








【专栏:前沿进展】2 月 17 日,澳大利亚阿德莱德大学副教授吴琦在青源 Talk 第 12期中带来了题为「视觉-语言导航新进展:Pre-training与Sim2Real」的报告。
吴琦首先简要介绍了「视觉-语言」导航任务的发展历史,进而介绍了考虑历史信息和顺序关系的VLN 预训练方法 HOP。
由于仿真环境和现实场景存在一定的差距,吴以如何将离散环境下训练的 VLN 模型应用于连续环境为例,提出了 Sim2Real 的研究课题。
本文整理自青源Talk第十二期,视频回看地址:https://event.baai.ac.cn/activities/247
作者:吴琦
整理:熊宇轩
编辑:李梦佳
01
视觉-语言-行为
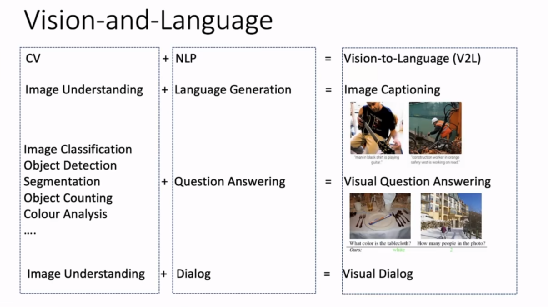
计算机视觉(CV)和自然语言处理(NLP)早先是两个较为独立的研究领域。CV 重点关注如何用计算机代替人眼对目标完成识别、跟踪、测量等任务,对图像进行处理;NLP 则研究计算机如何处理、运用自然语言,包括语言生成、问答、对话等任务。近年来,以深度神经网络为代表的机器学习和模式识别技术被广泛应用于 CV 和 NLP 领域,取得了目前最先进的效果。
人类可以同时使用视觉和语言这两方面的能力来完成一系列任务,CV 与 NLP 的结合(V2L)也成为了人工智能研究领域的重要课题,可以拓展这两个方向的重要应用。例如,将图像理解和语言生成任务结合起来构成了图像描述(image captioning)任务;将图像分类、目标检测、图像分割、目标技术、颜色分析等 CV 任务与问答任务结合起来就构成了视觉问答任务;将图像理解和对话任务结合起来就构成了视觉对话任务。
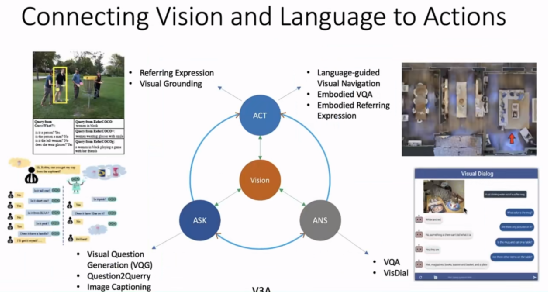
近年来,研究者们试图将动作控制也引入到「视觉-语言」任务的框架中。吴琦将此类任务命名为 V3A(Vision, Ask, Answer, Act),在给定视觉输入后,我们希望机器能够提出问题、回答问题、并通过和人以及机器之间的语言交流执行某些动作。
例如,「Vision+Ask」的任务包含视觉问题生成、根据问题生成查询、图像描述等;「Vision+Answer」的任务包含视觉问答、视觉对话等;「Vision+Act」的任务包含指称表达、视觉对齐(visual grounding)、语言引导的视觉导航、具身视觉问答、具身指称表达等。

具身人工智能是目前的一个热点研究领域,它要求智能体能够感受周围的环境,并做出相应的决策,完成看、说、听、行动、推理等任务。
02
视觉-语言导航

如上图所示,在基于视觉与语言的导航(VLN)任务中,给定自然语言指令(走出浴室。左转,通过左侧的门离开房间。在那里等待。),希望智能体在虚拟环境中理解语言指令,并遵循该指令,按照给定的路线完成导航,到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 11
11











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









