







一直以来数据降维是非常重要的预处理步骤,通过数据降维,我们可以实现数据可视化、数据降噪、数据压缩等目标。那么如何定义降维呢?我们定义一个映射矩阵W,z=w*x,则表示原数据通过矩阵W变成Z。
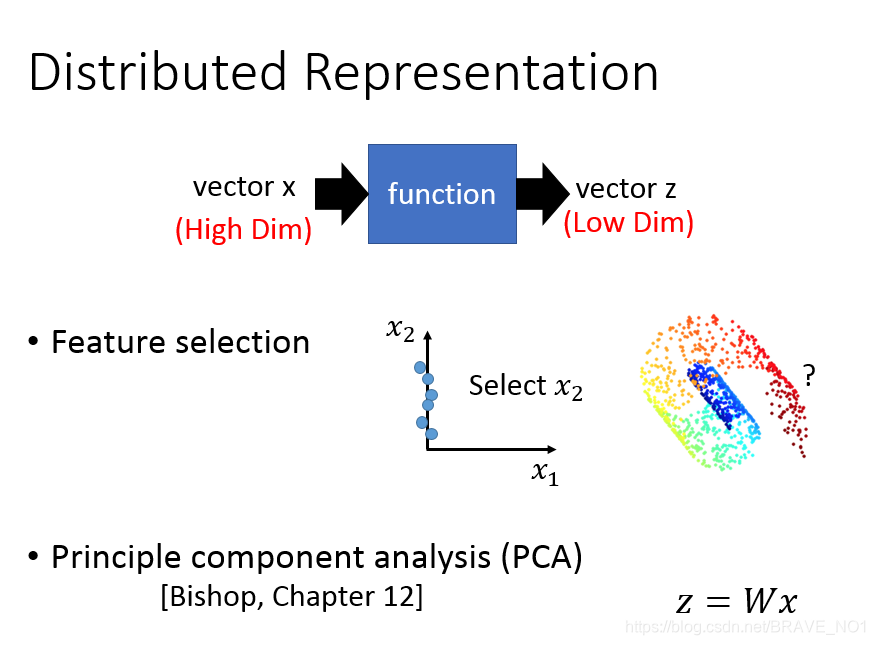
PCA(principle component analysis主成分分析)
主成分分析总体来说是为了在降维的过程中尽可能的保存信息。那么如何衡量信息呢,我们考虑到了熵: − ∫ p l n p -\int p lnp −∫plnp。熵中用到了概率分布,那么如何求解pdf(概率密度函数),我们考虑到了高斯。那么如何度量保存了信息的大小呢,我们考虑到了方差。如果原数据X与降维后的数据Z之间的方差接近,那么我们认为保存了足够的信息。但是var(Z)与var(X)是不同维度的数据,无法比较,所以我们可以换个角度进行思考。因为X是已知的,则var(X)也就是已知的。而var(Z)越大也就是离var(X)越近,最大也不会超过var(X)。这样一来,我们的目标就变成了使得Var(Z)最大化。
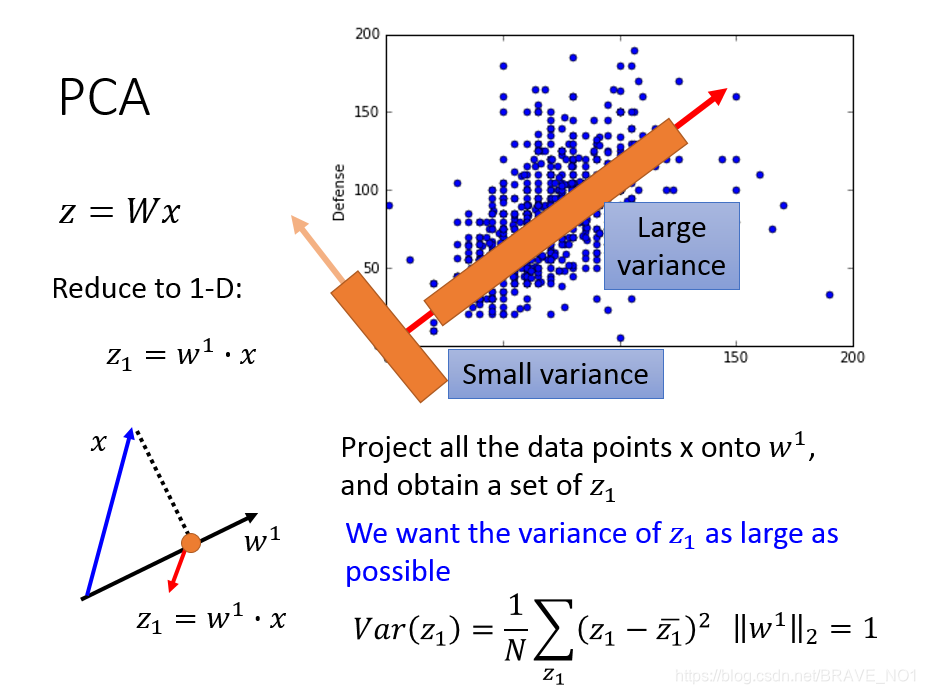
在图中,当投影在方差大的方向时,保存得信息最多。

那我们就开始计算:从第一个主成分开始: z 1 = w 1 x z_1=w^1x z1=w1x:

根据前面对W的声明,它是一个正交矩阵,那么我们在这里可以添加约束认为是标准正交矩阵。那么可以添加约束
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









