







作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
情感分析的方法包括基于情感词典的方法,有监督的机器学习方法和无监督的机器学习方法。基于情感词典的情感分析方法就是通过构建一个包含各类情绪的情感词典,制定评价规则,对文本进行拆句、分析及匹配词典,通过分析文本中的正向情感词和负向情感词数目来计算情感值,从而得到每部电影正向、负向和中立情绪的比例,最后以情感值来作为文本评论数据情感倾向判断的依据。机器学习的方法需要的是大量人工标注的语料作为训练集,运用机器学习或算法等方式训练模型,得出模型后再用来分类判断新本文的情感倾向。
本文研究工作的线路规划:
1、构建Python爬虫来爬取豆瓣的影评数据,经过数据分词和词性标注,其中的词性标注要是弱标注。
2、以HowNet和NTDSP为基础,PMI为技术来制作电影领域的情感词典,根据情感词典来找到情感词并标注它的位置,再向前查找否定词和程度副词,在计算情感值。
3、通过支持向量机SVM来进行分类,以Accuracy来评价最终的分类效果,再用词云图和分析表来呈现所计算各种结果。
本系统主要基于下述论文进行实现和改造,如果想要进一步了解的可以参考下面的论文思想。

系统实施的工作介绍:
本项目主要内容是构建爬虫基于豆瓣获取《流浪地球》和《飞驰人生》的电影评论数据,进而分析、挖掘原始数据集,构造电影评论数据集领域内个的情感词典并结合用户评分数据作为弱标注信息来实现影评数据的自动标注,节省人力成本,最后基于支持向量机 SVM模型完成影评数据的情感分析工作。
系统设计架构示意图如下图所示:
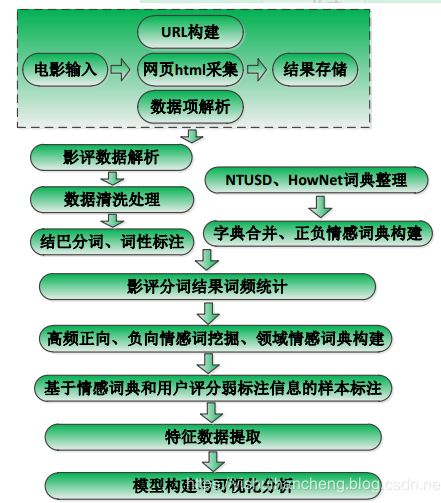
各模块功能介绍分析如下:
1、 第一部分是数据获取,主要是编写爬虫来完成指定电影数据的爬取与存储。
2、 对获取到的数据进行清洗处理,解析成我们更加方便使用的json 数据对象。
3、 对解析处理后的数据中的评论信息进行 jieba 分词处理,分词同时进行词性标注。
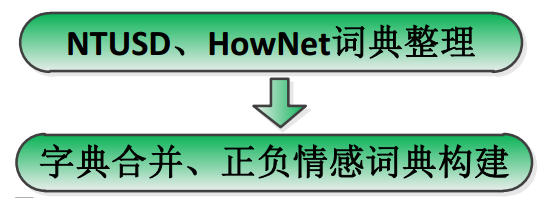
4、 获取 NTUSD 和 HowNet 情感词典并合并去重处理得到基础情感词典数据。
5、 基于高频词汇的挖掘生成 Topk 个电影影评数据中正向、负向的清单词典。
6、 完成新词的情感倾向计算。
7、 基于影评数据的情感倾向于用户的评分数据综合实现样本数据的标注。
8、 完成指定五个维度特征数据的抽取。
9、 构建 SVM 模型进行训练和分类测试,计算评估指标并进行可视化展示。
结束了上述整体和各个模块的介绍之后,接下来开始讲解模块的实现,首先看数据获取模块,爬取启动代码如下所示:

上述代码实现了对我们目标《流浪地球》和《飞驰人生》两部电影影评数据的爬取,都是今年贺岁片中的爆款电影啊!
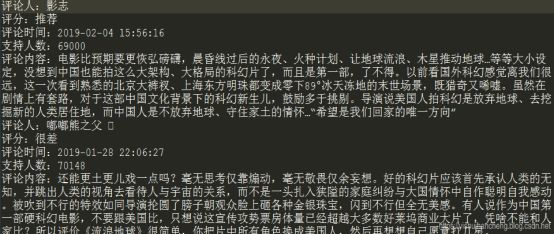
部分影评数据截图如下所示:
《流浪地球》
《飞驰人生》
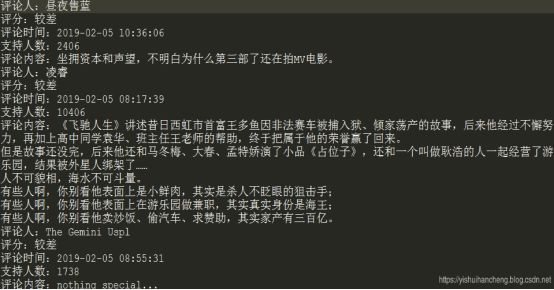
接下来是数据解析与jieba分词处理,部分结果截图如下:
《流浪地球》

《飞驰人生》

分词处理的同时需要做的就是情感词典的构建,这里直接从网上下载对应的数据合并处理构建字典即可,这里就不做过多的介绍了,如下:
接下来是对分词结果进行词频统计,部分结果数据如下:
《流浪地球》

《飞驰人生》

接下来是基于PMI方法实现高频正向、负向的情感词挖掘处理,以此来构建电影影评数据领域内的情感词典,如果做的的是其他领域内文本数据的分词也可以参照此方法处理。
领域情感词典构建具体实现代码如下所示:
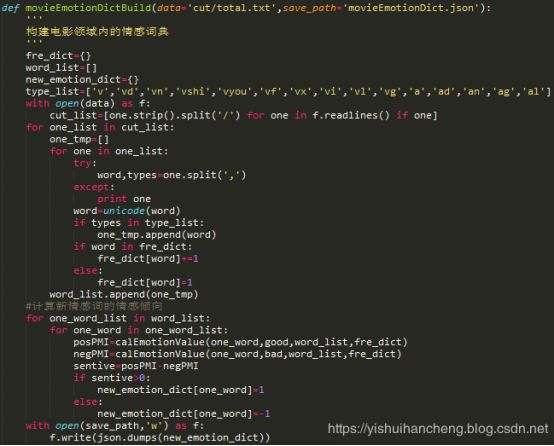
完成领域情感词典构建后就可以基于该情感词典和用户的评分弱标注信息来对原始的样本数据进行标注处理了。由于代码较多,这里展示部分代码实现如下所示:
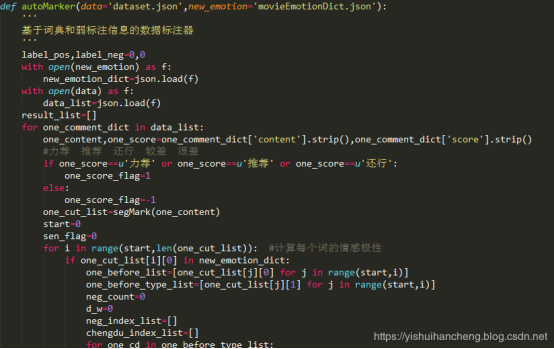
完成上述两种方式结合的样本数据标注处理之后就可以进行文本数据的特征抽取工作了,特征抽取部分实现代码如下所示:
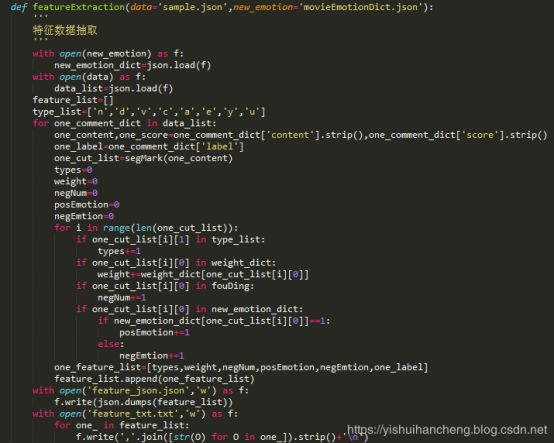
上述代码实现的特征数据的抽取与向量化工作,最后就可以进行模型的构建、测试与结果可视化分析了。
影评数据的慈云可视化分析结果如下:
《流浪地球》

《飞驰人生》

之后系统基于LDA主题挖掘模型对影评数据实现了主题挖掘,可视化分析结果如下:
《流浪地球》

《飞驰人生》

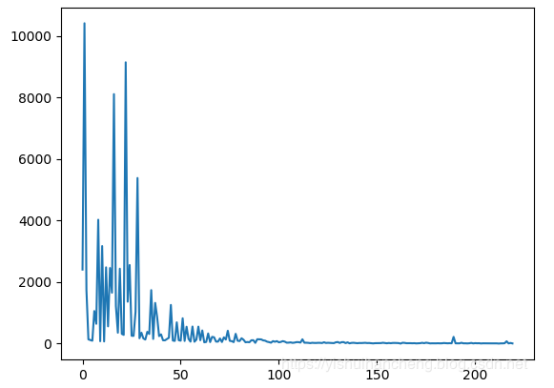
之后对两部影视作品的支持量曲线做了可视化,分别如下所示:
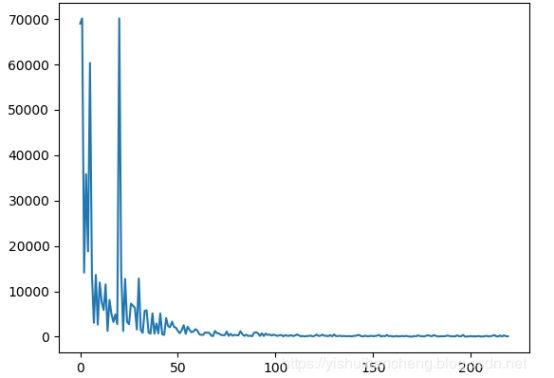
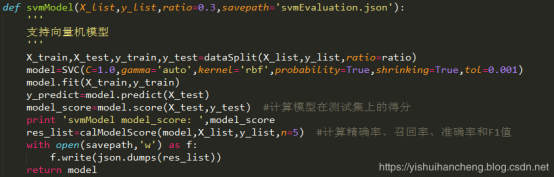
模型构建部分本系统使用的是svm模型,模型部分代码实现如下所示:
模型分类结果四大评估指标计算结果如下:
{"recall": 1.0, "F_value": 0.8979477087433231, "precision": 0.814795918367347, "accuracy": 0.814795918367347}
可视化如下图所示:
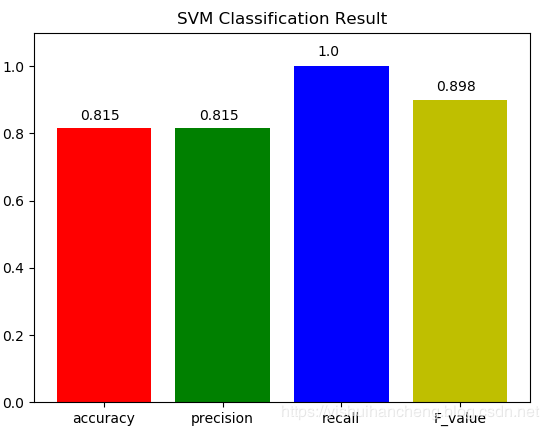
从各个指标综合来看:模型的分类精度还是不错的。到这里本文的工作就结束了,很高兴在自己温习回顾知识的同时能写下点分享的东西出来,如果说您觉得我的内容还可以或者是对您有所启发、帮助,还希望得到您的鼓励支持,谢谢!
赞 赏 作 者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

▼ 点击成为社区注册会员 「在看」一下,一起PY

















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









