







 2023年智源大会上,专家探讨了计算机视觉与大模型的最新进展,包括交互式图像编辑模型Drag Your GAN、3D内容生成技术及通用视觉模型。Drag Your GAN通过关键点拖拽实现灵活图像编辑,DMTet和Get3D等模型推动3D生成模型发展,而EVA、Painter和SegGPT则在通用视觉模型上取得进展。未来研究方向涉及多模态学习、任务统一接口和开放世界模型构建。
2023年智源大会上,专家探讨了计算机视觉与大模型的最新进展,包括交互式图像编辑模型Drag Your GAN、3D内容生成技术及通用视觉模型。Drag Your GAN通过关键点拖拽实现灵活图像编辑,DMTet和Get3D等模型推动3D生成模型发展,而EVA、Painter和SegGPT则在通用视觉模型上取得进展。未来研究方向涉及多模态学习、任务统一接口和开放世界模型构建。
导读
6 月 9 日下午,智源大会「视觉与多模态大模型」专题论坛如期举行。随着 stable diffusion、midjourney、SAM 等爆火应用相继问世,AIGC 和计算机视觉与大模型的结合成为了新的「风口」。本次研讨会由智源研究院访问首席科学家颜水成和马尔奖获得者曹越共同担任论坛主席,由北京交通大学教授魏云超主持。本论坛邀请了来自南洋理工大学、NVIDIA、智源研究院等国内外知名研究机构的顶尖学者共聚一堂,报告的内容涵盖生成模型、3D 视觉、通用视觉模型设计。以下是核心内容整理:
Drag Your GAN: Interactive Point-based Manipulation
on the Generative Image Manifold
潘新钢 | 南洋理工大学计算机科学与工程系助理教授
图像编辑(Image Manipulation)一直以来火热的研究方向,而且具有很广泛的应用场景。现有的图像编辑主要有以下四类:
(1)基于全监督学习的模型,如InterfaceGAN;
(2)基于语义分割图的模型,如SPADE;
(3)基于人体关键点的模型,如HumanGAN;
(4)基于文本引导的模型,如Imagic。然而现有的这些模型缺乏对空间属性编辑的灵活性,准确性,通用性。以皮影戏为例,通过控制皮影人物的关键点,可以做出各种各样的动作。
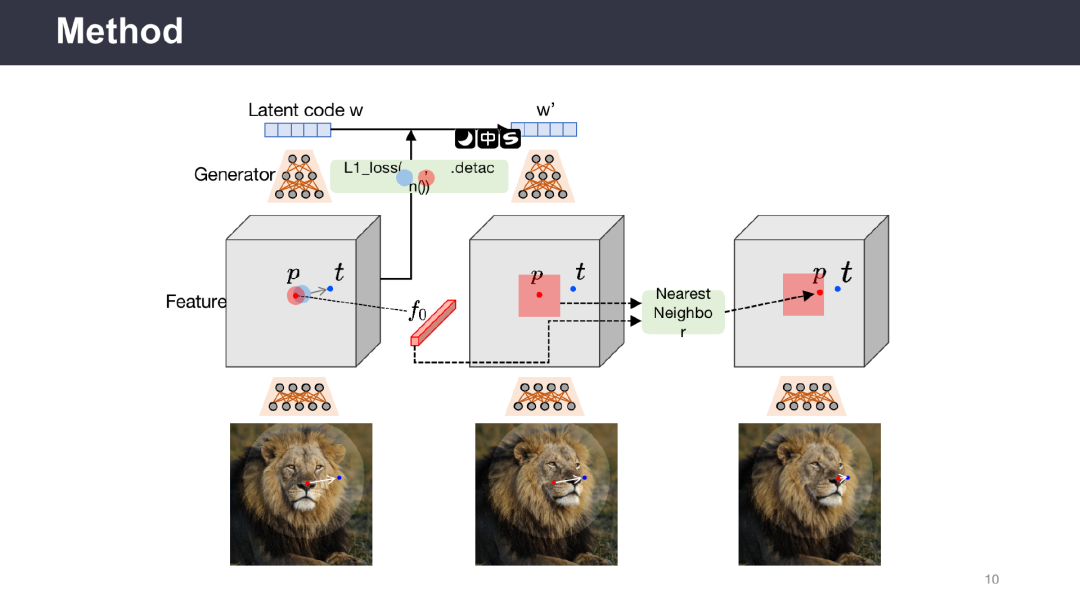
为了让模型在具有利用关键点能力的同时,并可以在编辑图像时推理出被遮挡的区域,潘新钢教授团队提出了一种基于生成对抗网络(Generative Adversarial Networks,GAN)的实时交互式图像编辑模型Drag Your GAN。用户在图像上确定抓取点(Handle Point)和目标点(Target Point),将图像与点信息一起输入到生成器中获取隐向量(Latent Code),该模型通过使用多步式迭代并在每一步迭代过程中使用动态监督损失函数,逐步优化隐向量,直至抓取点逐步移动到目标点。此外,用户可以选择修改区域,只编辑区域内的部分。通过在多个数据集上验证,展现了Drag Your GAN模型强大的图像编辑能力。

该报告介绍了通过交互式关键点拖拽的方式来编辑图像的生成式模型Drag Your GAN,改模型的核心为关键点动态监督和关键点跟踪。最后,潘新钢教授表示,通过文本引导和拖拽关键点相结合的方式将会引领图像编辑领域的未来。
将机器学习用于 3D 内容生成
高俊 | NVIDIA 研究科学家

人类生活在三维世界中,创作三维的虚拟数字世界,有助于人类更好地理解世界、解决现实生活中无法解决的问题。
生成的三维虚拟场景需要满足以下要求:
(1)物体数量足够多
(2)物体类型多样
(3)质量高,包含几何信息、纹理信息
工业界现有的依赖人工的三维世界创建方案要消耗大量人力物力,对操作者的能力要求较高,难以大规模扩展。Dreamfusion 等基于深度学习的三位视觉生成方法在几何和纹理细节生成方面仍有很大提升空间。
三
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1
1

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









