下游数据集。在训练阶段,MultiCapCLIP 只需要文本输入数据。主要有两部分:**重建提示概念可以保存对应新场景下的域知识库**;2.**自动编码提示词用于学习输出描述用一种期望的语言**。在测试阶段,**MultiCapCLIP采用任务视觉数据作为输入取代直接取回概念提示 生成最后的视觉描述。** 在图片和视频描述测试了四个数据集和四种语言表明该方法的有效性。 相对于zero-shot and wakly-supervised SOTA方法,本模型取得了4.8% 和21.5% 的提升在BLEU@4和CIDEr。
[code](https://github.com/yangbang18/MultiCapCLIP)
[paper](https://arxiv.org/pdf/2308.13218.pdf)
Motivated
CILP 在zero-shot captioning 上存在两个重要的问题:域视觉知识的理解和具体写作风格和语言下的描述性句子的生成; 提出一个prompt-based 自编码器。引入视觉概念的提示 保留zero-shot视觉描述对应的域知识和写作风格。
方案: 在训练期间,输入文本数据,训练模型重建描述的自编码管道。 模型训练没有标记的文本数据,自动编码器可以自动化的重建相同的输入句子。 在重建的过程中,模型有能力保留必须的域知识和生成视觉描述的风格。 在推理阶段 可以直接将视觉输入V作为query用于取回保留的域知识依靠学习的写作风格在某具体的语言风格中的解码器来生成视觉描述。过程为
线路。
同时,为了进一步弥补视觉和文本数据见模态之间的差异性。我们引入了一个扩增方法,包含了输入增广和特征增广,我们可以扩增模型的鲁棒性用于提升zero-shot 视觉描述的表现性能。
Innovations
1.我们提出了一个简单但有效的MultiCapCLIP 这个不需要下游标记数据区尝试zero-shot 多语言视觉描述。
2.MultiCapCLIP第一个引入了visual concept prompts 用于保留域知识,和自编码他们用于学习描述的写作风格。在单文本训练之后,我们的方法可以从text to text 迁移到vision to text的生成。
3.横跨不同语言的图片和视频的描述 在域外和域内的经验表明该方法训练在文本数据上的输出表现超过了先前的zero-shot/weakly-supervised 方法(训练在不配对或部分配对的视觉和文本数据上的方法),是新的sota方法。
Approach
MultiCapCLIP:重点包含有两个概念:: concept prompts AND textual augmentations.

像图1 所示,multiCapCLIP (MCCLIP)由视觉和文本编码器组成的CLIP和一个可训练的MLM(Multilingual Language Model). 其中MCCLIP支持英文文本,图片,视频作为输入。同时可以产生输出一个想要的语言。我们重点应该关注MLM部分。
MLM:由堆叠的Transformer解码区块构成,每个区块包含了一个masked self-attention 层, 一个交叉注意力层,和一个前向层。此外,增加具体的明确信号到embedding 层来表明生成哪种语言。
详细过程,我们将文本输入写作,视觉输入作为
,Concept prompts 记作
.不像传统的视觉描述模型训练在一个视觉文本数据集,MCCLIP进依靠自编码
. 为了对齐CLIP的文本特征空间,MLCLIP使用
用于视觉描述推理。
为了扩展支持多语言的文本描述,本文使用了并行的成对的语料库(S,T)T表示目标所需要的语言。所以MLCLIP遵循的时的翻译管道。在接下来我们将详细阐述如何提取和作用P。同时介绍扩增的方法。
Concept Prompts (解码)
提取文本数据集的名词同时选择最频繁的1000名词短语作为视觉概念,这个时第一个embedded进prompt 模板的概念,丢入CLIP中的文本编码器用于提取L2-normalized 的Concept features
.在训练过程中,对输入的文本
,我们编码S进入全局特征
.具体的表达如公式1
然后将 cos 表示器余弦相似度。我们就得到soft concept prompts P, 一个子集
包含由K个概念特征与
相似。
假定CLIP的维度输出是, 则P的形状是
, 为了提示MLM。嵌入了目标文本S,得到最后的MLM输入embedding。
其中表示layer normlization 后接的一个全连接层。
表示LN后的所有
位置、语言、embedding后求和。所以提示序列由
生成,token序列由
生成。 然后将信息送入MLM进行解码。
此外,作者认为中会存在一定信息,采用
网络,其结构与
一样,得到输出
再将其与
做CA 交叉注意力。
本文采用交叉熵来训练MLM模型。 其公式如。
其中表示MLM的预测的所有词汇的分布。
表示所有训练的参数
推理阶段,通过处理视觉输入V做一个相似的处理,我们使用CLIP‘s图片编码器用于获取V的向量表征
以及基于图片-概念相关联的概念提示P. 给定先前生成的文本
,下一个token的预测是基于如下的预测的概率分布。
总结:如图2所示。 其中P表示Concept Prompts;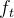 表示CLIP输出。
表示CLIP输出。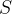 表示源文本,经过embedding 和position embedding , language embedding也就是
表示源文本,经过embedding 和position embedding , language embedding也就是 。
。

(Input Augment && Feature Augment)扩增方法
本文是方法的提出有一个重要的前提假设 是在CLIP空间中视觉和文本数据是成对及很好对齐的。 然而实际上在Liang et al2022中表明了CLIP-like模型上存在模态差异。受到除噪自编码器的启发,我们提出训练了MCCLIP模型用augmented.这里考虑了Input Augment 和Feature augmentation。具体的,采用IA采用语义相近的来替代源文本S作为输入来获取
。其中
,其中,
表示S中候选的集合。相似的
用以测量数据间文本的相似性,选择最相似的N-1文本用以构建每一个S的
。在选取时采用均匀分布进行采样,每个样本的概率是1/N. 针对FA,通过添加
高斯噪声进入文本特征中。所以整体的扩增方法为
.鼓励模型学习更多鲁棒性的隐变量表征。
Dataset


Result
out of domain

in domain visual captioning results

还有些结果请各位看官移步论文了
Conclusion
这篇文章基于CLIP的基础上进行扩展的,也是基于CapCLIP上进行扩展的,其基于的核心假设的前提是CLIP中的图像编码器和文本编码器特征是相似的 或者相关联的。本文于是设计了一个text的decoder结构也就是MLM。通过训练对文本的翻译或者解码来实现对图像的多语言的描述。这个前提的设想比较朴素,此外,作者在论文中也提到了实际上图像编码器的特征信息与文本编码器的特征信息是存在模态gap的。增加了FA和IA的结构增强模型的泛化能力。总体来说属于less is more!但有些遗憾的是,这篇文章没有做消融实验, 一方面,可以验证其所加的FA和IA的有效性;另一方面,也可以验证其的和
等结构的有效性。
















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









