







精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页:计算机毕设老哥🔥 💖
Java实战项目专栏
Python实战项目专栏
安卓实战项目专栏
微信小程序实战项目专栏
文章目录
一、开发介绍
1.1 开发环境
- 技术栈:spark+hadoop+hive
- 离线ETL+在线数据分析 (OLAP)+流计算+机器学习+图计算
二、系统介绍
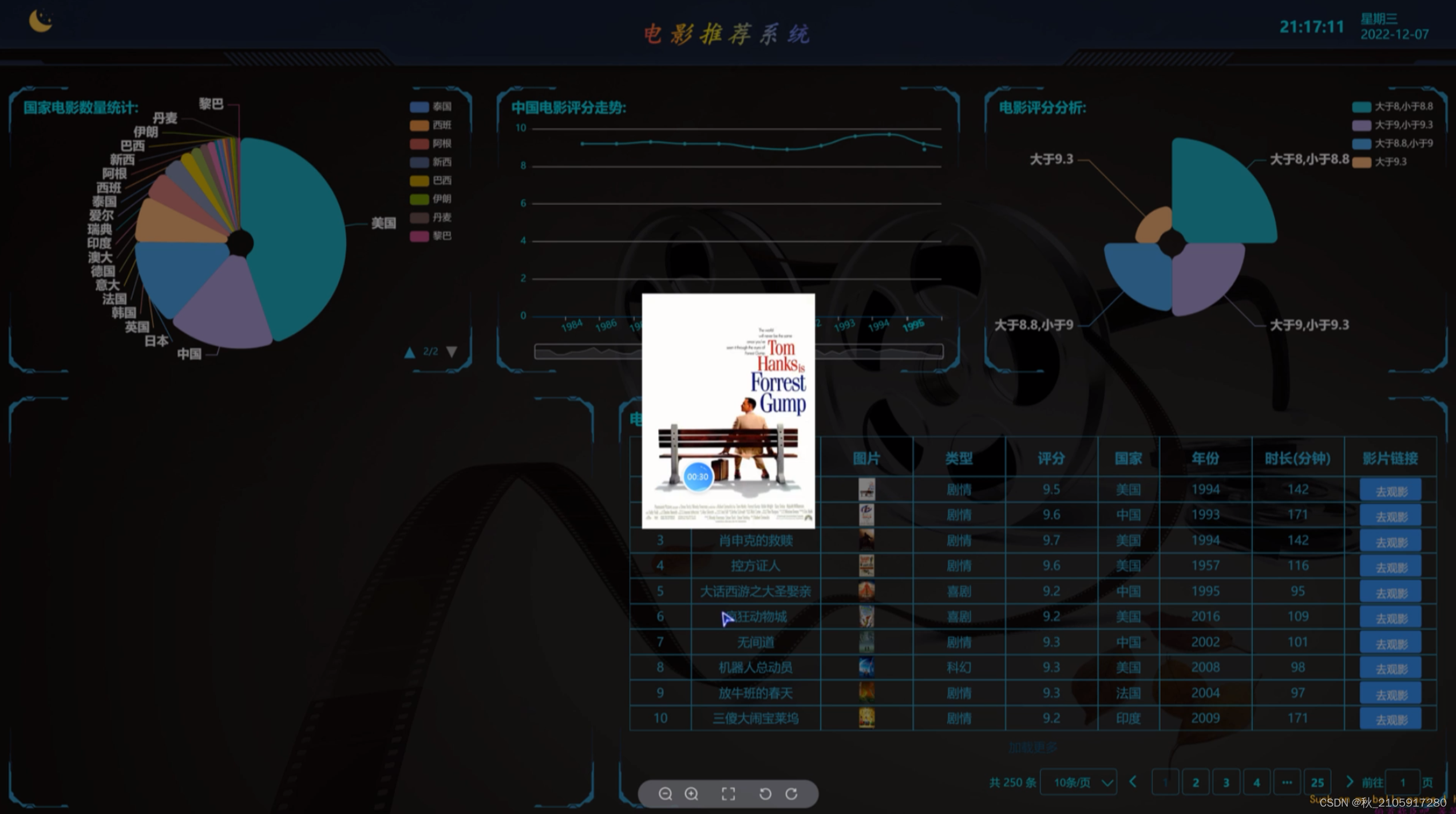
2.1图片展示
用户登陆页面
首页模块:
三、部分代码设计
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.spark.platform.admin.biz.dao.role.RoleDao">
<resultMap id="BaseResultMap" type="com.spark.platform.admin.api.entity.role.Role">
<id column="id" jdbcType="BIGINT" property="id"/>
<result column="role_name" jdbcType="VARCHAR" property="roleName"/>
<result column="role_code" jdbcType="VARCHAR" property="roleCode"/>
<result column="description" jdbcType="VARCHAR" property="description"/>
<result column="dept_id" jdbcType="BIGINT" property="deptId"/>
<result column="dept_name" jdbcType="VARCHAR" property="deptName"/>
<result column="status" jdbcType="INTEGER" property="status"/>
<result column="creator" jdbcType="INTEGER" property="creator"/>
<result column="modifier" jdbcType="INTEGER" property="modifier"/>
<result column="create_date" jdbcType="TIMESTAMP" property="createDate"/>
<result column="modify_date" jdbcType="TIMESTAMP" property="modifyDate"/>
<result column="remarks" jdbcType="INTEGER" property="remarks"/>
<result column="del_flag" jdbcType="INTEGER" property="delFlag"/>
</resultMap>
<sql id="Base_Column_List">
id, role_name, role_code, create_date, description, dept_id,dept_name
</sql>
<select id="getRoleByUserId" parameterType="long" resultMap="BaseResultMap">
SELECT su.id,role_name,role_code,create_date,description,dept_id,dept_name
FROM sys_role su
LEFT JOIN sys_user_role sr ON sr.role_id = su.id
WHERE sr.user_id = ${userId}
</select>
</mapper>
package ${package.Controller};
import org.springframework.web.bind.annotation.RequestMapping;
import ${package.Service}.${table.serviceName};
import ${package.Entity}.${entity};
import com.spark.platform.common.base.support.ApiResponse;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.DeleteMapping;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.PutMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
<#if restControllerStyle>
import org.springframework.web.bind.annotation.RestController;
<#else>
import org.springframework.stereotype.Controller;
</#if>
<#if superControllerClassPackage??>
import ${superControllerClassPackage};
</#if>
/**
* <p>
* ${table.comment!} api访问层
* </p>
*
* @author ${author}
* @since ${date}
*/
<#if restControllerStyle>
@RestController
<#else>
@Controller
</#if>
@RequestMapping("<#if package.ModuleName??>/${package.ModuleName}</#if>/<#if controllerMappingHyphenStyle??>${controllerMappingHyphen}<#else>${table.entityPath}</#if>")
<#if kotlin>
class ${table.controllerName}<#if superControllerClass??> : ${superControllerClass}()</#if>
<#else>
@Api(tags = "${table.comment!}")
@RequiredArgsConstructor
<#if superControllerClass??>
public class ${table.controllerName} extends ${superControllerClass} {
<#else>
public class ${table.controllerName} {
</#if>
private final ${table.serviceName} ${table.serviceName ? uncap_first};
@GetMapping("/page")
@ApiOperation(value = "${table.comment!}列表")
public ApiResponse page(${entity} ${entity ? uncap_first}, Page page){
return success(${table.serviceName ? uncap_first}.page(page,Wrappers.query(${entity ? uncap_first})));
}
@PostMapping
@ApiOperation(value = "保存${table.comment!}信息")
public ApiResponse save(@RequestBody ${entity} ${entity ? uncap_first}){
return success(${table.serviceName ? uncap_first}.save(${entity ? uncap_first}));
}
@PutMapping
@ApiOperation(value = "更新${table.comment!}信息")
public ApiResponse update(@RequestBody ${entity} ${entity ? uncap_first}){
return success(${table.serviceName ? uncap_first}.updateById(${entity ? uncap_first}));
}
@DeleteMapping("/{id}")
@ApiOperation(value = "删除${table.comment!}")
public ApiResponse delete(@PathVariable Long id){
return success(${table.serviceName ? uncap_first}.removeById(id));
}
@GetMapping("/{id}")
@ApiOperation(value = "根据id获取${table.comment!}信息")
public ApiResponse getById(@PathVariable Long id) {
return success(${table.serviceName ? uncap_first}.getById(id));
}
}
</#if>
package com.spark.platform.admin.api.feign.client;
import com.spark.platform.admin.api.entity.authority.OauthClientDetails;
import com.spark.platform.common.base.constants.ServiceNameConstants;
import com.spark.platform.common.feign.config.FeignRequestInterceptorConfig;
import com.spark.platform.admin.api.feign.fallback.AuthorityClientFallBackFactory;
import com.spark.platform.common.base.support.ApiResponse;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
/**
* @author: wangdingfeng
* @ProjectName: spark-platform
* @Package: com.spark.platform.adminapi.feign.client
* @ClassName: AuthorityClient
* @Description:
* @Version: 1.0
*/
@FeignClient(contextId = "authorityClient", name = ServiceNameConstants.SPARK_ADMIN, configuration = FeignRequestInterceptorConfig.class, fallbackFactory = AuthorityClientFallBackFactory.class)
public interface AuthorityClient {
/**
* 根据clientId获取认证客户端详情信息
* @param clientId
* @return
*/
@GetMapping("/authority/api/info")
ApiResponse<OauthClientDetails> getOauthClientDetailsByClientId(@RequestParam("clientId") String clientId);
总结
大家可以帮忙点赞、收藏、关注、评论啦
有问题评论区交流
精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻
Java实战项目专栏
Python实战项目专栏
安卓实战项目专栏
微信小程序实战专栏














 5660
5660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









