







 本文由清华刘知远探讨大模型时代的新问题,包括理论基础、架构、能效、适配性、可控性、安全性、认知能力、应用、评估和易用性等10个值得深入研究的领域。大模型的出现带来了AI研究的变革,但也带来了一系列挑战,如Transformer框架的局限、模型效率和安全性的改进等。
本文由清华刘知远探讨大模型时代的新问题,包括理论基础、架构、能效、适配性、可控性、安全性、认知能力、应用、评估和易用性等10个值得深入研究的领域。大模型的出现带来了AI研究的变革,但也带来了一系列挑战,如Transformer框架的局限、模型效率和安全性的改进等。

大模型的出现迎来了AI研究的新时代,其所带来的结果提升十分显著,超越了很多领域中针对研究问题设计特定算法实现的提升。
具体而言,预训练到Finetune的新范式最本质的特点是统一框架以及统一模型。首先,更加统一的架构,在预训练出现之前,CNN、RNN、Gate、Attention等在内的算法框架层出不穷。2017年 Transformer出现之后,取代各种流行框架的是一个统一框架。其次,这种统一框架通过预训练机制带来了统一的模型,因而我们现在可以用一个统一模型进行微调,使其同时用在非常多的下游任务上。
那么,在大模型时代有哪些新问题亟待关注和探索?
由此,我想和大家分享一下十个值得深入探索的问题。希望有更多研究者在大模型时代找到自己的研究方向。
问题如下:
1、理论:大模型的基础理论是什么?
2、架构:Transformer是终极框架吗?
3、能效:如何使大模型更加高效?
4、适配:大模型如何适配到下游任务?
5、可控性:如何实现大模型的可控生成?
6、安全性:如何改善大模型中的安全伦理问题?
7、认知:如何使大模型获得高级认知能力?
8、应用:大模型有哪些创新应用?
9、评估:如何评估大模型的性能?
10、易用性:如何降低大模型的使用门槛?
作者:刘知远
整理:李梦佳
01
理论:大模型的基础理论是什么?
首先,我认为在大模型当中第一个非常重要的问题就是它的基础理论问题。大模型的一个非常重要的特点就是可以利用非常少的下游任务数据进行相关下游任务的适配,无论是全量下游任务的训练数据还是few-shot learning,甚至zero-shot learning,都能达到相当不错的效果。同时在预训练到下游任务适配过程当中,需要要调整的参数量可以非常少,这两个特点都是大模型给我们带来的新现象。
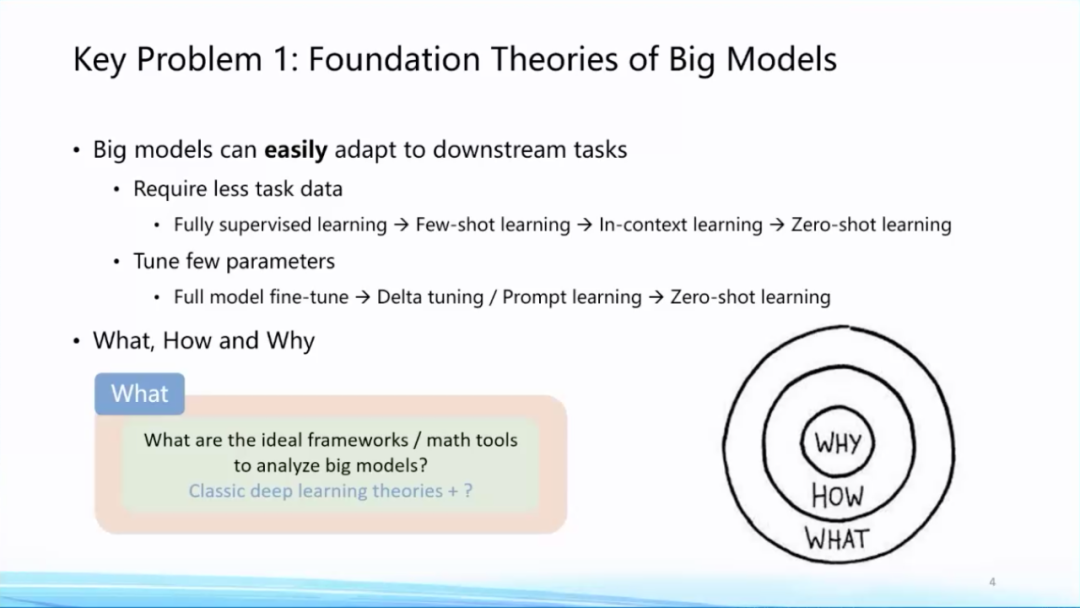
针对这个现象我们有非常多的问题可以去问:
第一,What——大模型到底是什么?我们应该有什么样比较好的数学或者分析工具对大模型进行定量分析或者理论分析,这本身就是一个非常重要的问题。
第二,How——大模型为什么好?大模型是如何做到这一点的?Pre-training和Fine-tuning是如何关联在一起的?以及大模型到底学到了什么?这些是How的问题。
最后,Why——大模型为什么会学得很好?这方面已经有一些非常重要的研究理论,包括过参数化等理论,但终极理论框架的面纱仍然没有被揭开。面向这三个方面,即What、How和Why,大模型时代有着非常多值得探索的理论问题。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 24
24

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









