









引言
前面我们已经简单地介绍了 Kubernetes 的常用资源,本文我们将介绍 Kubernetes 的实现方案。更多相关文章和其他文章均收录于贝贝猫的文章目录。
Kubernetes 实现原理
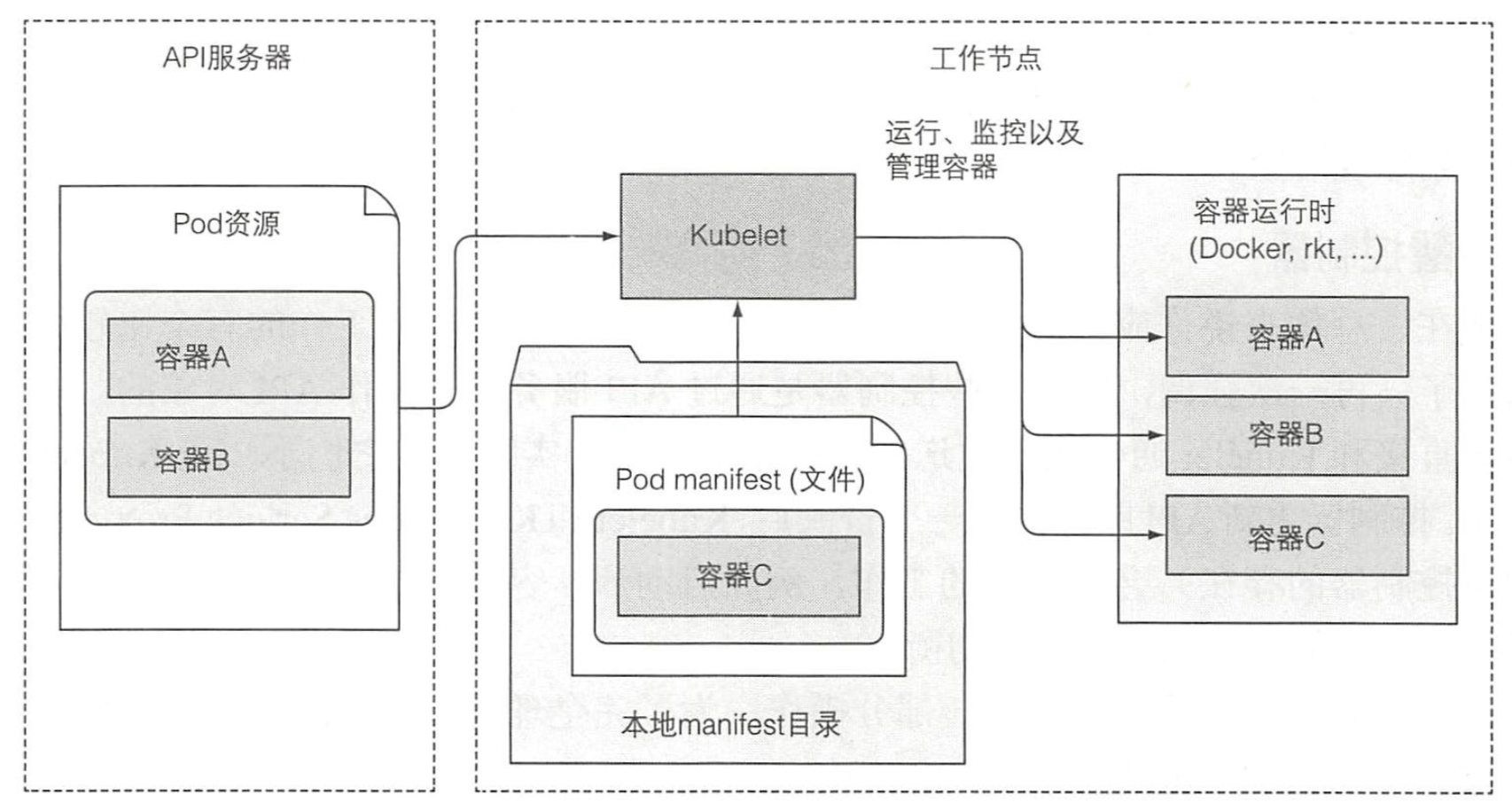
现在我们已经知道了大多数可以部署到 Kubernetes 的资源,现在是时候了解下它们是怎么被实现的了。我们知道 Kubernetes 有两种节点,控制节点和工作节点。控制平面负责控制并使得整个集群正常运转,包括 etcd,API 服务器,调度器,控制器管理器,这些组件用来存储、 管理集群状态,但它们不是运行应用的容器。工作节点包括 kubelet,kube-proxy,容器运行时(docker|rkt)。除了这些之外,还有 DNS 服务器,Dashboard 服务,Ingress 控制器,容器网络插件,容器集群监控等。
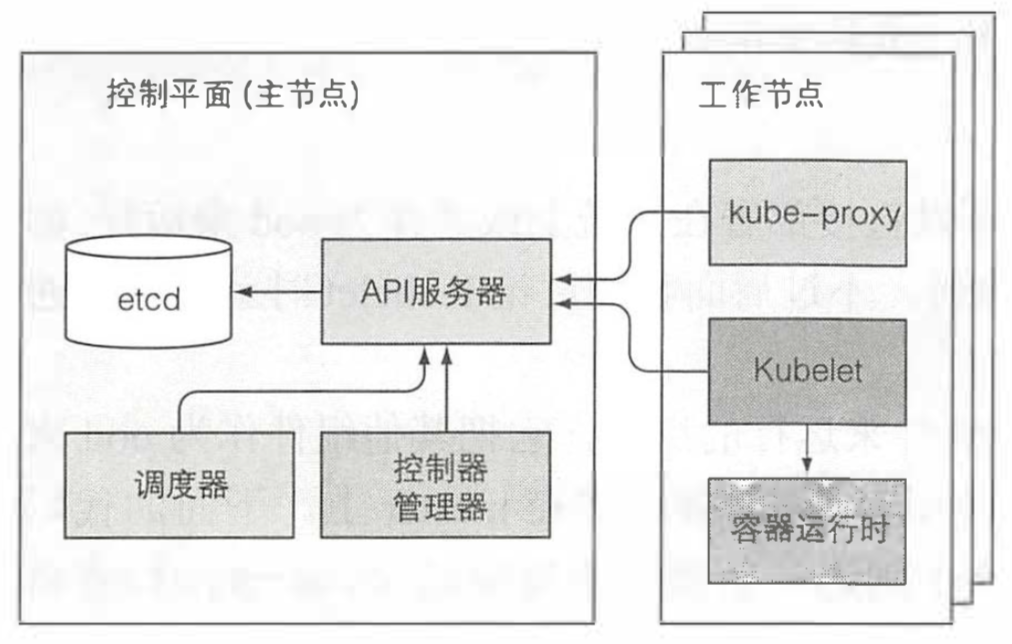
Kubernetes 系统组件间只能通过 API 服务器通信,它们之间不会直接通信。API 服务器是和 etcd 通信的唯一组件。其他组件不会直接和 etcd 通信,而是通过 API 服务器来修改集群状态。API服务器和其他组件的连接基本都是由组件发起的,如图上所示。但是,当你使用 kubectl 获取日志、使用 kubectl attach 连接到一个运行中的容器或运行 kubectl port-forward 命令时,API服务器会向 Kubelet 发起连接。
尽管工作节点上的组件都需要运行在同一个节点上,控制平面的组件可以被简单地分割在多台服务器上。为了保证高可用性,控制平面的每个组件可以有多个实例。etcd 和 API 服务器的多个实例可以同时并行工作,但是,调度器和控制器管理器在同一时刻只有一个实例起作用,其他都处于待命状态。
说出来你可能不相信,控制面板的组件以及 kube-proxy 可以直接部署在系统上或者作为 pod 来运行,kubelet 是唯一一直作为常规系统组件来运行的组件,它把其他组件作为 pod 来运行,就比如控制面板的 api 服务器,调度器,控制器管理器都是作为 pod 运行的,只不过这些 pod 都是静态 pod,kubelet 在启动后会检查一个存储静态 pod 的目录,然后将其中的 pod 启动。
etcd 是一个响应快、分布式、一致的 key-value 存储。因为它是分布式的,故可以运行多个 etcd 实例来获取高可用性和更好的性能。
唯一能直接和 etcd 通信的是 Kubernetes 的 API 服务器。所有其他组件通过 API 服务器间接地读取、写入数据到 etcd。这带来一些好处,其中之一就是增强乐观锁系统、验证系统的健壮性;并且,通过把实际存储机制从其他组件抽离,未来替换起来也更容易。值得强调的是,etcd 是 Kubernetes 存储集群状态和元数据的唯一的地方。
乐观并发控制(有时候指乐观锁)是指一段数据包含一个版本数字,而不是锁住该段数据并阻止读写操作。每当更新数据,版本数就会增加。当更新数据时,就会检查版本值是否在客户端读取数据时间和提交时间之间被增加过。 如果增加过,那么更新会被拒绝,客户端必须重新读取新数据,重新尝试更新。
Kubernetes API服务器作为中心组件, 其 他组件或者客户端(如kubectl)都 会去调用它。以 RESTful API的形式提供了可以查询、修改集群状态的 CRUD(Create、Read、Update、Delete)接口。它将状态存储到 etcd 中。
首先,API 服务器需要认证发送请求的客户端。这是通过配置在 API 服务器上的一个或多个认证插件来实现的。API 服务器会轮流调用这些插件,直到有一个能确认是谁发送了该请求。除了认证插件,API 服务器还可以配置使用一个或多个授权插件。它们的作用是决定认证的用户是否可以对请求资源执行请求操作。如果请求尝试创建、修改或者删除一个资源,请求需要经过准入控制插件的验证。同理,服务器会配置多个准入控制插件。这些插件会因为各种原因修改资源,可能会初始化资源定义中漏配的字段为默认值甚至重写它们。插件甚至会去修改并不在请求中的相关资源,同时也会因为某些原因拒绝一个请求。资源需要经过所有准入控制插件的验证。
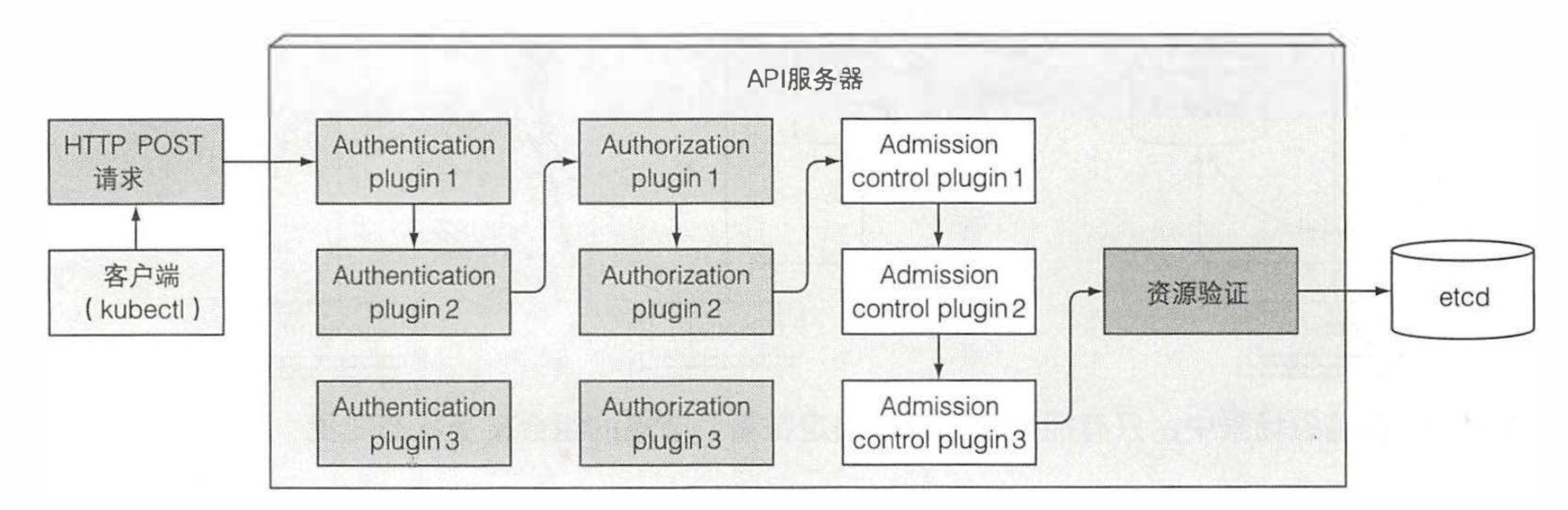
除了前面讨论的,API 服务器没有做其他额外的工作。例如,当你创建一个 ReplicaSet 资源时,它不会去创建 pod, 同时它不会去管理服务的端点。那是控制器管理器的工作。其他组件通过建立和 API 服务器的连接来监听元数据的变化,当 API server 将元数据变化的事件发送到客户端后,客户端会自动做相应的工作。
调度器
前面已经学习过,我们通常不会去指定 pod 应该运行在哪个集群节点上,这项工作交给调度器。宏观来看,调度器的操作比较简单。就是利用 API 服务器的监听机制等待新创建的 pod, 然后给每个新的、没有节点集的 pod 分配节点。
调度器不会命令选中的节点(或者节点上运行的Kubelet) 去运行pod。调度器做的就是通过 API 服务器更新 pod 的定义。然后 API 服务器再去通知 Kubelet(同样,通过之前描述的监听机制)该 pod 已经被调度过。当目标节点上的 Kubelet 发现该 pod 被调度到本节点,它就会创建并且运行 pod 的容器。
我们可以使用自定义的调度器,比如基于机器学习来感知业务高峰,从而自动进行扩容,当然,默认的调度算法还是比较简单的,它的工作流程如下:
- 过滤所有节点,找出能分配给 pod 的可用节点列表。
- 节点是否能满足 pod 对硬件资源的请求。
- 节点是否耗尽资源。
- pod 是否要求被调度到指定节点
- 节点是否有和 pod 规格定义里的节点选择器一致的标签
- 如果 pod 要求绑定指定的主机端口那么这个节点上的这个端口是否已经被占用?
- 如果 pod 要求有特定类型的卷,该节点是否能为此 pod 加载此卷,或者说该节点上是否已经有 pod 在使用该卷了
- pod 是否能够容忍节点的污点。
- pod 是否定义了节点、pod 的亲缘性以及非亲缘性规则?如果是,那么调度节点给该 pod 是否会违反规则?
- 所有这些测试都必须通过,节点才有资格调度给 pod。在对每个节点做过这些检查后,调度器得到节点集的一个子集。任何这些节点都可以运行 pod, 因为它们都有足够的可用资源,也确认过满足 pod 定义的所有要求。
- 对可用节点按优先级排序,找出最优节点。如果多个节点都有最高的优先级分数,那么则循环分配,确保平均分配给 pod。
控制器管理器
如前面提到的,API 服务器只做了存储资源到 etcd 和通知客户端有变更的工作。调度器则只是给 pod 分配节点,所以需要有活跃的组件确保系统真实状态朝 API 服务器定义的期望的状态收敛。这个工作由控制器管理器里的控制器来实现。控制器包括:
- Replication 管理器
- ReplicaSet、DaemonSet 以及 Job 控制器
- Deployment 控制器
- StatefulSet 控制器
- Node 控制器
- Service 控制器
- Endpoints 控制器
- Namespace 控制器
- PersistentVolume 控制器
- 其他
总的来说,控制器执行一个“调和“循环,将实际状态调整为期望状态(在资源 spec 部分定义),然后将新的实际状态写入资源的 status 部分。
Replication
ReplicationController 的操作可以理解为一个无限循环,每次循环,控制器都会查找符合其 pod 选择器定义的 pod 的数量,并且将该数值和期望的复制集 (replica) 数量做比较。控制器不会每次循环去轮询 pod, 而是通过监听机制订阅可能影响期望的复制集 (replica) 数量或者符合条件 pod 数量的变更事件。任何该类型的变化,将触发控制器重新检查期望的以及实际的复制集数量,然后做出相应操作。当运行的 pod 实例太少时,ReplicationController 会运行额外的实例,但它自己实际上不会去运行 pod。它会创建新的 pod 清单,发布到 API 服务器,让调度器以及 Kubelet 来做调度工作并运行 pod。
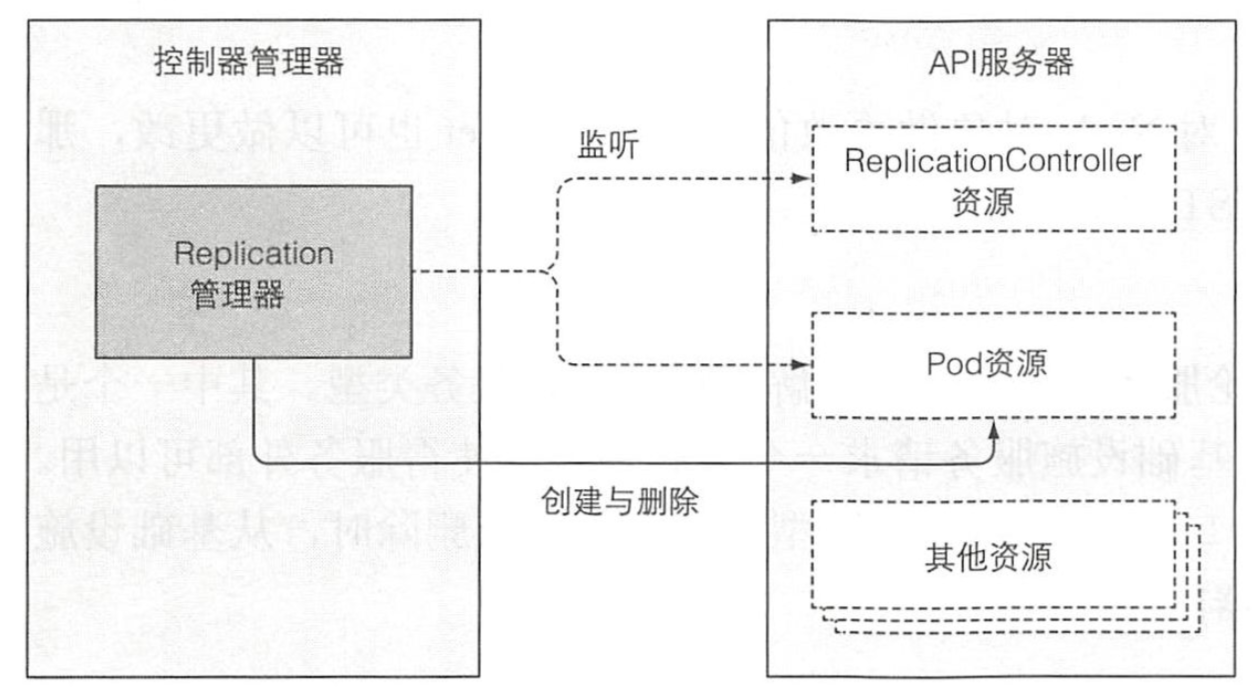
ReplicaSet 控制器基本上做了和前面描述的 Replication 管理器一样的事情,所以这里不再赘述。DaemonSet 以及 Job 控制器比较相似,从它们各自资源集中定义的 pod 模板创建 pod 资源。
Deployment资源
Deployment 控制器负责使 deployment 的实际状态与对应 Deployment API 对象的期望状态同步。
每次 Deployment 对象修改后(如果修改会影响到部署的 pod), Deployment 控制器都会滚动升级到新的版本。通过创建一个 ReplicaSet,然后按照 Deployment 中定义的策略同时伸缩新、旧 ReplicaSet,直到旧 pod 被新的代替。并不会直接创建任何 pod。
StatefulSet
StatefulSet 控制器,类似于 ReplicaSet 控制器以及其他相关控制器,根据 StatefulSet 资源定义创建、管理、删除 pod。其他的控制器只管理 pod,而 StatefulSet 控制器会初始化并管理每个 pod 实例的持久卷声明字段。
Node
Node 控制器管理 Node 资源,描述了集群工作节点。其中,Node 控制器使节点对象列表与集群中实际运行的机器列表保持同步。同时监控每个节点的健康状态,删除不可达节点的 pod。
Service 控制器
Service 控制器就是用来在 LoadBalancer 类型服务被创建或删除时,从基础设施服务请求、释放负载均衡器的。
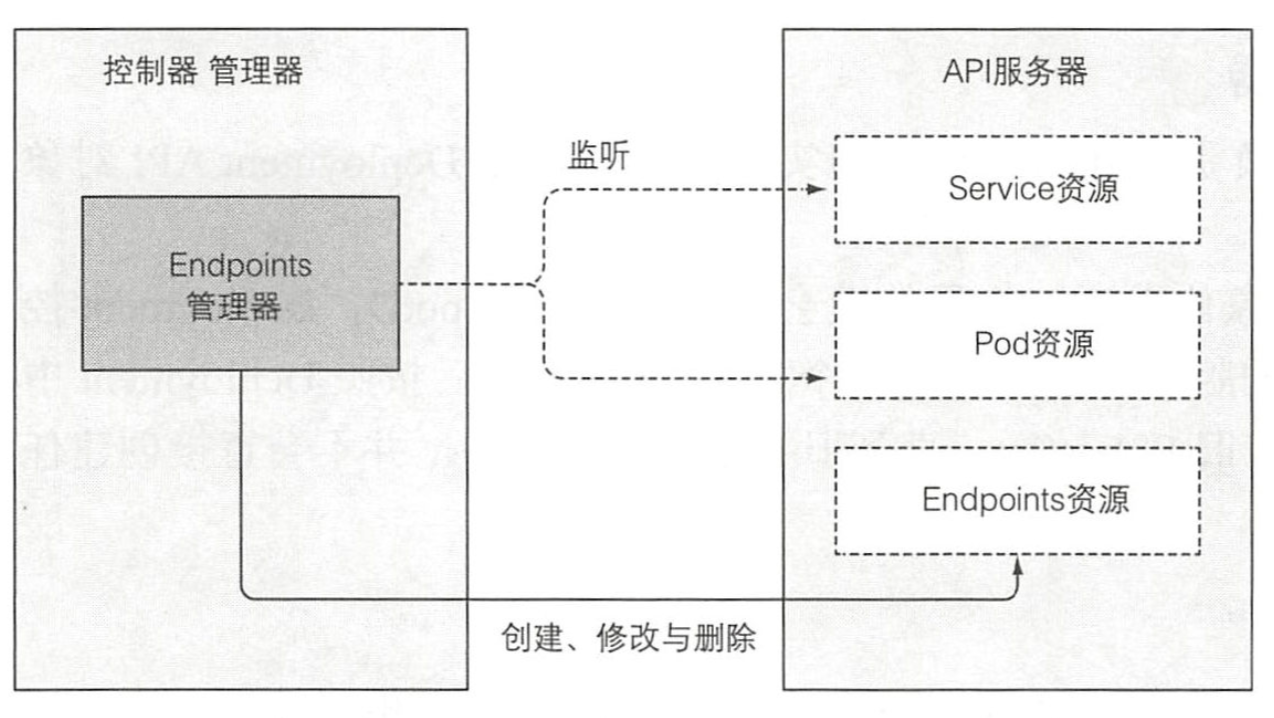
Endpoint
您可能还记得,Service 不会直接连接到 pod,而是包含一个端点列表 (Ip 和端口),列表要么是手动,要么是根据 Service 定义的 pod 选择器自动创建、更新。
当 Service 被添加、修改,或者 pod 被添加、修改或删除时,控制器会选中匹配 Service 的 pod 选择器的 pod, 将其 ip 和端口添加到 Endpoint 资源中。请记住,Endpoint 对象是个独立的对象,所以当需要的时候控制器会创建它。同样地,当删除 Service时,Endpoint对象也会被删除。
Namespace
当删除一个 Namespace 资源时,该命名空间里的所有资源都会被删除。这就是 Namespace 控制器做的事情。
PersistentVolume
一旦用户创建了一个持久卷声明,Kubernetes 必须找到一个合适的持久卷同时将其和声明绑定。这些由持久卷控制器实现。对于一个持久卷声明,控制器为声明查找最佳匹配项,通过选择匹配声明中的访问模式,并且声明的容量大于需求的容量的最小持久卷。
当用户删除持久卷声明时,会解绑卷,然后根据卷的回收策略进行回收(原样保留、删除或清空)。
控制器协作
下面,我会以一个 Deployment 资源的创建为例,介绍控制器之间的协作:

kubelet
简单地说,Kubelet 就是负责所有运行在工作节点上内容的组件。它第一个任务就是在 API 服务器中创建一个 Node 资源来注册该节点。然后需要持续监控 API 服务器是否把该节点分配给 pod,然后启动 pod 容器。
Kubelet 也是运行容器存活探针的组件,当探针报错时它会重启容器。最后一点,当 pod 从 API 服务器删除时,Kubelet 终止容器,并通知服务器 pod 己经被终止了。
尽管 Kubelet 一般会和 API 服务器通信并从中获取 pod 清单,它也可以基于本地指定目录下的 pod 清单来运行 pod,这就是前面说的静态 pod。
kube-proxy
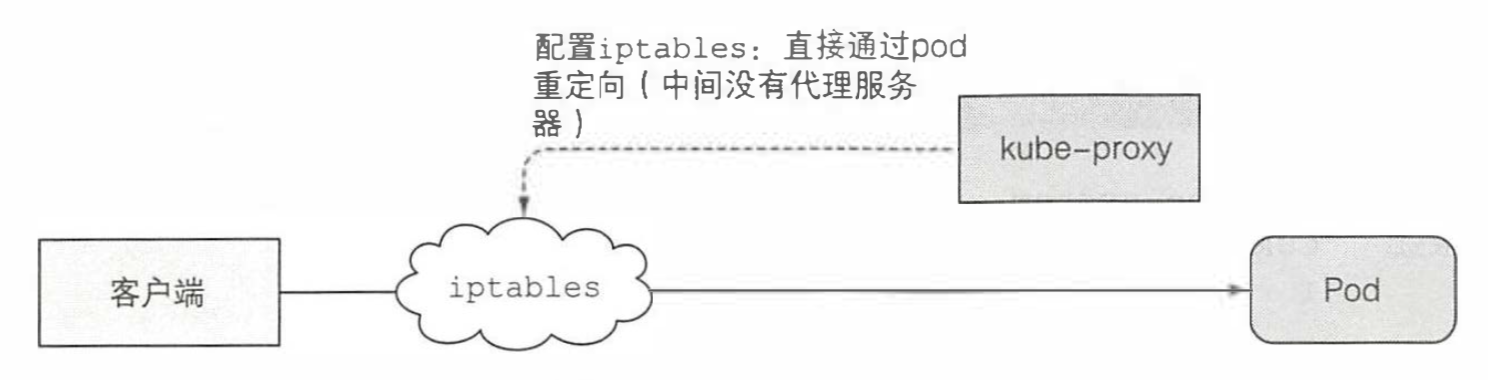
除了 Kubelet,每个工作节点还会运行 kube-proxy,用于确保客户端可以通过 Kubernetes API 连接到你定义的服务。kube-proxy 确保对服务 IP 和端口的连接最终能到达支持服务(或者其他,非 pod 服务终端)的某个 pod 处。如果有多个 pod 支 撑一个服务,那么代理会发挥对 pod 的负载均衡作用。
现在默认的 kube-proxy 实现是通过配置 iptables 直接通过重定向到满足条件的 pod 中。
插件
我们已经讨论了 Kubernetes 集群正常工作所需要的一些核心组件。但是除了这些核心组件之外,还有一些可有可无的插件。这些插件用于启用 Kubernetes 服务的 DNS 查询,通过单个外部 IP 暴露多个 HTTP 服务,Kubernetes 仪表盘等。
DNS
集群中的所有 pod 默认配置使用集群内部DNS服务器。这使得 pod 能够轻松地通过名称查询到服务,甚至是无头服务 pod 的 IP 地址。kube-dns pod 利用 API 服务器的监控机制来订阅 Service 和 Endpoint 的变动,以及 DNS 记录的变更,使得其客户端(相对地)总是能够获取到最新的 DNS 信息。
Ingress
Ingress 控制器运行一个反向代理服务器(例如,类似Nginx), 根据集群中定义的 Ingress、Service 以及 Endpoint 资源来配置该控制器。所以需要订阅这些资源(通过监听机制),然后每次其中一个发生变化则更新代理服务器的配置。
Pod 模块
前面我们介绍过 pod 是什么,这里我们再简单地说一下,当你创建一个 pod 时实际运行的是 Docker。但是它不是简单运行一个 docker 镜像,在启动真正的镜像之前,它会先启动一个附加容器,这个容器没有做任何事,容器命令是 pause。该容器将一个 pod 所有的容器收纳到一起。还记得一个 pod 的所有容器是如何共享同一个网络和 Linux 命名空间的吗?暂停的容器是一个基础容器,它的唯一目的就是保存所有的命名空间。所有 pod 的其他用户定义容器使用 pod 的该基础容器的命名空间。
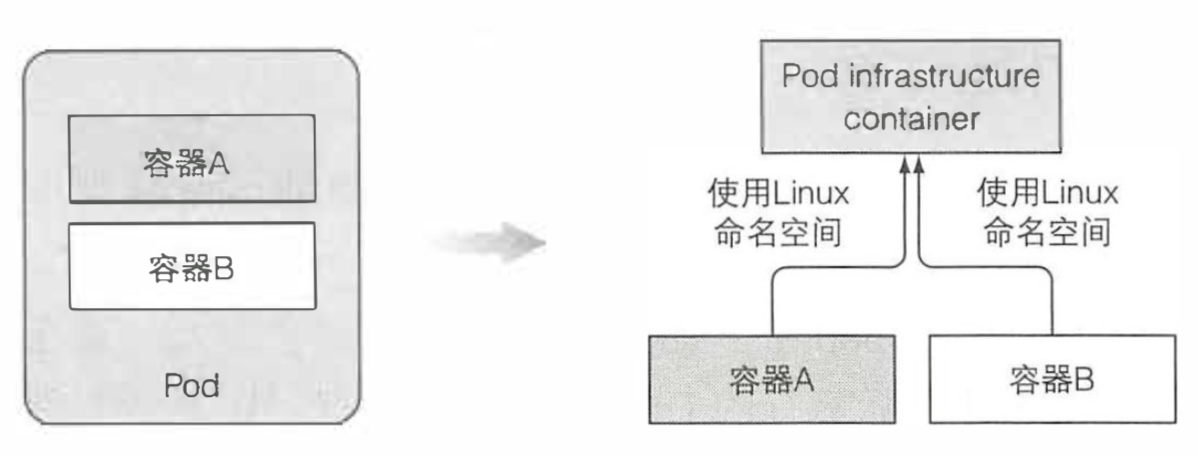
实际的应用容器可能会挂掉并重启。当容器重启,容器需要处于与之前相同的 Linux 命名空间中。基础容器使这成为可能,因为它的生命周期和 pod 绑定,基础容器 pod 被调度直到被删除一直会运行。如果基础 pod 在这期间被关闭,Kubelet 会重新创建它,并且会重建 pod 的所有容器。
高可用
在 Kubernetes 上运行应用的一个理由就是,保证运行不被中断,或者说尽量少地入工介入基础设施导致的宕机。为了能够不中断地运行服务,不仅应用要一直运行,Kubernetes 控制平面的组件也要不间断运行。接下来我们了解一下达到高可用性需要做到什么。
- 运行多实例来减少宕机可能性
- 需要你的应用可以水平扩展,不过即使不可以,仍然可以使用 Deployment, 将复制集数量设为1。
- 对不能水平扩展的应用使用领导选举机制
- 为了避免宕机,需要在运行一个活跃的应用的同时再运行一个附加的非活跃复制集
- 让 Kubernetes 控制面板高可用,就像我在试玩环节使用的模式
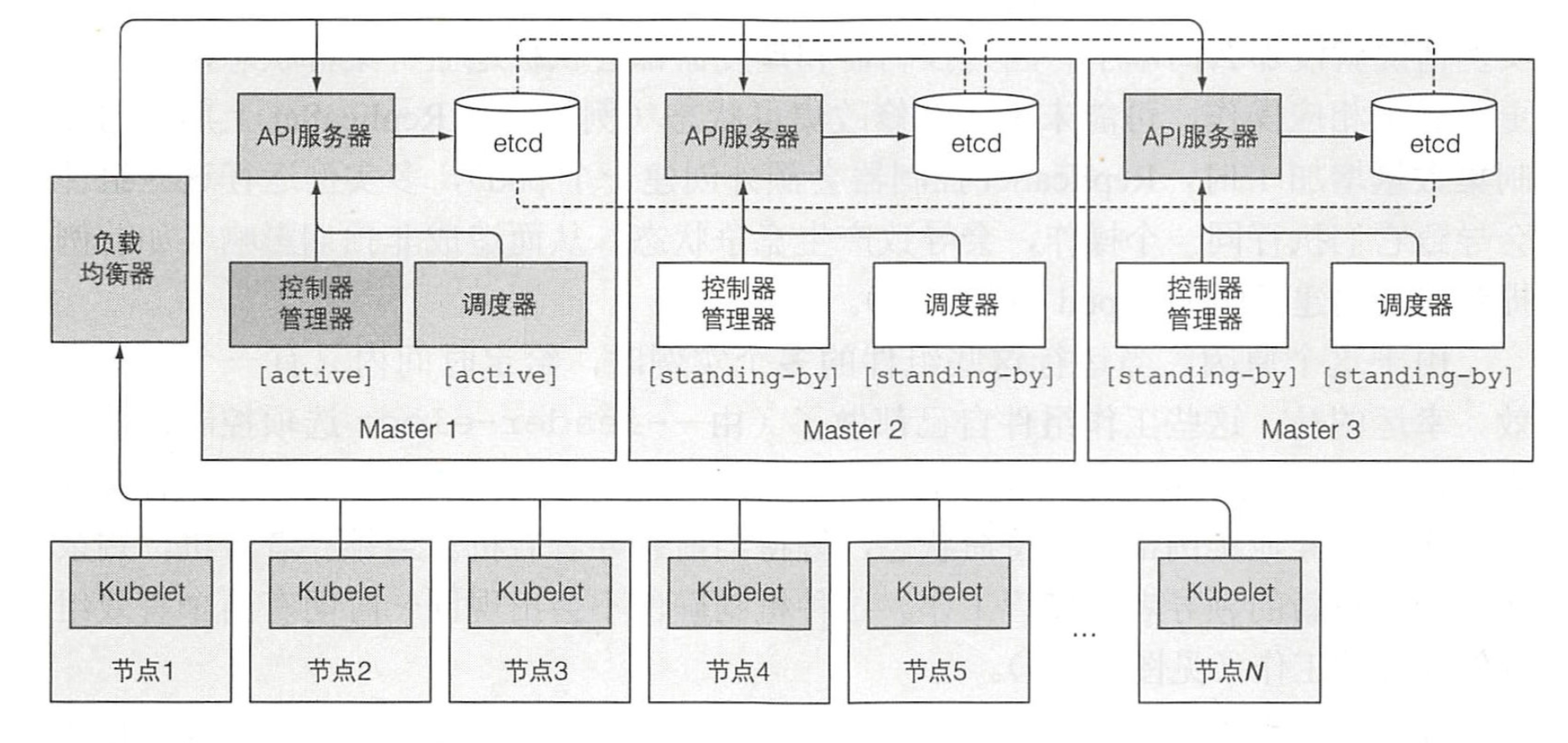
- 运行 etcd 集群
- 运行多实例 API 服务器
- 确保控制器和调度器的高可用性,领导人选举
参考内容
[1] kubernetes GitHub 仓库
[2] Kubernetes 官方主页
[3] Kubernetes 官方 Demo
[4] 《Kubernetes in Action》
[5] 理解Kubernetes网络之Flannel网络
[6] Kubernetes Handbook
[7] iptables概念介绍及相关操作
[8] iptables超全详解
[9] 理解Docker容器网络之Linux Network Namespace
[10] A Guide to the Kubernetes Networking Model
[11] Kubernetes with Flannel — Understanding the Networking
[12] 四层、七层负载均衡的区别
















 1237
1237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











