








导读
今年早些时候,OpenAI宣布成立了一支专注于超级对齐的新团队,由Jan Leike和IIya Sutskever领导,超级对齐旨在构建一个能够与人类水平相媲美的自动对齐研究器。其目标是尽可能地将与对齐相关的工作交由自动系统完成。
其中一个重要手段就是可扩展监督(Scalable Oversight),即在确保模型能力超过人类水平后,仍旧能够与人类期望保持一致、持续地进行改进和学习。可扩展监督的重点是如何向模型持续提供可靠的监督,这种监督可以通过标签、奖励信号或批评等各种形式呈现。随着AI不断进步,RLHF可能会逐渐失效,人类评估模型的能力遭遇瓶颈。如何判断可扩展监督正在发挥作用?可扩展监督的目标是什么?在近期由青源会主办的「超级对齐」闭门研讨会上,OpenAI超级对齐负责人Jan Leike讲解了如何利用可扩展监督来解决对齐难题。

Jan Leike
OpenAI 超级对齐团队负责人,研究方向为强化学习,大语言模型的对齐engineering,通用人工智能等。2016 年加入谷歌 DeepMind 团队从事人类反馈强化学习(RLHF)相关研究,现领导 OpenAI 对齐团队,旨在设计高性能、可扩展、通用的、符合人类意图的机器学习算法,使用人类反馈训练人工智能,训练人工智能系统协助人类评估,训练人工智能系统进行对齐研究。
关于对齐问题,我已经思考10年之久。在OpenAI,我与 Ilya Sutskever 共同领导了超级对齐团队,并深度参与了一些项目,包括RLHF原始论文、InstructGPT、ChatGPT 和 GPT-4 的对齐项目。目前超级对齐的目标是弄清楚如何对齐超级智能,因此系统必须比人类更聪明。我们希望在四年内,利用OpenAI 20%的算力解决超级对齐的问题。

在超级对齐团队中,我们正在开展一系列不同的项目,这里我想重点讨论下可扩展监督(scalable oversight),这是解决对齐问题较为自然的方法之一。当然还有很多关于泛化、可解释性和训练模型机制的工作。
什么是可扩展监督
为了促进可扩展的监督,我们从整体上考虑对齐的方式。如图所示,随着AI不断进步,它将能够解决越来越困难的任务。但默认情况下,人类评估任务的能力不会随着人工智能的进步而提升。
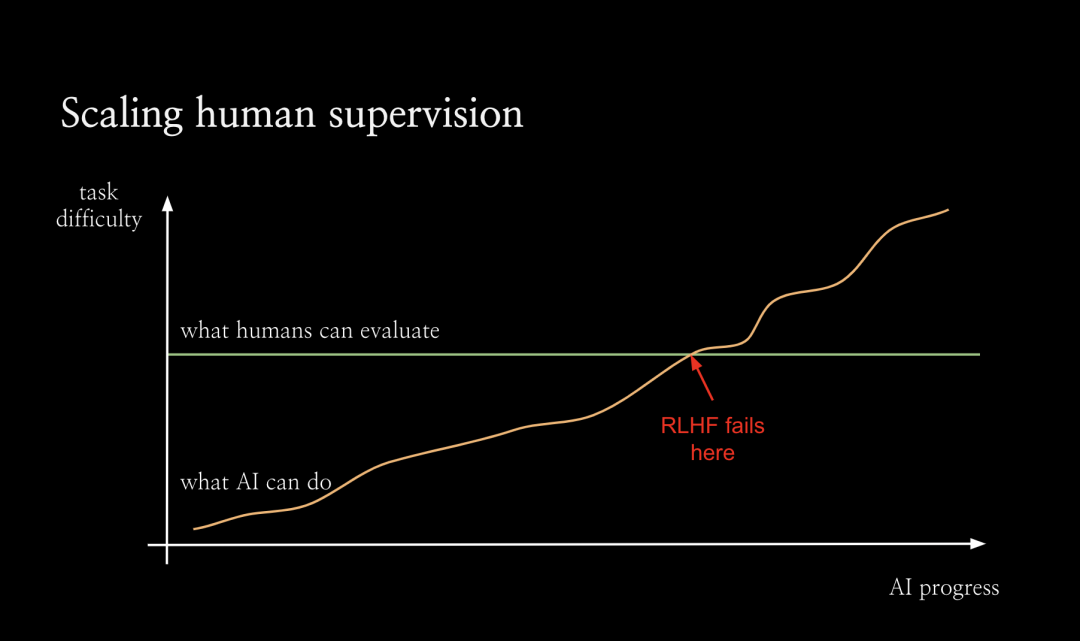
从某一个临界点开始,人类将无法再可靠地评估人工智能系统。我认为,正是从这个点开始,RLHF失效了,因为人类将无法再为人工智能系统提供良好的训练信号了。因此从这个点之后,我们需要很大程度上依赖新的对齐技术,而这些技术尚未证明,手段也未知。
我将其称为对齐的难题:我们在对齐如大语言模型之类的AI系统方面取得了很大进展,但真正的挑战是对于那些过于复杂无法直接评估的任务上如何对齐系统。
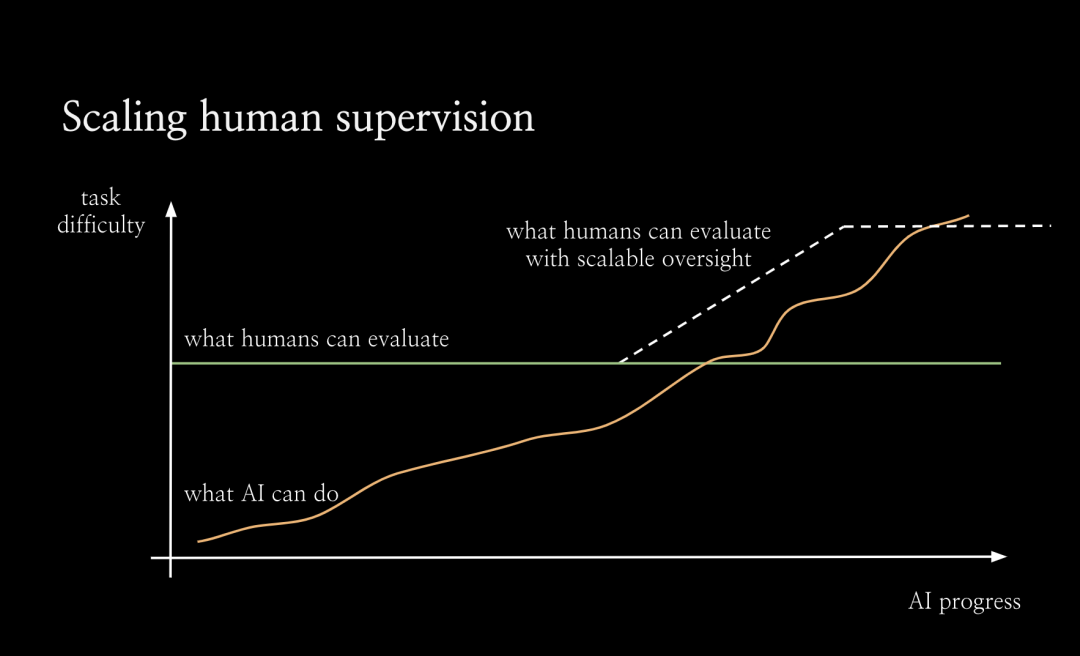
因此我
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 36
36

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









