







智源导读:人类的视觉系统经过百万年的进化已具有非常强大的功能,甚至是一种未受到充分赏识的超能力。人类之所以在视觉上表现如此优异,一方面归功于人类的进化史,另一方面是因为我们的大脑投入了很大一部分来实现视觉:人类的视觉皮层约占大脑皮层的40%。视觉功能不同于围棋、象棋这类竞赛游戏能力,我们玩这类游戏的能力一定程度上是我们一般智力形式的产物,每个人都必须经过学习才有擅长这类游戏的能力,但人人都非常擅长视觉。
目前AI领域已取得了一些令人振奋的重大进展,一些国家和地区已开启了长达20年的AI研究计划来实现和提升AI技术,但人工智能真的如同一些人吹捧的那样是所谓的“超人”吗?对此,约翰霍普金斯大学认知科学系和计算机科学系Bloomberg特聘教授Alan Yuille教授认为有几个重要的问题需要弄清楚:
l 目前的AI到底有多出色?
l AI与人类智能相比表现如何?
l 如何令AI表现更佳?
2021年智源大会“人工智能的认知神经基础”主题论坛上,Alan Yuille教授从四个方面阐述了为什么未来AI视觉需要学习和吸收来自对人类视觉的研究,以及如何基于人类视觉感知机理设计和评估机器视觉算法以促进类脑视觉系统的创新研究。
整理:智源研究院「人工智能的认知神经基础」重大方向博士后陈路瑶, 张博

Alan Yuille博士是约翰霍普金斯大学认知科学系和计算机科学系布鲁姆伯格杰出教授(Bloomberg distinguished professor)。他早年曾在剑桥大学跟随斯蒂芬·霍金教授,获理论物理博士,之后转而开拓计算机视觉领域。Alan Yuille博士曾获得计算机视觉论文最高奖马尔奖,也是计算机视觉顶级会议电气和电子工程师协会国际计算机视觉与模式识别会议(CVPR)的主席 ,是计算机视觉界的权威。
01
AI视觉是超人吗?
乍一看,AI视觉似乎的确具有超越人类的识别能力,这主要表现在AI视觉在ImageNet挑战赛上的表现。如图1A所示,ImageNet是斯坦福大学李飞飞教授开发的包含了数百万张图片以及1000多种不同物体的数据集,我们可以通过图1B看到人工智能算法在物体分类方面的性能是如何随着时间的推移而提高的。
到2012年,Geoffrey Hinton团队的AlexNet深度网络的识别错误率由挑战赛伊始的28%降到了16%。而随着时间的推移,性能进一步提升到错误率为3.6%、3%和2017年的2.25%,作为对照,人类的表现大约是5%。因此,单从这个图表的角度你可能会认为 2015年人工智能的表现已经超越了人类。
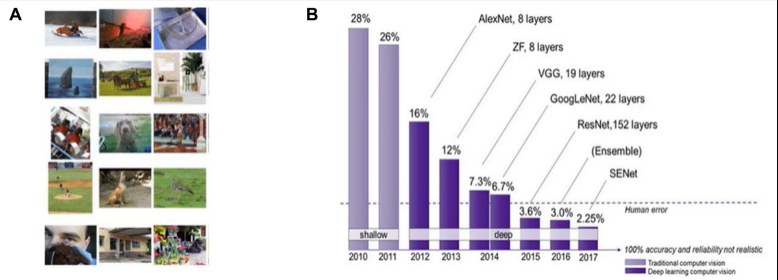
图1 ImageNet示例及人工智能算法在ImageNet数据集的性能表现
但事实上并非如此,比如,深度网络在预期外的非常规场景就很容易犯错误。如图2所示,给猴子一把吉他,猴子就被归类为人类;在企鹅旁边加一台显示器,企鹅也会被认为是人类;一只坐在吉他中间的猫会被错误地归类为摇滚明星。这些错误是由于深度神经网络无法有效的处理对抗攻击造成的。

图2 深度神经网络错误地将上图的动物识别为人类
图3是另一个例子,AI视觉算法能准确识别第一行的金属护栏、计分板、琵鹭、折叠椅和运动衫,但当我们给这些图片加上一些小的“补丁”时,这些算法便错误地将它们分别归为短尾鹦鹉、火蜥蜴、马林巴琴、水下呼吸面罩和椒盐卷饼,而这些对抗攻击并不会对人类视觉的判断造成影响。类似的对抗攻击还有很多,而现有的深度网络无法做到高效防御。

图3 AI视觉在“补丁”攻击下无法高效正确识别物体
AI视觉的另一个大问题是如何解决跨域识别(Transfer Across Domains)问题。如图4A所示,基于UCF101动作识别数据集,拳击动作可以被AI视觉成功识别,其却无法成功识别合成图4B中女拳击手。当我们看到图4A时,我们可以根据图中的拳击场以及站在拳击手之间的裁判等信息,轻易分辨出这是拳击手在进行拳击。面对图4B,虽然这不再是在拳击场,但人类仍能轻易识别出这是一个女拳击手。相较而言,如果更换了图片的场景,或者增加对抗样本,深度神经网络会在这类情况下犯一些非常低级的错误。

图4 人工智能在跨域转移时无法成功识别对象
02
人类视觉有多强大?
人类视觉能做什么呢?首先,人类视觉可以从图像中提取大量的信息。其次除了能从ImageNet识别和分类物体,人类视觉还可以做很多其他的任务。例如,人类视觉能根据看到的信息识别正在进行的动作,并对未来进行一定程度的预测。正如一句话所说“一张图片胜过1000个单词”,如图5所示,人类可以从这类图像中提取出大量信息:一只狐狸从树的背后出现,快速向右运动,穿过矮草,狐狸的毛发蓬松,毛发的颜色为棕色,腿部的颜色更深等等。看得越久,人类视觉智能可以从这张照片中得到的信息越多。

图5 人类视觉可以从图像中提取大量信息示例1
图6是另一个例子,略懂足球的人会意识到这是一个足球运动员,是一个前锋,他附近有一些对方后卫在试图阻止他射门,当然如果你有足够的足球专业知识,你能认出这位球员是阿根廷足球运动员利昂内尔·梅西。但是,任何稍微了解足球的人都能根据他的姿势及相对其他人的位置认出来这是一名前锋,他在带球,避开对方后卫,把球射出的过程。如果你足够细心,你能通过屏幕上的浅色白线判断出这是球网以及球门的位置。对比之下,现有的人工智能算法无法在这些图像上执行这些任务,而只能是识别出足球形状或者图5中的狐狸形象。

图6 人类视觉可以从图像中提取大量信息示例2
人类视觉不仅擅长从图片中提取出大量的信息,在面对如图2和3中的对抗攻击时,人类可以非常轻易地完成识别和分类任务。同时人类也可以执行域转移。人类视觉除了能轻松识别图4B中的女拳击手外,还可以做一些不可思议的域转移。如图7A,这是一条鱼的图像,但它不是真正的鱼,它是由自行车零件组成的。图7B是伟大作曲家贝多芬的形象,如果你仔细看到话,这幅图中的贝多芬是由许多小人的形象组成的。不论是非自然形象的鱼的图片,还是合成创造的贝多芬图片,人类都不难识别它们,并执行域转移。但是,这对于AI视觉是特别难的事情。

图7 人类视觉可以很好地完成跨域转移识别任务
当然,人类的视觉并不是完美的,人类也会被一些图像愚弄,但是这些情况很少发生。如图8A所示,看上去这位女士是把她的脚放在了月球上,但事实并非如此;图8B,看起来似乎这位男士在手掌上吹动这些人,令他们接连倒下;图8C似乎是一只眼睛,但实际上是洗涤剂气泡水在水槽中往下流。
这类图像类似于对抗性攻击,人类视觉会在这类攻击下犯错,但这些相对而言并不会经常发生。这类错误需要较为严格的对齐才可能愚弄到人类视觉,例如图8B这位男士伸开的手掌需要与滑倒的人对齐,否则就不会产生这种错觉效果。一般而言,人类视觉可以非常清楚地看到图像,而很少犯错。

图8 巧合对齐造成的错觉
另一个例外被称为“房间里的大猩猩”,如图9所示,在这个例子中,一群穿着白衬衫和黑衬衫的人在进行传球游戏,当你被要求报告穿着白衬衫的人之间传球的次数时,你会专注地执行这个任务,而忽视一个穿着大猩猩服的人在人群中走过。这是人类的一个局限,我们在看的时候可能只关注少数事情,而不关心其他事情。
事实上,这项研究受启发于一个真实案例:一名美国警察因为没有停下来制止身旁的犯罪行为而遭受控告,而那个警官解释说他当时正忙着追另一名罪犯而没有意识到眼前的这起犯罪,否则他会停下来去制止。这促使人们做这项研究并证明了警察很可能是对的,在他参与某项特定任务之时,根本没有观察到附近的另一个任务。类似的策略也被魔术师利用,观众的注意力被魔术师吸引到某件事情上,因而没能察觉到魔术师表演的把戏。我们并不希望AI视觉去复制这些人类视觉可能会犯的错误,不过通过简单地增加计算量,我们可以很容易地为AI视觉规避这类错误。

图9 注意缺失(Lack of attention)导致没能觉察到房间走过的“大猩猩”
总的来说,人类视觉可以从图像中提取的信息量远远超过现有的人工智能算法,可以执行大量的视觉任务,这其中包含了AI视觉的所有功能,以及很多其他的任务,并且在面对对抗性攻击和非常规情境时,人类视觉具有更好的鲁棒性和稳定性。此外,人类大脑在执行视觉功能时是极其高效的,当深度神经网络利用强化学习打败围棋冠军时,它所消耗的能量比围棋冠军大脑耗能高出了好几个量级。人类大脑进化而来的深层网络结构和算法非常复杂,而现有的人工神经网络算法只是对神经元的简单模拟。
03
为什么AI视觉与人类视觉存在差异?
首先,人类视觉是优于AI视觉的,那么为什么有些人认为人工智能视觉更好?如图1B提到的,到了2015年深度神经网络在ImageNet上的表现似乎就已经超越了人类视觉,这是造成人们认为人工智能比人类更好的原因。但其实,AI视觉的这种更优秀的表现,是由计算机视觉和机器学习领域当前普遍使用的研究范式造成的。当我们测试人工智能视觉算法时,我们采用的是与训练数据集类似的测试数据集,因此我们已经基本上教会了它们如何在测试数据集上去获得优秀的表现,这样的测试太简单,没有尝试去应用真实世界中复杂多变的情景给算法足够的挑战。这首先需要知道人类视觉在真实世界执行的任务,而目前我们并没有从科学层面上了解人类视觉的所有功能。
那么目前AI视觉算法的研究范式是什么呢?我们往往是采用大小有限且经过注释的数据集来训练算法,或者在一半数据集上进行学习,然后在另一半数据上评估算法的表现,事实证明这是一个非常有效的研究策略。但是相对真实世界的应用而言,这些数据集的体量不足以代表现实世界的复杂性,即使是设计良好ImageNet。这意味着数据集已经包含了算法应用的偏向,算法可以利用和适应数据集的属性。
然而在现实世界中,会有一些极端案例(corner case)发生,例如对于自动驾驶汽车而言,一个宝宝坐在马路上的场景将会是一个巨大的麻烦,算法无法识别这样的事件,因为在它的标注数据集里,就没有出现过这样的场景。当我们只是用平均表现来衡量算法的性能时,这种罕见的事件并不会明显影响算法性能的衡量结果,但在实际应用中我们绝不希望算法会在这类应用上出错。
世界如此复杂,永远不可能有一个足够大的数据集来代表所有情况,这意味着深度网络这种数据驱动的回归类型算法,无法涵盖所有的极端案例,虽然其可以依靠给定的数据集取得好的成绩。此外,目前的研究范式惠及了高科技公司的研究者,他们拥有大量数据和计算资源,目前,深度网络在工程技术和算法上的应用已经做的很好了,但面对未来的应用,我们还应该再进一步去使用更难的方法开发和测试算法。
现有研究更倾向于解决已经标注过的数据集问题,但进一步对诸如ImageNet的数据集进行标注就已经是一件足够繁杂费时的工作(譬如对图5简单地框选出狐狸),更不用说对图6这样的图片按照人类视觉可提取的信息去添加足够多的标注。因此,未来我们还有很长的路要走。
事实上,没有哪个AI视觉算法能超越人类视觉的表现。就“理想观察者”的模型而言,它似乎能在任何视觉任务上都胜过人类,但这是因为这些模型知道数据的统计特性,而人类并没有这些先验知识。深度网络还不具备思维,而是擅长利用数据集中存在的偏向,例如,深度网络认为如果树上存在物体,那么它应该是鸟,而人类不会这么认为。深度网络甚至会在没有看到物体时更准确地分类物体,如图10所示,即使这只鸟被黑框遮盖,深度网络仍能识别出来。对比而言,人类视觉会因为黑框背后可能是鸟也可能是别的物体而无法确信。

图10 即使被遮盖深度网络仍然辨别黑框里的对象,而人类视觉则无法确认
的确,诸如DeepNet等AI视觉算法已经取得了惊人的进展,我们也已经有了大量标注了的数据集和标准的性能衡量指标。但由于图像数据集有限而现实世界无比复杂,这些算法存在局限性。现有的数据集带有偏向性,而类似于“坐在马路上的婴儿”这种重要的事件很少存在于其中,因此基于这样的数据集得到的性能评价可能会过度高估了算法在现实应用中的优越性,而这不单单是学术范畴的一项研究,这种误导可能会在现实世界中带来糟糕的社会后果。
04
AI视觉的未来:像人一样看世界
鉴于以上的分析,未来我们应该挑战AI视觉算法去实现人类视觉在开放复杂环境下的认知表现,我们要去探索人类视觉可以做的是什么,并挑战算法发挥相应的潜力,而不是仅仅是简单地基于平衡注释数据集、采用标准化的性能指标去评估AI算法。例如,图11是我们课题组2019年发表的研究,相较于深度网络,人类视觉可以更好的识别被遮挡的物体,为了实现让深度网络更好的对被遮挡物体进行分类,我们开发了Generative Compositional Network,同时使用分布外数据集(Out-of-Distribution)进行测试,即采用与训练数据集有较大差异的数据集进行测试,以提升深度网络的通用性。图12是一个关于人类的微妙活动的例子,人类视觉在识别这些微妙动作时具有很高的正确率,而现有深度网络则表现得很差,大概只有20-30%的正确率。未来我们可以尝试去开发新的算法来解决这个问题。

图11 不同遮挡程度的汽车图像数据集示例

图12 AI视觉与人类视觉辨别人类微妙行为的表现
参考文献:
1. Alan Yuille and Chenxi Liu. “Deep Net: What have they ever done for Vision?” International Journal of Computer Vision. 2021.
Hongru Zhu et al. “Robust of Object Recognition under Extreme Occlusion in Humans and Computational Models”. Proc. Cognitive Science. 2019
2. Adam Kortylewski et al. “Compositional Convolutional Neural Networks: A Deep Architecture with Innate Robustness to Partial Occlusion”, Computer Vision and Pattern Recognition. 2020.
3. Vinvent Jacquot et al. “Can Deep Learning Recognize Subtle Human Activities?” Computer Vision and Pattern Recognition. 2020.
欢迎加入智源社区「计算机视觉」交流群

(更多活动信息将在交流群中同步)
















 13
13











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









