







 本文介绍了北京大学王奕森在ICLR 2021预讲会上的报告,重点关注对抗性机器学习在模型鲁棒性、隐私保护和架构方面的工作。研究团队提出了一阶稳定条件(FOSC)来度量对抗训练的优化效果,并通过对抗性权值扰动和改进的对抗性风险(MART)提升模型的鲁棒性。同时,他们还探讨了如何生成不可学习样本以保护隐私,并研究了模型架构如跳跃链接对鲁棒性的影响。
本文介绍了北京大学王奕森在ICLR 2021预讲会上的报告,重点关注对抗性机器学习在模型鲁棒性、隐私保护和架构方面的工作。研究团队提出了一阶稳定条件(FOSC)来度量对抗训练的优化效果,并通过对抗性权值扰动和改进的对抗性风险(MART)提升模型的鲁棒性。同时,他们还探讨了如何生成不可学习样本以保护隐私,并研究了模型架构如跳跃链接对鲁棒性的影响。
第九届国际学习表征大会(ICLR 2021)是深度学习领域的国际顶级会议。在正式会议召开之前,青源Seminar于2月19日-21日成功召开了ICLR 2021 中国预讲会。回放链接:hub.baai.ac.cn/activity/details/131
本文介绍北京大学智能科学系助理教授王奕森在预讲会上的报告:「Adversarial Machine Learning on Robustness, Privacy and Architecture」。报告中,王奕森介绍了其团队近年来从对抗性机器学习的视角出发,对模型的鲁棒性、隐私保护、模型架构等问题的研究工作。
整理:熊宇轩
审校:贾伟
近年来,机器学习技术得到了长足的发展,该技术已经被广泛应用于图像分类、语音识别、目标检测、医学诊断、无人驾驶等领域。
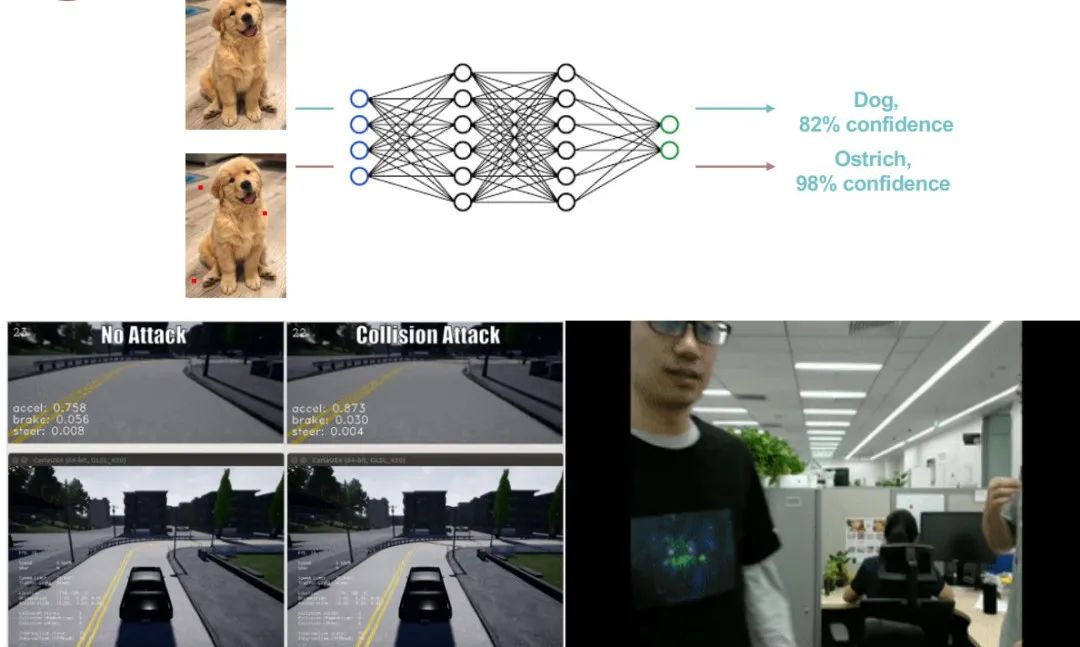
图 1:机器学习系统存在的问题——对抗样本
但是,在实际应用场景下,机器学习技术仍然存在一些不足。如图 1 所示,在正常情况下,神经网络模型能将包含「狗」的图像正确分类。然而,如果我们对红色亮点所在的像素点进行一些修改,尽管人还是可以对该图像进行正确分类,但是神经网络模型则可能将该图片错误分类为「鸵鸟」。
而在更加敏感的领域中,这种模型鲁棒性差的现象则会造成更严重的影响。例如,在自动驾驶领域中,道路中的阴影可能会使汽车错误判断路线,导致汽车「撞墙」;而在视频监控领域中,人衣服上的图案则有可能使模型无法检测到有人的出现,从而使监控画面中的人「隐身」。我们将上述使机器学习系统失效的数据称为「对抗样本」。
为了更加合理、安全地使用机器学习系统,我们需要重新思考机器学习系统工作的方式,可以将机器学习存在对抗样本的问题视为一种机器学习解决方案的「压力测试」。

图 2:对抗性样本示例
就数字空间的白盒对抗样本而言,模型的训练实际上是一个经验风险最小化(ERM)的过程,而对抗性攻击则要求我们反过来在某种限制条件下最大化损失函数。为了保证对抗性样本 和正常样本 无法轻易被人类区分开来,因此我们要求二者的 L-p 范数上界为某个较小的值 。例如,在 CIFAR-10 数据集上,我们往往采取 8 个像素点上的扰动,即。针对上述对抗性攻击,我们通常有两种常用的优化方式:(1)Fast Gradient Sign Method(FGSM):无穷范数情况下的最速下降(2)Projected Gradient Descent(PGD):迭代化的 FGSM。

图 3:对抗训练
为了让模型更加鲁棒,一个直观的想法是:将对抗样本加入到训练过程中(即对抗训练)。如图 3 所示,对抗性训练是一种最小最大优化(minmax)过程,内层的最大化过程被用于生成对抗样本(注:这是一种带约束的优化问题),而外层的最小化过程则使用内层最大化部分生成的对抗样本进行 ERM 模型训练。
01
用于提升模型鲁棒性的对抗性学习

图 4:最大化过程的收敛评分
直观地说,我们认为内层最大化过程的优化结果对外层 ERM 训练的结果具有很大的影响。然而,目前仍然缺乏有效的度量指标衡量内层优化过程的效果。
为此,王奕森博士团队在 ICML 2019 发表了论文「On the Convergence and Robustness of Adversarial Training」,提出了名为「一阶稳定条件」(FOSC)的内层最大化过程的优化效果度量指标,它可以帮助 Danskin 定理更好地成立。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 23
23

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









