







目录
单变量图(chart for one variable)是指使用数据组的一个变量进行相应图的绘制。想要可
- 连续变量(continuous variable)
- 离散型变量(discrete variable)
基于连续变量绘制的单变量图包括
- 直方图(histogram plot)
- 密度图(density plot)
- Q-Q 图(Quantile Quantile plot,又称分位图)
- P-P 图(Probability-Probability plot)
- 经验分布函数图(Empirical Distribution Function,EDF)
基于连续变量绘制的单变量图的类型
-
直方图
-
密度图
密度图(又称为密度曲线图)作为直方图的一个变种类型,使用曲线(多数情况下为平滑样式,但也会因核函数的不同而出现直角样式)来体现数值水平,其主要功能是体现数据在连续时间段内的分布状况。和直方图相比,密度图不会因分组个数而导致数据显示不全,从而能够帮助用户有效判断数据的整体趋势。当然,选择不同的核函数,绘制的核密度估计图不尽相同。值得注意的是,在一些科研论文绘图过程中,密度图的纵轴可以是频数(count)或密度(density)。
-
Q-Q 图
Q-Q 图的本质是概率图,其作用是检验数据分布是否服从某一个分布。Q-Q 图检验数据分布的关键是通过绘制分位数来进行概率分布比较。首先选好区间长度,Q-Q 图上的点 (x,y) 对应第一个分布(X 轴)的分位数和第二个分布(Y 轴)相同的分位数。因此可以绘制一条以区间个数为参数的曲线。如果两个分布相似,则该 Q-Q 图趋近于落在 y = x 线上。如果两个分布线性相关,则点在 Q-Q 图上趋近于落在一条直线上。例如,对于正太分布的 Q-Q 图,就是以标准正太分布的分位数作为横坐标,样本数据值为纵坐标的散点图。而想要使用 Q-Q 图对某一样本数据进行正态分布的鉴别时,只需观察 Q-Q 图上的点是否近似在一点直线附近,且该条直线的斜率为标准差,截距为均值。
Q-Q 图不但可以检验样本数据是否符合某种数据分布,而且可以通过对数据分布形状的比较,来发现数据在位置、标度和偏度方面的属性。但需要注意的是,想要理解 Q-Q 图,读者需要具备一定的专业知识水平,因此,在一般的学术研究中,使用直方图或密度图观察数据分布的频次要远高于 Q-Q 图。
-
P-P 图
P-P 图是根据变量的累积概率与指定的理论分布累积概率的关系绘制的图形,用于直观地检验样本数据是否符合某一概率分布。当检验样本数据符合预期分布时,P-P 图中的各点将会呈现一条直线。P-P 图与 Q-Q 图都用来检验样本数据是否符合某种分布,只是检验方法不同而已。
-
经验分布函数图
单变量图形的绘制方法
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams["ytick.right"] = False
hist_data = pd.read_excel(r"/单变量图表绘制/柱形图绘制数.xlsx")
hist_x_data = hist_data["hist_data"].values
bins = np.arange(0.0,1.5,0.1)
fig,ax = plt.subplots(figsize = (4,3.5),dpi = 100)
hist = ax.hist(x = hist_x_data, bins = bins,
color = "#3F3F3F", edgecolor = 'black',
rwidth = 0.8)
ax.tick_params(axis = "x",which = "minor",top = False,
bottom = False)
ax.set_xticks(np.arange(0,1.4,0.1))
ax.set_yticks(np.arange(0.,2500,400))
ax.set_xlim(-.05,1.3)
ax.set_ylim(0.0,2500)
ax.set_xlabel('Values', )
ax.set_ylabel('Frequency')
plt.show()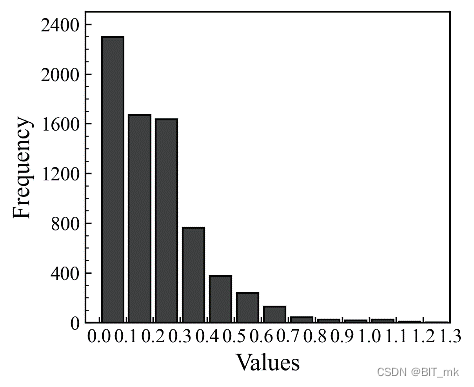
import proplot as pplt
from proplot import rc
rc["axes.labelsize"] = 15
rc['tick.labelsize'] = 12
rc["suptitle.size"] = 15
fig = pplt.figure(figsize=(3.5,3))
ax = fig.subplot()
ax.format(abc = 'a.', abcloc = 'ur', abcsize = 16,
xlabel = 'Values', ylabel = 'Frequency',
xlim = (-.05,1.3), ylim=(0,2500))
hist = ax.hist(x = hist_x_data, bins = bins,
color = "#3F3F3F",
edgecolor = 'black', rwidth = 0.8)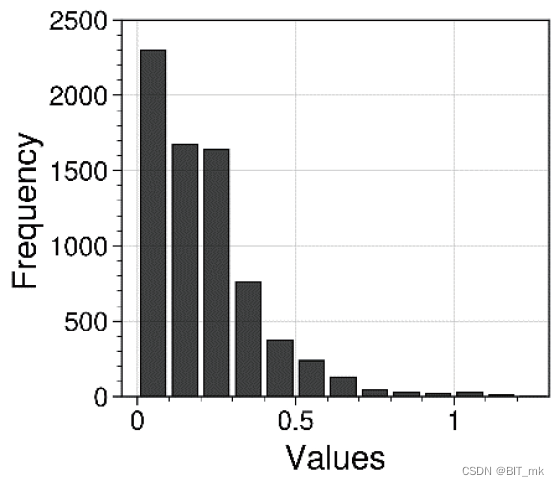
import numpy as np
import pandas as pd
from scipy.stats import norm
import matplotlib.pyplot as plt
hist_data02 = pd.read_csv(r"\单变量图表绘制\\直方图绘制02.csv")
bins=15
hist_x_data = hist_data02["hist_data"].values
Median = np.median(hist_x_data)
mu,std = norm.fit(hist_x_data)
fig,ax = plt.subplots(figsize=(5,3.5),dpi=100)
hist = ax.hist(x=hist_x_data, bins=bins,color="gray",
edgecolor ='black',lw=.5)
# 绘制正态分布曲线(Plot the PDF)
xmin, xmax = min(hist_x_data),max(hist_x_data)
x = np.linspace(xmin, xmax, 100) # 100为随机选择,值越大,绘制曲线越密集
p = norm.pdf(x, mu, std)
N = len(hist_x_data)
bin_width = (x.max() - x.min()) / bins
ax.plot(x, p*N*bin_width,linewidth=1,color="r",
label="Normal Distribution Curve")
# 添加均值线
ax.axvline(x=Median,ls="--",lw=1.2,color="b",
label="Median Line")
ax.set_xlabel('Values')
ax.set_ylabel('Count')
ax.legend(frameon=False)
plt.show()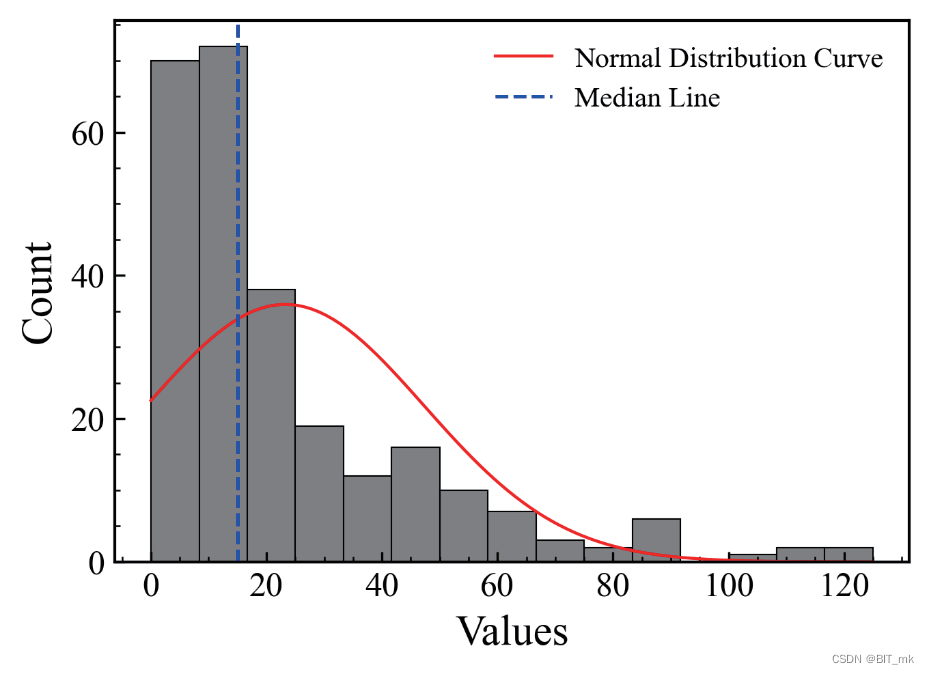
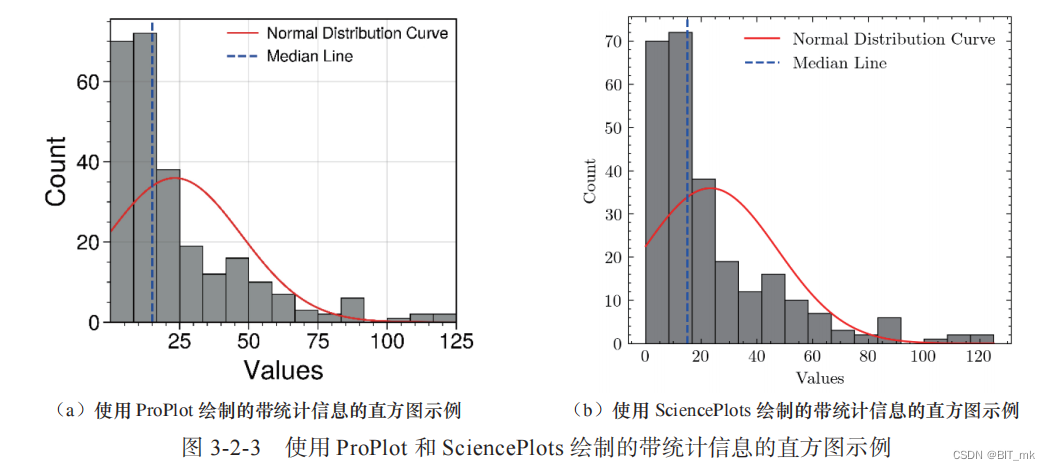















 2992
2992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









