









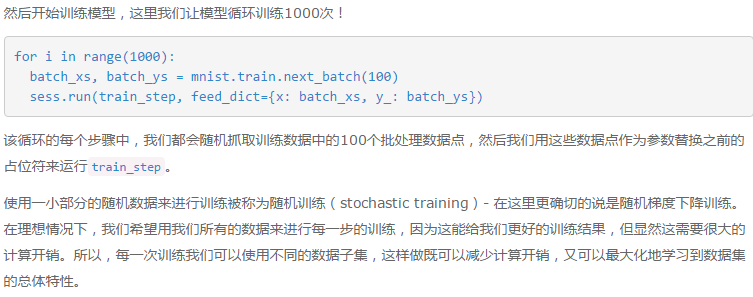
在官方文档中,采用的是1000次迭代,每次随机选取100个数据集进行训练。 最后的精确值为91%左右。
提高迭代次数到10000次,随机选取任是100个时,精确值为92%左右。可以理解,毕竟多次迭代。
然而当迭代为10000次,每次1000个数据集时,精确度仅有9.8%,相当于等概率随机猜。正常来说应该会提高精确度,然而不是。
原因是:
随机梯度最后不收敛导致的。

官方文档中采用交叉熵来计算loss,特点是当loss大的时候,反映在w和b上也特别明显。然而当数据集变大的时候,loss也随之变大,
以0.01的学习率去学习,很可能就导致了不收敛,而导致此结果。。
因此,实验中,需要降低学习率,本人设为0.001时,精确度再次上升为92.5%左右。















 3276
3276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









