







Regularization
The Problem of Overfitting
拟合效果不好有两种情况:
欠拟合(Underfitting),指的是预测值和training set匹配程度较差。
过拟合(Overfitting),指的是拟合曲线过度追求吻合training set,可能被一些噪音干扰,偏离实际情况。当
数据的参数过多时容易发生这种情况。
解决过拟合有两种方法:
1.减少参数数量,可以人为选择使用哪些参数,也可使用模型选择算法(后面会讲)。但是这可能会导致丢
失信息。
2.正则化(regularization),调整每个参数的权重。
Cost Function
θ参数越小,曲线将会越平滑,越不容易Overfitting。
因此构造新的Cost Function
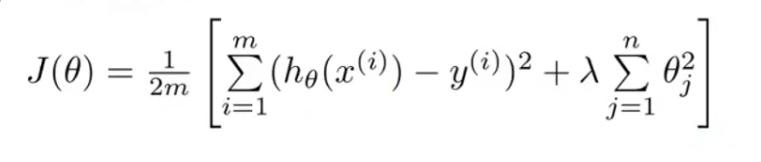
这个函数的前半部分(原Cost Function),控制拟合曲线尽量接近training set,后半部分控制θ参数尽可能
小。正则参数λ控制正则化的程度,λ越大拟合曲线的匹配程度越小。
Regularized Linear Regression
正则化的梯度下降公式为:
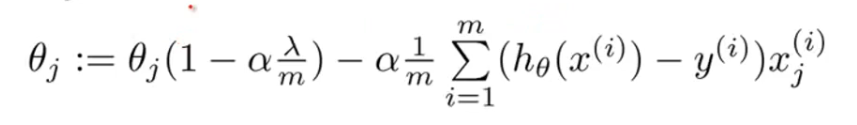
(j>0)
因此(1-a*λ/m)需要<1才能起到逐步缩小θ的作用。
正则化的正规方程法公式:
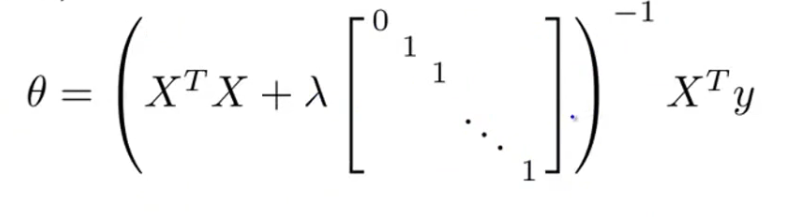
X是一个m*n矩阵,如果m<=n,那么X’ * X将是一个奇异矩阵(没有逆),pinv也许能得出一个答案,因为
这求得其实是伪逆矩阵,inv则无法得出答案。幸运的是正则化也可以解决这个问题,当λ大于0时,上面这个
新矩阵一定是非奇异的。
Regularized Logistic Regression
正则化的梯度下降方程:
θ2 =θ2 -
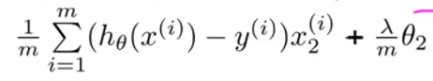















 3203
3203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









