







 本文探讨了如何通过数据驱动的方式学习强化学习中的内在奖励和辅助任务,以提高学习效果。Satinder Singh教授介绍了Meta-Gradient框架,用于学习跨生命周期的内在奖励函数,实验表明这种方法能够捕获有用规律,促进Exploration和Exploitation,并在不同智能体和环境中迁移。此外,还提出了将发现问题作为辅助任务的架构,以通用价值函数(GVFs)为基础,通过Meta-Gradient学习更新参数,提高强化学习性能。
本文探讨了如何通过数据驱动的方式学习强化学习中的内在奖励和辅助任务,以提高学习效果。Satinder Singh教授介绍了Meta-Gradient框架,用于学习跨生命周期的内在奖励函数,实验表明这种方法能够捕获有用规律,促进Exploration和Exploitation,并在不同智能体和环境中迁移。此外,还提出了将发现问题作为辅助任务的架构,以通用价值函数(GVFs)为基础,通过Meta-Gradient学习更新参数,提高强化学习性能。
如何能够提高强化学习效果?
这是美国密西根大学教授Satinder Singh长期以来致力于解决的问题。在2020北京智源大会上,Satinder Singh教授对这个问题进行了深度阐释,他通过Meta-Gradient方法来学习发现以往强化学习智能体中需要手动设置的参数:内在奖励和辅助任务问题。

Satinder Singh从近期关于强化学习的两个研究工作出发,针对如何通过数据驱动的方式学习到内在奖励函数,他提出了一个学习跨多生命周期(Lifetime)内部奖励函数的Meta-Gradient框架,同时设计了相关实验证明学习到的内在奖励函数能够捕获有用的规律,这些规律有助于强化学习过程中的Exploration和Exploitation,并且可以迁移到到不同的学习智能体和环境中。
针对于如何在数据中发现问题作为辅助任务,他扩展通用辅助任务架构,参数化表示General Value Functions,并通过Meta-Gradient方法学习更新参数发现问题。实验证明这个方法可以快速发现问题来提高强化学习效果。
Satinder Singh,美国密西根大学教授,Deep Mind科学家,AAAI Fellow。主要研究兴趣是人工智能(AI)的传统目标,即构建能够学习在复杂、动态和不确定环境中具有广泛能力的自主智能体。目前的主要研究是将深度学习与强化学习结合起来。
整理:智源社区 吴继芳
一、“发现”的含义
什么是强化学习中的“发现”?简单的思考方式是强化学习智能体中的参数可以分成两部分:一部分参数是从数据中学习发现得到,另一部分是由研究人员根据经验手动设置。Satinder Singh教授的报告主要讨论他和他的团队如何尝试通过Meta-Gradient方法来学习发现参数。
在强化学习中,策略(Policy)函数和价值(Value)函数的参数值通常从数据中学习得到。对于那些通常手动设置的参数,如图1所示,表格中是最新论文中的一些例子以及它们的出处。这些例子都是采用Meta-Gradient方法发现参数。有些通过元学习(Meta-Laring)发现一个好的策略参数初始值。有些是用Meta-Gradient方法发现学习率(Learing Rate)和折扣因子(Discount Factor)。有些是用Meta-Gradient方法发现内在奖励(Intrinsic Rewards)和辅助任务(Auxiliary Tasks)等。
在本次报告中,Satinder Singh教授主要分享他和他的团队近期发表在ICML 2020和NeurIPS 2019中的两篇论文的相关研究工作(图1中标红的两篇)。虽然有许多不同的发现方法,比如:基于人口的方法(Population Based Method)、进化方法(Revolution Method),但是Satinder Singh教授他们只是采用启发式搜索方法发现超参数值。这次报告的重点是采用Meta-Gradient方法发现参数。
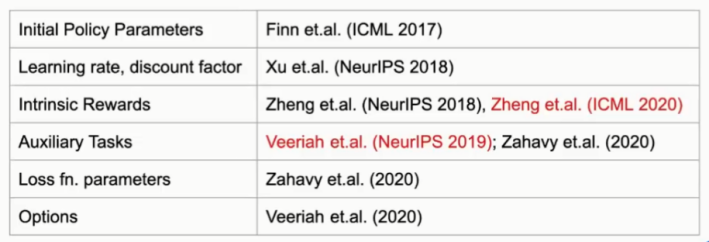
图1:手动参数的最新研究方法
二、内在奖励
第一项工作由Satinder Singh教授和他的博生生共同完成的。文章的题目是:《What can Learned Intrinsic Rewards Capture ?》[1]。
2.1 研究动机
在强化学习中,智能体有很多结构存储知识。这些结构分为:常见结构(Common Structure)和非常见结构(Uncommon Structure)。其中, 常见结构有:策略(Policies)、价值函数(Value Functions)、环境模型(Models)和状态表示(State Representations)等。在本次报告中,主要关注非常见结构:奖励函数(Reward Function)。之所以是非常见结构是因为在强化学习中这些奖励通常都是根据环境决定,并且是不可改变的。
在论文中,将强化学习问题中的奖励函数分为外在奖励(Extrinsic Rewards)和内在奖励(Intrinsic Rewards)。外在奖励用来衡量智能体的性能,通常是不能改变的。内在奖励是智能体内部的。在内在奖励中,有很多方法用来存储知识,但是这些方法都是手动设计的,比如:Reward Shaping、Novelty-Based Reward、Curiosity-Driven Reward等。这些手动的内在奖励方法都依赖领域知识或者需要细致的微调才能起作用。在本次报告中,Satinder Singh主要关注两个研究问题:
1. 是否能够通过数据驱动的方式,学习得到一个内在奖励函数?
2. 通过学习到的内在奖励函数,什么样的知
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8
8

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









