







 本文介绍了网络爬虫的历史,从万维网的诞生到网页爬虫、搜索引擎的发展,再到Python Beautiful Soup等工具的出现。随着网页API和可视化网络爬虫软件的普及,网络抓取已成为主流。未来,网络爬虫将在数据获取和处理中扮演更重要角色,同时也面临法律和道德的挑战。
本文介绍了网络爬虫的历史,从万维网的诞生到网页爬虫、搜索引擎的发展,再到Python Beautiful Soup等工具的出现。随着网页API和可视化网络爬虫软件的普及,网络抓取已成为主流。未来,网络爬虫将在数据获取和处理中扮演更重要角色,同时也面临法律和道德的挑战。

什么是网络爬虫?
网络爬虫,也称为网页抓取和网页数据提取,基本上是指通过超文本传输协议(HTTP)或通过网页浏览器获取万维网上可用的数据。(摘自Wikipedia)
网页数据爬取是如何工作的?
通常,爬取网页数据时,只需要2个步骤。
打开网页→将具体的数据从网页中复制并导出到表格或数据库中。
这一切是如何开始的?
尽管对许多人来说,网络爬虫听起来像是“大数据”或“机器学习”一类的新概念,但实际上,网络数据抓取的历史要长得多,可以追溯到万维网(或通俗的“互联网”)诞生之时。
一开始,互联网还没有搜索。在搜索引擎被开发出来之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这些站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制作索引。
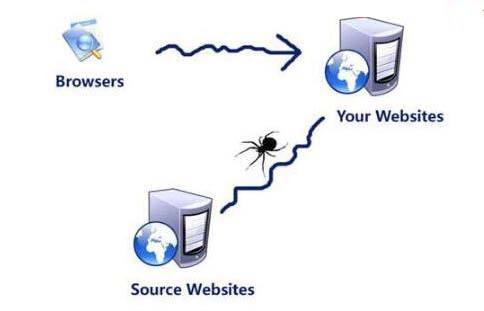
随后,互联网发展起来,最终有数百万级的网页生成,这些网页包含大量不同的形式的数据,其中包括文本、图像、视频和音频。互联网变成了一个开放的数据源。
随着数据资源变得非常丰富且容易搜索,人们发现从网页上找到他们想要的信息是一件非常简单的事情,他们通常分布在大量的网站上。但另一个问题出现了,当他们想要数据的时候,并非每个网站都提供下载按钮,如果进行手动复制显然是非常低效且乏味的。

这就是网络爬虫诞生的原因。网络爬虫实际上是由网页机器人/爬虫驱动的,其功能与搜索引擎相同。简单来说就是,抓取和复制。唯一的不同可能是规模。网络数据抓
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









