







哈希
bzoj3098
bzoj3162
bzoj2085hash+快速幂
题意:
Tz养了一群仓鼠,他们都有英文小写的名字,现在Tz想用一个字母序列来表示他们的名字,只要他们的名字是字母序列中的一个子串就算,出现多次可以重复计算。现在Tz想好了要出现多少个名字,请你求出最短的字母序列的长度是多少。
分析:
设
dis[i][j]
为第i个字符串后接第j个字符串要加多少个字母。
用hash预处理
dis[][]
后就变成了:在这个有向图中走m-1步的最短路径。
由于每次每个节点的抉择都是一样的,相当于
len[][]∗dis[][]m−1
bzoj1125hash+线段树
题意:
给出n个字符串,长度均为len;
有m次操作,每次将两个字符交换;
求每个字符串在任何时点上,与相同的它最多的字符串个数;
n<=1000,len<=100,m<=100000;
分析:
首先我们可以快速维护每个串的哈希值。
每个串的哈希值只有在交换的时候才改变。
于是乎一共只有n+m*2个不同的哈希值。
每个串的哈希值会出现一段时间。
那么我们将所有的哈希值搞出来记录它的标号,开始位置和结束位置,是哪个字符串。
将哈希值从小到大排序,将哈希值相同的一起搞。那么问题转化为
线段树维护区间加和区间最大值。每次要清空线段树,打个clear[]标记就好了。
bzoj2803hash+推性质暴力
首先我们如果设原串为
s[1,n]
然后
fi
表示
s[i+1,n?i]
中最长的串长使得
s[i+1,i+fi]==s[n?i?fi+1,n?i]
这时存在一个性质
fi?1≤fi+2
然后就可以线性递推啦!就是暴力
bzoj1054bfs+hash判重
bzoj3207hash+3次二分
存储原字符串中所有长度为k的子串的hash值以及结束的位置。
按hash值排序。再将hash值相同的按结束位置排序。
询问时先二分一波hash值,判断是否存在。
询问为区间[l,r]则结束位一定在[l+k-1,r]中,在二分两波就好了。
bzoj3507hash+dp
n才100,所有我们对每个字符串分别搞
记f[i][j]为第i个通配符和第j位匹配是否行得通~
若pos[i]=’*’则f[i][j-1]可以转移到f[i][j]
然后从pos[i]转移到pos[i+1]
那么要用hash判断:
原串[j,j+pos[i+1]-pos[i]-1]==通配串[pos[i]+1,pos[i+1]-1]
若pos[i]=’*’
f[i+1][j+pos[i+1]-pos[i]]可以
若pos[i]=’?’
f[i+1][j+pos[i+1]-pos[i]-1]可以
bzoj4337hash判断同构树
只要使得hash值与树的编号无关而和结构有关就好了。
比如说深度、度数。接下来就是乱搞时间了。
具体是:对与一个深度确定两个随机数。
bzoj2124
bzoj1862&&1056
bzoj3067邻接表hash统计答案
bzoj3097
bzoj2258
bzoj3198
bzoj2795
bzoj1414
bzoj3574
字符串上
树上
KMP

xsy2178★★★★★
xsy2202
题意:给出s串和t串,求s串中有多少子串与t串同构
分析:
求的是同构,那么每一个位置到与它上一个相同字符的位置之间的距离一定相同。这样再在kmp上乱搞一下就可以了。
kmp判断一个位置上是否匹配时有两种情况:①距离一样②两个都是第一次出现。
//核心代码
fix=0;
for (int i=2;i<=m;i++){
while (fix && min(t[i],fix+1)!=t[fix+1]) fix=nxt[fix];
if (min(t[i],fix+1)==t[fix+1]) fix++;
nxt[i]=fix;
}
fix=0;
for (int i=1;i<=n;i++){
while (fix && min(s[i],fix+1)!=t[fix+1]) fix=nxt[fix];
if (min(s[i],fix+1)==t[fix+1]) fix++;
if (fix==m) q[++ans]=i;
}xsy1903
将相邻颜色相同的切开。对与每一子串,统计有哪些不合法哪些合法。统计所有子串的合法情况就好了。
bzoj1009
题意:
阿申准备报名参加GT考试,准考证号为N位数
X1X2....Xn(0≤Xi≤9)
,他不希望准考证号上出现不吉利的数字。 他的不吉利数学
A1A2...Am(0≤Ai≤9)
有M位,不出现是指X1X2…Xn中没有恰好一段等于
A1A2...Am
。
A1
和
X1
可以为0阿申想知道不出现不吉利数字的号码有多少种。
N≤109,M≤20
分析:
dp[i][j]表示考号弄到前i位时当前考号的后j位于不吉利考号的前j位相同。
dp[i+1][k]+=dp[i][j]∗num[j][k]
num[j][k]
表示 能匹配到第j位 加一位以后变成 能匹配到第k位 有多少个数符合。
题解1
题解2
bzoj3670
题中num[]就是next[]的定义,只是多加了前缀和后缀不能重叠罢了。
bzoj3942√
bzoj1355
利用next[]的定义那么
不整除的循环节就是len-next[len]
整除的循环节就判断一波好了
bzoj1461&&1729★
bzoj3620
嗯,
n2
可过~。直接枚举开头在用next[]搞一波就好了
bzoj3213 无题面
bzoj1511
读懂题意很重要
nxt[]相关乱搞
ps:画个图什么都懂了。
bzoj3899★★★★★
bzoj3796
后缀数组+二分+kmp
将
s1和s2
连接,中间用’a’-1断开。搞一波后缀数组。
预处理
s3
在
s1和s2
的什么地方出现。搞一波kmp
在每次出现的开头打一个标记,然后前缀和sum[]一下。
当要判断
[l...r]
区间中是否出现
s3
。就看
sum[l+(r−l+1)−s3len]−sum[l−1]
是否等于0(差分一下)
然后二分答案扫
h[]
判断一下好了。
//bzoj3942
有一个S串和一个T串,长度均小于1,000,000,
设当前串为U串,然后从前往后枚举S串一个字符一个字符往U串里添加,
若U串后缀为T,则去掉这个后缀继续流程。
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=1001000;
int nxt[N],stk[N],f[N];
int n,m,top,fix;
char s[N],t[N];
int main(){
scanf("%s",t+1);
scanf("%s",s+1);
int lens=strlen(s+1);
int lent=strlen(t+1);
for (int i=2;i<=lens;i++){
while (fix && s[fix+1]!=s[i])
fix=nxt[fix];
if (s[fix+1]==s[i]) fix++;
nxt[i]=fix;
}
for (int i=1;i<=lent;i++){
fix=f[stk[top]];
while (fix && s[fix+1]!=t[i])
fix=nxt[fix];
if (s[fix+1]==t[i]) fix++;
if (fix==lens)
top-=lens-1; else
stk[++top]=i,f[i]=fix;
}
for (int i=1;i<=top;i++)
printf("%c",t[stk[i]]);
printf("\n");
}
扩展KMP
//ex[i]表示s[1...ex[i]]=s[i...i+ex[i]-1]
ex[1]=len;mx=1;
for (int i=2;i<=len;i++){
if (i<=mx) ex[i]=min(mx-i+1,ex[i-id+1]);
while (s[i+ex[i]]==s[1+ex[i]]) ex[i]++;
if (mx<i+ex[i]-1) mx=i+ex[i]-1,id=i;
}xsy2346
题意:
给你一个字符串s,对于s的每一个前缀,如果它也是s的一个后缀,输出这个前缀在s中出现了多少次。
分析:
法一:kmp+dp
法二:exkmp(自己跟自己搞)
xsy2347√
xsy2348√
bzoj3796
poj3376
后缀数组
xsy2255二分+环形的区间覆盖问题
题意:
你有一个长度为 N 的环形字符串,它只包含 ′1′−′9′ 共9种字符。你想把它分成 K 个连续非空的字符串。每一个字符串都可以看成一个十进制整数。你的目标是找到一种分割方案,使得分割出的K个整数的最大值最小。
分析:
二分一下最大值开头的排名,然后枚举将环剖开的位置,共len个。
然后扫一遍分割,
O(nlen)
所以每次的判断是
O(n)
的
xsy2256
xsy1920二分+分组
将所有串接起来中间用不同的东东隔开,在最后在加入第一串。
二分答案的长度,按排名从大到小扫一遍,如果
h[]≥len
就分成一组,那么就分成了几段,判断存不存在一段使得里面有第1串的开头但没有其他串的开头。
bzoj3230
将原串反转,便将前缀转换为后缀。
也就是搞两波后缀数组。
利用height[]求出所有本质不同的子串,前缀和一下。
在用st表搞一下height[]用来求任意两串的最长公共前缀
每个询问在前缀和中二分,找到相应位置。
在st表上查询一下就好了。
bzoj3238
难点在于:求
∑1≤i<j≤nlcp(si,sj)
,(
si
表示字符串第i位的后缀)
单调栈乱搞好了。具体代码见应用④
bzoj2251
法一、trie。将所有后缀加入01trie,在结尾处打上标记,递归求一遍就好了。
法二、后缀数组,再扫height[]每次的长度必须大于前一个后缀的长度不然会重复。
bzoj1692
将原串和反转串相接,中间用奇怪字符隔开,跑一波后缀数组得到每个后缀的排名,再用两个指针从队尾和队头扫就好了(原串开头和反转串开头)
bzoj1717
二分答案,用height[]判断。
bzoj2119★★★

要求走势相同,差分后离散化。
然后就是求有多少子串样子是ABA
给定了B的长度。
枚举A的长度L,将数列每L分成一块。
记每块开头为关键点,为了防止重复,每个关键点所能向两边扩展的最多只有L。这样第一个A就最多只能覆盖一个关键点了。
枚举关键点i,第二个A的开头就是i+L+m。
设第一个A的开头和第二个A的开头能向左扩展到l,向右扩展到r
那么只要r-l+1>L就符合条件了。也就是说一次扩展后对答案的贡献是r-l+1-L个(扩展用st表乱搞)
bzoj1031
复制一下,跑一波后缀数组求出sa[]
直接扫sa[],判断sa[i]排名第i的后缀长度是否大于原串,输出就好了。
bzoj2946
法一、
将所有字符串接起来,跑一波后缀数组求出sa[]和height[]
二分答案后用height[]判断。
法二、
后缀自动机
bzoj4556★★★
后缀自动机:题解
后缀数组:题解
注意到要在一个区间
[s1,t1]
内找一个子串使得它与已知子串
[s2,t2]
最长公共前缀最长。
首先可以想到后缀数组中的height[]是可以快速知道两个后缀的最长公共前缀的。也就是说我们可以在
[s1,t1]
枚举开头然后与
[s2,t2]
匹配一下。时间复杂度显然爆炸。
二分一波答案,就可以固定开头在
[s1,t1−len+1]
内。
根据二分的答案将
s2
后缀的排名向左右两端扩展(利用height[])注意是排名扩展!
于是乎只要判断在
[s1,t1−len+1]
区间中是否有后缀排名是在
合法后缀排名中就好了。这可以用可持久化线段树搞一下,判断的时候差分。
bzoj4310
二分答案的排名,从后往前扫判断当前在栈中的串是否符合,若不符合就截掉,看最后截成多少段。
bzoj3172 st表+二分(裸题)
bzoj3277&&3473★★★
首先发现假如[l,r]是符合条件的。那么[l,r]的所有子串都是合法的。
枚举开头,二分一下长度,然后在 按排名为不同根 记录 字符串编号 的可持久化权值线段树 上差分一下,判断是否合法。
Ps:代码码得贼爽
bzoj2754
将所有串接在一起,然后表示只会暴力(还是挺快的,挺难卡的)
这题主要是练习如何将串接起来的
bzoj3796
后缀数组+二分+kmp
将
s1和s2
连接,中间用’a’-1断开。搞一波后缀数组。
预处理
s3
在
s1和s2
的什么地方出现。搞一波kmp
在每次出现的开头打一个标记,然后前缀和sum[]一下。
当要判断
[l...r]
区间中是否出现
s3
。就看
sum[l+(r−l+1)−s3len]−sum[l−1]
是否等于0(差分一下)
然后二分答案扫
h[]
判断一下好了。
bzoj4199
一个r相似也是0相似,1相似,…,r-1相似
这给人的感觉就是要将每一个相似分开搞,
但r相似又能贡献到r-1相似上。
显然,我们可以轻易知道相邻排名的后缀的最长公共前缀(h[])
那么考虑将已求的r相似与将要求的东东合并。嗯~用并查集
要记录的就是每一陀的最大值,最小值,个数。
两陀东东合并就判断一下对最大值有没有贡献,个数就直接相乘累加就好了。
bzoj3879
将每个后缀的起始位变为该后缀的排名a[i]=rk[a[i]]
排一波序再去重,求一下相邻两排名的最长公共前缀
就将问题转换为下面的应用④。用单调栈乱搞就好了。
bzoj2780
是bzoj2754进化版。不能暴力乱搞
二分一下往前、往后的排名能到哪(st表判断)
就将问题转化成了区间不同数了。
用可持久化线段树差分一下就好了
bzoj4698
将所有串接起来后二分答案,利用height数组判断
bzoj3676
题意:定义一个回文串的出现值为出现次数*长度,求最大出现值
只有使mx变大的回文串,才是与之前所有回文子串不同的新串,否则一定可以由之前的回文串关于id对称得到。
manacher弄出有哪些回文串是可能的,再用sa[]找到当前回文串有多少个相同(直接在st表上二分,找到最左端和最右端,其中的lcp()均大于当前的回文串长度)
uoj35模版√
zoj3661
字符串
#include<cstdio>
#include<cstring>
#include<cstdlib>
using namespace std;
const int M=100001;
int rk[M],trk[M],h[M],sa[M],tsa[M],sum[M];
char s[M];
int len,m;
/*rk[i] 后缀i的排名
trk[] 临时存储
sa[i] 排名i的是哪个后缀
tsa[i]第二关键字优先级为i的所对应的第一关键字
m 当前rk数组有多少种排名
h[i] 后缀i和i-1的最长公共前缀
*/
//★★注意★★ sum数组要开 M 位而不是255位 因为后面按rk[i]桶排 ★★注意★★
void double_2()
{
///////////★第一关键字★///////////
memset(sum,0,sizeof(sum));
for(int i=1;i<=len;i++)sum[s[i]]++;
for(int i=1;i<=255;i++)sum[i]+=sum[i-1];
for(int i=len;i;i--)sa[sum[s[i]]--]=i;
rk[sa[1]]=1;int p=1;
for(int i=2;i<=len;i++)
{
if(s[sa[i]]!=s[sa[i-1]]) p++;
rk[sa[i]]=p;
}
m=p;
/////////////★开始倍增★/////////////
for(int j=1; m<len ;j*=2)// j为倍增距离 ★★结束条件为 m = len
{
p=0;
memset(sum,0,sizeof(sum));
memmove(trk,rk,sizeof(rk));
//若传一个rk进去则为:
//memmove(trk+1,rk+1,sizeof(rk[1])*len);
for(int i=len-j+1;i<=len;i++)tsa[++p]=i;//没第二关键字的优先级最高
for(int i=1;i<=len;i++)if(sa[i]>j)tsa[++p]=sa[i]-j;//sa[i]>j 即 可以成为第二关键字的
for(int i=1;i<=len;i++)sum[ trk[tsa[i]] ]++;
for(int i=1;i<=m;i++)sum[i]+=sum[i-1];
for(int i=len;i;i--)sa[sum[ trk[tsa[i]] ]--]=tsa[i];
/* tsa中的数按第二关键字已排好
进sum桶时按第一关键字放
假设作为第一关键字的名次(即rk[tsa[i]])相同,
把tsa中的数从后往前出,即为完成了排序*/
p=1;
rk[sa[1]]=1;
for(int i=2;i<=len;i++)
{
if(trk[sa[i]]!=trk[sa[i-1]]/*/前j个*/||trk[sa[i]+j]!=trk[sa[i-1]+j]/*后j个*/) p++;
rk[sa[i]]=p;
}
m=p;
}
}
void get_h()
{
//性质 h[rk[i]]大于等于h[rk[i-1]] -1
int p=0;
h[1]=0;
for(int i=1;i<=len;i++)
{
if(rk[i]==1) continue;//没有前一位
int j=sa[rk[i]-1];
for(;s[i+p]==s[j+p];p++);
h[rk[i]]=p;
if(p)p--;
}
}
int main()
{
freopen("a.in","r",stdin);
scanf("%s",s+1);//从1开始存
len=strlen(s+1);
double_2();
get_h();
return 0;
}应用
①后缀数组当时是弄后缀的,但反转一下字符串就成前缀数组啦~
②任意两个后缀的最长公共前缀。
int rmq(int x,int y){
int k=lg[y-x+1];
return min(mn[x][k],mn[y-(1<<k)+1][k]);
}
int gaolcp(int x,int y){
if (x==y) return len-x;
x=rk[x],y=rk[y];
if (x>y) swap(x,y);
return rmq(x+1,y);
}
void gaost(){
for (int i=1;i<=len;i++)
mn[i][0]=h[i];
for (int j=1;j<=18;j++)
for (int i=len-(1<<j)+1;i>0;i--)
mn[i][j]=min(mn[i][j-1],mn[i+(1<<(j-1))][j-1]);
}
lcp=gaolcp(x,y);//[x...len]和[y...len]的最长公共前缀长度
③求本质不同的子串个数,就是所有后缀的所有前缀。
一个串中不同子串的总数=∑(len-height[i]-sa[i]+1)
支持:
求排名第k的子串的开头和结尾。
注意: cnt[i]=∑ij=1len−sa[j]−height[j]+1
void kth(int x){
int l=1,r=len;
int ans=len;
while (l<=r){
int mid=(l+r)>>1;
if (cnt[mid]>=x)
ans=mid,r=mid-1; else
l=mid+1;
}
int ll=x-cnt[ans-1];
ls=sa[ans];
rs=sa[ans]+h[ans]+ll-1;
//ls,rs为全局变量哦~
}④求 ∑1≤i<j≤nlcp(si,sj) ,( si 表示字符串第i位的后缀)
//单调栈bzoj3238
h[0]=-inf;
for(int i=1;i<=n;i++)
{
while(h[i]<=h[st[top]])top--;
if(st[top]==0)l[i]=1;
else l[i]=st[top]+1;
st[++top]=i;
}
h[n+1]=-inf;top=0;st[0]=n+1;
for(int i=n;i;i--)
{
while(h[i]<h[st[top]])top--;
if(st[top]==n+1)r[i]=n;
else r[i]=st[top]-1;
st[++top]=i;
}
for(int i=1;i<=n;i++)
ans+=(i-l[i]+1)*(r[i]-i+1)*h[i];
//l[i]表示h[i]>=h[l[i]]能延伸到的最左端
//r[i]表示h[i]>=h[r[i]]能延伸到的最右端
//排名为l[i]~r[i]的两两匹配的贡献值
//因为它们的贡献均为l[i]~r[i]中h[]值最小的即h[i]⑤求所有出现次数大于1的子串,按子串字典序输出每个子串的出现次数。
//暴力扫bzoj2251
for (int i=1;i<=n-1;i++)
for (int hh=h[i-1]+1;hh<=h[i];hh++)
for(int j=i+1;h[j]>=hh;j++);
printf("%d\n",j-i+1);⑥子串s[a..b]的所有子串和s[c..d]的最长公共前缀的长度的最大值
//bzoj4556
//二分+可持久化线段树+st
int check(int x){
int l=rk[s2],r=rk[s2];
for (int i=18;i>=0;i--){
if (l-(1<<i)>=0 && mn[l-(1<<i)+1][i]>=x) l-=(1<<i); //排名往前扩展
if (r+(1<<i)<=n && mn[r+1][i]>=x) r+=(1<<i); //排名往后扩展
}
return query(rt[l-1],rt[r],1,n,s1,t1-x+1)>0;//差分判断
}
int main(){
.....
for (int i=1;i<=n;i++)
ins(rt[i],rt[i-1],1,n,sa[i]);
while (m--){
scanf("%d%d%d%d",&s1,&t1,&s2,&t2);
int l=0,r=min(t2-s2+1,t1-s1+1);ans=0;
while (l<=r){
int mid=(l+r)>>1;
if (check(mid))
ans=mid,l=mid+1; else
r=mid-1;
}
printf("%d\n",ans);
}
}树上
xsy2132
xsy2142
xsy2247
题意:求以1为根的树上所有点对d(x,y)=lcs(s[1~x],s[1~y])+lcp(s[1~x],s[1~y])的最大值(保证树中每个点的出边 边权值都不相同,y为x子树中的点)
分析:
树上后缀数组搞出h[],sa[]。对于树上的其中一个点x,另一个点y在子树中那么它们的lcs就是dep[x],lcp可以用st[][]乱搞一下。
但我们不能直接枚举所以点对……
用set启发式合并就好啦。(从叶子节点往上合并)
xsy2132
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<string>
using namespace std;
typedef unsigned long long ull;
const int N=500100;
const int M=20;
int sa[N],rk[N],sum[N],tsa[N];
ull hsh[N][M],fa[N][M],pw[N];
int t[N][M],v[N],hh[N],lg[N];
int h[N],dep[N];
int n,m,tot,x,y;
struct edge{int y,next;}g[N*2];
long long ans;char s[10];
void adp(int x,int y){
g[++tot].y=y;
g[tot].next=h[x];
h[x]=tot;
}
void ads(int x,int y){
g[++tot].y=y;
g[tot].next=h[x];
h[x]=tot;
}
void dfs(int x){
for (int i=h[x];i;i=g[i].next)
if (g[i].y!=fa[x][0]){
dep[g[i].y]=dep[x]+1;
fa[g[i].y][0]=x;
dfs(g[i].y);
}
}
int check(int x,int y,int j){
return hsh[x][j]==hsh[y][j] && hsh[fa[x][j]][j]==hsh[fa[y][j]][j];
}
void gaosa(){
for (int i=1;i<n;i++) sum[i]=0;
for (int i=1;i<=n;i++) sum[t[i][0]]++;
for (int i=1;i<n;i++) sum[i]+=sum[i-1];
for (int i=n;i;i--) sa[sum[t[i][0]]--]=i;
int m=N-1;
for (int j=1;(1<<j)<=n;j++){
int p=0;tot=0;
memset(sum,0,sizeof(sum));
memset(h,0,sizeof(h));
for (int i=1;i<=n;i++)
if (dep[i]<=(1<<(j-1)))
tsa[++p]=i; else
ads(fa[i][j-1],i);
for (int i=1;i<=n;i++)
for (int t=h[sa[i]];t;t=g[t].next)
tsa[++p]=g[t].y;
for (int i=1;i<=n;i++) sum[t[tsa[i]][j-1]]++;
for (int i=1;i<=m;i++) sum[i]+=sum[i-1];
for (int i=n;i;i--) sa[sum[t[tsa[i]][j-1]]--]=tsa[i];
m=1;t[sa[1]][j]=1;
for (int i=2;i<=n;i++)
t[sa[i]][j]=m=m+!check(sa[i-1],sa[i],j-1);
}
for (int i=1;i<=n;i++)
rk[sa[i]]=i;
}
int calc(int x,int y){
int res=0;
for (int i=19;i>=0;i--)
if (hsh[x][i]==hsh[y][i] && fa[x][i] && fa[y][i]){
x=fa[x][i];y=fa[y][i];
res+=(1<<i);
}
return res;
}
void gaoh(){
for (int i=2;i<=n;i++)
hh[i]=calc(sa[i-1],sa[i]);
}
int main(){
scanf("%d",&n);
for (int i=1;i<n;i++){
x=read();y=read();
adp(x,y);adp(y,x);
v[x]++;v[y]++;
}
for (int i=1;i<=n;i++){
hsh[i][0]=v[i];
t[i][0]=v[i];
}
dep[1]=1;dfs(1);pw[0]=1;
for (int i=1;i<n;i++) pw[i]=pw[i-1]*1313;
for (int i=2;i<n;i++) lg[i]=lg[i/2]+1;
for (int j=1;j<=19;j++)
for (int i=1;i<=n;i++){
fa[i][j]=fa[fa[i][j-1]][j-1];
hsh[i][j]=hsh[i][j-1]+hsh[fa[i][j-1]][j-1]*pw[1<<(j-1)];
}
gaosa();
gaoh();
for (int i=1;i<=n;i++)
ans+=dep[sa[i]]-hh[i];
//求从编号1~n的点到根节点1的所有不同子串个数
printf("%lld\n",ans);
return 0;
}AC自动机
//trie图
int l=0,r=0;
for (int i=0;i<26;i++)
if (ch[0][i])
q[++r]=ch[0][i];
while (l<r)
{
int x=q[++l];
for (int i=0;i<26;i++)
if (ch[x][i])
{
q[++r]=ch[x][i];
fail[ch[x][i]]=ch[fail[x]][i];
} else ch[x][i]=ch[fail[x]][i];
} //AC自动机
int h=0,t=0,p;
for(int i=0;i<26;i++)
if(son[0][i]) l[++t]=son[0][i]; //先将跟节点的儿子入队
while(h!=t)
{
int k=l[++h];
for(int i=0;i<26;i++)if(son[k][i])
{
l[++t]=son[k][i]; //入队
for(p=pre[k];p && !son[p][i];p=pre[p]); //通过fail指针往上跳直到找到son[i]!=0;
if(son[p][i]) pre[son[k][i]]=son[p][i]; //连接儿子的fail
}
}两者对比:trie图比AC自动机多连了一些儿子边,这样trie图就不用跳fail指针了。但两者的 fail[] 都是一样。
神犇
bzoj2434 阿狸的打字机
题意:初始字串为空,首先给定一系列操作序列,有三种操作:
1.在结尾加一个字符
2.在结尾删除一个字符
3.打印当前字串
分析:
建AC自动机,弄出fail树。查询x串在y串中出现过多少次,其实就是询问根到y串结尾节点的路径上有多少个点能通过跳fail指针到x串的节点位置。离线后用树状数组查询子树(dfs序)内标记点数即可。
bzoj2938 病毒
题意:
给出n个病毒代码,判断是否有无限长度的代码满足:不包含任何病毒代码。
分析:
首先我们把所有串建一个AC自动机
方便起见我们直接把fail指针合并到子结点
如果一个串能无限长,也就是说它可以在AC自动机上一直进行匹配但就是匹配不上
也就是说匹配指针不能走到danger为1的结点,设这个点为x
即root..x是一个病毒串
那么fail指针指向x的y也不能走
因为root..x是root..y的一个后缀
处理出来判断有向图是否有环
dfs即可
bzoj4327
题意:求n个字符串,每个字符串与主串的最长公共子串。
分析:
对n个字符串建trie图记录每个字符串的结束位置,将主串扔到trie图上匹配打标记。最再从每个字符串的结束位置向上跑,直到遇到打了标记的点
就停止。
bzoj1030
bzoj2553
bzoj3881
bzoj3940
bzoj4179
bzoj3172
bzoj1195
bzoj1009
bzoj1444
bzoj1212
bzoj3028
后缀自动机
//★★注意★★ 空间要开2倍 ★★注意★★
//cnt、last初始值为1
void ins(int c)
{
int p,np,now,tnow;
p=last;last=np=++cnt;
len[np]=len[p]+1;
//在主链上加
while (!go[p][c] && p)
go[p][c]=np,p=fa[p];//往上跳到第一个没有c字符儿子的点
if (!p) fa[np]=1;//跳到空点
else
{
now=go[p][c];
if (len[p]+1==len[now])//
fa[np]=now;else
{//就像len[p]+1==len[now]一样新建一个点
tnow=++cnt;//新建一个点
len[tnow]=len[p]+1;//将其强行符合 len[p]+1==len[now]
memcpy(go[tnow],go[now],sizeof(go[now]));
fa[tnow]=fa[now];
/*
可以理解为now往parent树上提(在树边中)
那么新建的tnow要有now的相关性质
*/
fa[now]=fa[np]=tnow;//将新插入的点和now点指向新建的点
while (go[p][c]==now)
go[p][c]=tnow,p=fa[p];//将指向now的变成指向tnow
}
}
}

//广义后缀自动机bzoj2780
struct SAM{
int len[N],fa[N];
int last,tot,root;
map<char,int>son[N];
void init(){last=tot=root=1;}
void ins(char c,int id){
if (son[last][c]){//特判已有某个节点
int now=son[last][c],p=last;
if (len[now]==len[p]+1)
last=son[p][c]; else
{
int tnow=++tot;
len[tnow]=len[p]+1;
fa[tnow]=fa[now];
fa[now]=tnow;
son[tnow]=son[now];
while (son[p][c]==now && p)
son[p][c]=tnow,p=fa[p];
last=tnow;
}
return;
}
int p,np,now,tnow;
p=last;np=last=++tot;
len[np]=len[p]+1;
while (!son[p][c] && p)
son[p][c]=np,p=fa[p];
if (!p) fa[np]=1; else
{
now=son[p][c];
if (len[now]==len[p]+1)
fa[np]=now; else
{
tnow=++tot;
len[tnow]=len[p]+1;
son[tnow]=son[now];
fa[tnow]=fa[now];
fa[now]=fa[np]=tnow;
while (son[p][c]==now && p)
son[p][c]=tnow,p=fa[p];
}
}
}
}sam;xsy2013
xsy2318 循环位移 ☆☆☆
题意:
给定一个字符串 s 。现在问你有多少个本质不同的 s 的子串
t=t1,t2⋯tm(m>0)
使得将 t 循环左移一位后变成的
t'=t2⋯tm,t1
也是 s 的一个子串。
bzoj3998
题意:子串第k小可重复和不可重复
分析:
T=0(不可重复) 除了根以外的状态都代表1个串
T=1(可重复) 每个状态fail子树结束结点个数即为串的个数
bzoj3473
题意:
给定n个字符串,询问每个字符串有多少子串(不包括空串)是所有n个字符串中至少k个字符串的子串?
分析:建出广义后缀自动机,再建出后缀树,在后缀树中每个节点开一个set,从叶子节点往根启发式合并set。再将每个字符串扔进自动机中统计答案。
先建立一个广义后缀自动机,什么是广义后缀自动机?就是所有主串一起建立的一个后缀自动机。
广义后缀自动机的建立很简单,对于每个串,该怎么增量建立自动机就怎么建立,只不过为每个节点维护一个set保存这个节点的状态在那些字符串中出现过。当一个串增量构建完毕后,将后缀自动机的last指针指向后缀自动机的根即可进行下一发字符串的增量构建,这样就建出来了一发广义后缀自动机。
当然也可以把所有字符串连起来,中间插入一个在所有字符串中没有出现过的字符,然后一口气建完也可以,但是这两种建法在统计答案上有所不同,这里我用第一种方法(第二种你也不会啊喂!)
考虑一个节点,如果他在x个字符串中出现过,那么他的fa指针所指向的节点所代表的状态出现过的次数一定不小于他
并且我们已经为每个节点维护了一个set来记录在那些字符串中出现过,那么我们只需要自下向上合并set集合即可,在这之前需要整理出parent树的具体形态,然后一遍dfs,逆序处理set的启发式合并即可
统计答案只需把每个字符串在自动机上跑,跑到一个节点发现出现次数小于K就往fa指针那里跳,知道符合条件,这时候贡献的答案就是当前节点的l[]属性的值了
bzoj2806
题意:
给定一个由M个01串组成的字典。依据这个字典和一个阀值L,可以断言一个01串是否”熟悉”,其定义是:
把一个串划分成若干段,如果某个段的长度不小于L,且是字典中的某个串的连续子串,则这个段可识别;如果对于给出的串,
存在一个划分,使得可识别的长度不小于总长度的90%,则这串是”熟悉”的。先后给出N个01串。对于每个给出的串,求使得该
串”熟悉”的最大的L值。如果这样的L值不存在,输出0。 输入数据总长<=1100000。
分析:dp时用广义后缀自动机快速求出某个位置往前能匹配多少位(用优先队列优化dp)
做个广义后缀自动机,这样可以在每个位置找到他往前最多能匹配多长设为len。二分L,考虑判定L可不可行dp,f[i]表示到第i个位置最多能匹配上多少个字符,则

j在
[i−len,i−L]
中,
i−L
单调递增,那么每一次只需要往队列里添加
i−L
这个点从队尾去掉没有这个点优的点(当前点比队尾点匹配得要后而且中间没有匹配的位置少),然后判断队首是否在决策区间里。最后判断f[n]是否大于0.9*n。
良心题解1
良心题解2
bzoj3238
题意:

分析:建后缀自动机再建后缀树然后在后缀树上dp。

bzoj2946
题意:
给出
n≤5
个由小写字母构成的单词
len≤2000
,求它们最长的公共子串的长度。
分析:对第一个字符串建后缀自动机,接着将每个字符扔进自动机中按拓扑序dp。更新自动机上每个状态最多能匹配的长度(取所以的最小值,因为要满足所有字符串都能匹配),再在所有状态能匹配的长度中取最大值。
bzoj4516
题意:
一个串,每次从后面插入一个字符,求每次插入以后有多少个不同的子串。
分析:每个节点对应若干个子串,所有节点代表的所有子串本质不同,节点i代表的子串个数为mx[i]-mx[fa[i]]
bzoj2780
题意:
给n个串,再给m个询问,每个询问一个字符串在多少个母串中出现。
分析:
①对n个串建出广义后缀自动机,标记每个串的结束位置,建出后缀树。
将每个询问字符串扔进自动机里匹配,问题就变成了最后字符串匹配到的位置在后缀树中的子树有多少个字符串结束的位置。用dfs序将树变成序列,就是傻逼的区间不同数问题了,用树状数组乱搞即可。
②假如不用dfs序的话,就用set从底到根启发式合并结束点集合,匹配后就可以直接得到答案了。
bzoj4199/uoj 131
题意:
两个长度为r的子串相同称为r相似。两个r相似的子串的价值是两个子串开头位置的价值乘积。 求r相似的子串数量和最大的代价(r=0…n-1)
分析:
我们先构造出后缀自动机,然后转成后缀树,在后缀树上跑dp,只用维护一个最大最小,和size就好了。方案数求法与bzoj3238类似,都是空点size为0,实点(字符串某一位)size为1。
详细题解
bzoj4310
题意:
将一个字符串分成不超过K段,使得这K段中,所有子串中字典序最大的最小。即每一段当中取一个最大的子串,再在所有段的最大子串再取一个最大值,让这个最大值最小。长度10W。
分析:
建后缀自动机,然后二分答案,在后缀自动机中跑出对应的字符串。再回到原字符串中贪心切割,求lcp时在后缀自动机中找lca。
bzoj4566
题意:
给定两个字符串,求出在两个字符串中各取出一个子串使得这两个子串相同的方案数。两个方案不同当且仅当这两个子串中有一个位置不同。
分析:
造一个广义后缀自动机,sz开成二维把两个串的sz分开来算,每个节点对答案的贡献为
(len[x]−len[fa[x]])∗sz[0][x]∗sz[1][x]
bzoj3926 诸神眷顾的幻想乡 trie建广义后缀自动机
题意:
求一棵树上本质不同的子串的数量 每个点出度<=20 叶子节点<=20。
分析:
后缀自动机上可以识别全部的后缀,也就是说按照从叶子节点到根的顺序插进去就相当于统计了所有的前缀,于是就想到了后缀自动机~
后缀自动机不同的状态一定对应不同的子串并且整个自动机对应的一定是全部的子串 所以ans+=len[i]-len[fa[i]]就是答案.
bzoj1396 识别子串
题意:
给一个长度为n的字符串定义一个位置i的识别子串为包含这个位置且在原串中只出现过一次的字符串。求每个位置的最短识别子串的长度。
1≤n≤105
分析:
建后缀自动机,
|Right|=1
的可以作为识别子串。
|Right(s)|=1
出现位置就是
Max(s)
考虑它可以作为哪些位置的识别子串
令
l=Max(s)−Max(fa),r=Max(s)
[1,l−1]
可以,贡献为
r−i+1
[l,r]
可以,贡献为
r−l+1
用两颗线段树就行了
bzoj3145 str ☆☆☆
题意:
给定两个长度分别为n,m的字符串。定义两个字符串匹配为它们至多有一位不同。求这两个字符串的最长公共子串。
bzoj4180 字符串计数
题意:
一个字符串T中有且仅有4种字符 ‘A’, ‘B’, ‘C’, ‘D’。构造一个新的字符串S,构造的方法是:进行多次操作,每一次操作选择T的一个子串,将其加入S的末尾。
给定的正整数N和字符串T,他所能构造出的所有长度为N的字符串S中,构造所需的操作次数最大的字符串的操作次数。
分析:
N≤1018
可以想到是矩阵快速幂。矩阵大小又不能太大,所以只能由字符种数构建了。
构建矩阵
b[i][j]
表示已i开头的子串可以接j开头的子串的最短长度。这个矩阵在构造的时候,可以对模式串建立后缀自动机,然后按照拓扑倒序,从后往前更新答案。
a[i][j]
表示后缀自动机中的结点i向后选择一个最短长度使其可以接j开头的子串。
a[i][j]=min(a[i][j],a[son[i][k]][j]+1)
(就j,k为枚举的字符,i为当前状态)
b[i][j]=a[son[1][i]][j]
1号结点的i儿子能到达的所有串都是以i开头的子串。
然后二分答案再判断其中最小值是否大于N即可。
bzoj2555 SubString ☆☆☆
题意:
支持两个操作
(1):在当前字符串的后面插入一个字符串
(2):询问字符串s在当前字符串中出现了几次?(作为连续子串)
你必须在线支持这些操作。
数据字符串最终长度 <= 600000,询问次数<= 10000,询问总长度<= 3000000
bzoj4032 最短不公共子串 ☆☆☆
题意:
给两个小写字母串A,B,请你计算:
(1) A的一个最短的子串,它不是B的子串
(2) A的一个最短的子串,它不是B的子序列
(3) A的一个最短的子序列,它不是B的子串
(4) A的一个最短的子序列,它不是B的子序列
分析:
(1)枚举A子串的开头,在B的后缀自动机上匹配。
O(n2)
(2)枚举A子串的开头,在B的序列自动机上匹配。
O(n2)
(3)在B的后缀自动机上dp。
f[son[now][a[i]−′a′]]=min(f[son[now][a[i]−′a′]],f[now]+1)
O(n2)
(4)在B的序列自动机上dp。
f[son[now][a[i]−′a′]]=min(f[son[now][a[i]−′a′]],f[now]+1)
O(n2)
poj1743
题意:给出一串字符,求不重合的最长重复子串,并且长度大于要求的k值。
分析:
如果我们得出每个结点的right集合
就能得到这些串的出现位置
right集合就是在fail树中子树内结束结点的并集
可以dp出right集合中的最大值/最小值,差值和max取较小值就是到该结点串符合题意的最长长度
CF235C
题意:
给出一个字符串s,n次询问某个字符串T的循环同构串在s中出现多少次。
|s|,∑|xi|<=106,n<=105
;
分析:
将T倍长后在S建出来后缀自动机上跑,当匹配长度超过
len(T)
时就贡献答案并减去子串开头的字符(now跳到fa[now]),再继续往下匹配。
相关问题
★★注意:
对于沿着
go[][]
建出来的是DAG,然后用拓扑序搞才有时间复杂度的保证。
在后缀自动机上匹配
问题:求出每个位置往前最多能在后缀自动机上匹配多少
分析:从左往右扫,记录一个now表示当前跳到哪。对于当前位置假如
go[now][c]
为空就跳
fa[]
不然就是那个节点了。长度就是对应的
now=go[now][c];len[now]
存在性查询
问题.给定文本T,询问格式如下:给定字符串P,问P是否是T的子串。
复杂度要求.预处理O(length(T)),每次询问O(P)。
分析:直接沿着
go[][]
对应着跳
不同的子串个数
问题.给定字符串S,问它有多少不同的子串。
复杂度要求.O(length(S))。
分析:后缀自动机能弄出所有子串(一个条路径对应一个)
沿着
go[][]
从开始点dfs,求路径条数就好了(拓扑)
不同子串的总长
问题.给定字符串S,求其所有不同子串的总长度。
复杂度要求.O(length(S)).
分析:后缀自动机能弄出所有子串(一个条路径对应一个)
沿着
go[][]
从开始点dfs,求出sz[]往上贡献就好了(拓扑)
字典序第k小子串
问题.给定字符串S,一系列询问——给出整数
Ki
,计算S的所有子串排序后的第
Ki
个。
复杂度要求.单次询问O(length(ans)*Alphabet),其中ans是该询问的答案,Alphabet是字母表大小。
分析:后缀自动机能弄出所有子串(一个条路径对应一个)
dfs预处理出每个点往后能有多少子串。(拓扑)
在dfs按
′a′ ′z′
的顺序,将每个
ki
减一减,不够减就跳进去好了。
//T=1时相同算多个
//T=0时相同算1个
void dfs(int x){
if (val[x]>=k)
return;
k-=val[x];
for (int i=0;i<26;i++)
if (go[x][i]){
if (k<=sum[go[x][i]]){
printf("%c",'a'+i);
dfs(go[x][i]);
return;
} else k-=sum[go[x][i]];
}
}
for (int i=1;i<=size;i++)t[len[i]]++;
for (int i=1;i<=n;i++) t[i]+=t[i-1];
for (int i=size;i;i--) s[t[len[i]]--]=i;
for (int i=size;i;i--)
if (T==1)
val[fa[s[i]]]+=val[s[i]];
//每一个点子树中实点的个数代表这个点往上的贡献数
else
val[s[i]]=1;
//每一个点都是一条路径,代表一个不同的子串
val[1]=0;
for (int i=size;i;i--){
sum[s[i]]=val[s[i]];
for (int j=0;j<26;j++)
sum[s[i]]+=sum[go[s[i]][j]];
}
if (k>sum[1])
printf("-1"); else
dfs(1);最小循环移位
问题.给定字符串S,找到和它循环同构的字典序最小字符串。
复杂度要求.O(length(S)).
分析:
将原串倍长,建后缀自动机,贪心地跑
go[][]
就好了。
区间子串个数
问题:给定一个字符串,然后再给定Q个询问,每个询问是一个区间[l,r],问在这个字符串区间中有多少个不同的子串。
Q≤100000
复杂度要求.
O(length(S)2)
分析:枚举开头,不断向后插入。就是建n次后缀自动机。
Trie
bzoj3689
题意:
给定n个非负整数A[1], A[2], ……, A[n]。求这些数两两异或起来以后(不包含A[i]^A[i])前k小的数。
分析:trie+堆(维护(id,k,x))表示a[id]与其他数匹配的第k大的数是x。
bzoj1954路径异或就是两个点到根节点的异或和 异或起来
bzoj4260√
bzoj4567
题意:
n个字符串,从上往下填。
1.如果存在一个单词是它的后缀,且当前没被填入,代价为n*n;
2.如果不存在一个单词是它的后缀,代价为x;
3.如果存在一个单词是它的后缀,且已填入的是它后缀的单词中序号最大的为y,代价为x-y。
分析:
第一个条件是没用的,因为如果触发这个条件一定不是最优的。
然后我们把串反着建一颗trie,把除了根以外不是作为串的结尾的没用的点去掉,这样就变成了一颗树。问题转化为给树上每个点标号,每个点的标号大于其父亲的编号,每个点代价为他的标号减去其父亲标号,最小化代价贪心,dfs并先走sz小的儿子进行标号即可。
bzoj3439trie+可持久化线段树
bzoj3166 可持久化trie
题意:给定一个数列,求一个区间[l,r],区间次大值与区间其他任意数的异或值最大,输出这个最大值。
分析:建可持久化trie,预处理每一位往前往后能到什么位置,再在可持久化trie上搞最大值。
bzoj1819 trie+暴力
bzoj2741 分块+可持久化线段树
题意:给定一个序列,多次询问[l,r]中最大子序异或和 强制在线。
分析:
f[i][j]
表示第
i
块的开头到第
在可持久化线段树上查询query(左端点,右端点,已选的一个值)
f[i][j]=max(f[i][j−1],query( (i−1)∗kuai+1 , j , a[j]) )
对于每一个询问将左边多出来的数暴力一遍再与
f[pos[l]+1][r]
取较大值。
bzoj4212 trie+可持久化trie ☆☆☆☆
题意:
给出n个字符串(总长<2000000),给出m个询问,每个询问两个字符串
s1和s2
,求那n个字符串中有多少个字符串的 前缀与
s1
相同,后缀与
s2
相同。
分析:
将n个字符串排序,使得前缀相同的字符串相邻。然后建trie,在trie上的每个节点记录那个区间的字符串能匹配到这个点。这个对于每个询问就可以根据
s1
确定合法字符串的编号区间。再对n个字符串反着建可持久化trie,记录每个节点对应有多少个字符串
sum[]
,对于每个询问将
s2
在可持久化trie上跑一遍,就知道匹配到可持久化trie上的哪个节点,再根据
sum[]
输出即可。
bzoj4523
Manacher
bzoj3160
题意:在一个仅仅含有a,b的字符串里选取一个子序列,使得:
1.位置和字符都关于某条对称轴对称;
2.不能是连续的一段。
分析:
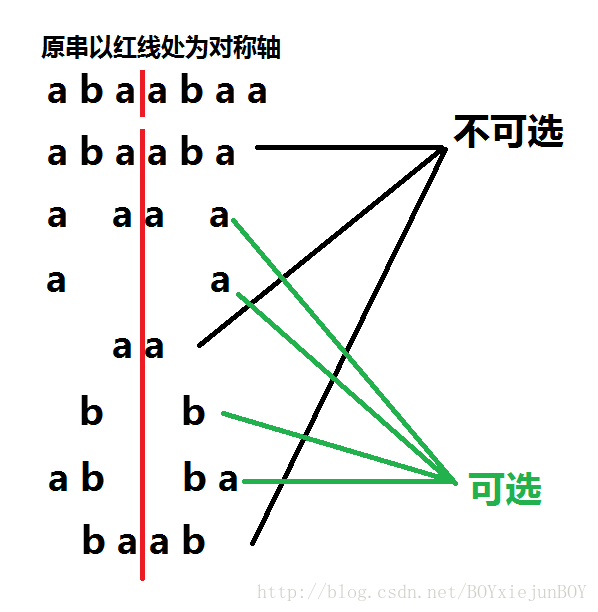
对于每一条对称轴只要求在对称轴两边的对应位置上有相同字符的位置有多少个。
答案就是
2len−1−len
(减去空串和连续的串)
但这东东它可以是不连续的…..
我们可以将
a b a a b a
1 0 1 1 0 1
发现:多项式
1 0 1 1 0 1
*1 0 1 1 0 1
假如答案某一位上是1,则
xk
前的系数恰好为以第k个位置(包括间隙,从0开始)为对称轴而对称的a的个数。
fft搞两波问题就解决啦~
bzoj3676
题意:定义一个回文串的出现值为出现次数*长度,求最大出现值
只有使mx变大的回文串,才是与之前所有回文子串不同的新串,否则一定可以由之前的回文串关于id对称得到。
manacher弄出有哪些回文串是可能的,再用sa[]找到当前回文串有多少个相同(直接在st表上二分,找到最左端和最右端,其中的lcp()均大于当前的回文串长度)
bzoj3790
题意:给定一个串,问这个串最少可以由回文串拼接多少次而成(拼接可以重叠)
分析:
首先用manacher求出回文子串长度,之后问题就转化为已知一堆线段,要用最少的线段,覆盖整个区间。然后用树状数组乱搞就好了。
bzoj2342
题意:定义 双倍回文 为 一个回文串套一个回文串, 问一个串中的最长双倍回文串。
分析:manacher+并查集
zoj3661
\\最长回文串长度
scanf("%s",s+1);
t[0]='<';t[1]='#';
int len=strlen(s+1);
for (int i=1;i<=len;i++){
t[2*i]=s[i];
t[2*i+1]='#';
}len=len*2+1;
t[++len]='>';
for (int i=1;i<len;i++){
if (mx>i)
p[i]=min(p[2*pos-i],mx-i); else
p[i]=1;
while (t[p[i]+i]==t[i-p[i]]) p[i]++;
if (mx<p[i]+i) mx=p[i]+i,pos=i;
ans=max(ans,p[i]);
}
printf("%d\n",ans-1);回文自动机
bzoj3676
题意:
考虑一个只包含小写字母的字符串s。我们定义s的一个子串t的“出现值”为t在s中的出现次数乘以t的长度。请你求出s的所有回文子串中的最大出现值。
分析:
建回文自动机弄出回文树,用一个size[]记录每个点的子树中有多少节点。一个点x的贡献就是len[x]*size[x],取所有点的贡献的最大值即可。
bzoj4044
bzoj2565
bzoj2160















 7712
7712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









