







摘要:互联网上有很多丰富的信息可以被抓取并转换成有价值的数据集,然后用于不同的行业。比如企业用户利用电商平台数据进行商业分析,学校的师生利用网络数据进行科研分析等等。那么,除了一些公司提供的一些官方公开数据集之外,我们应该在哪里获取数据呢?
作为数据分析的核心,网路爬虫从作为一个新兴技术到目前应用于众多行业,已经走了很长的道路。互联网上有很多丰富的信息可以被抓取并转换成有价值的数据集,然后用于不同的行业。比如企业用户利用电商平台数据进行商业分析,学校的师生利用网络数据进行科研分析等等。那么,除了一些公司提供的一些官方公开数据集之外,我们应该在哪里获取数据呢?其实,我们可以建立一个网路爬虫去抓取网页上的数据。
网络爬虫的基本结构及工作流程
网络爬虫是捜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份。
一个通用的网络爬虫的框架如图所示:
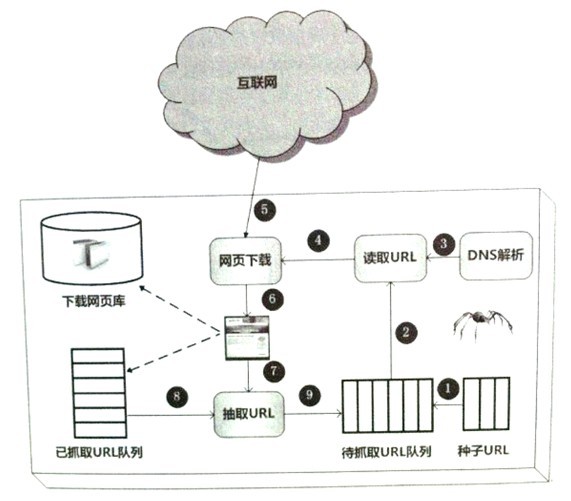
网络爬虫的基本工作流程如下:
1、首先选取一部分精心挑选的种子URL;
2、将这些URL放入待抓取URL队列;
3、从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1665
1665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









