






kafka概述
Kafka是一个流行的分布式消息系统,被广泛应用于各种实时数据处理场景中。然而,它与其他一些分布式数据库系统不同之处在于,它不支持主从同步。这篇文章将探讨Kafka为何不支持主从同步,下图是mysql的主从结构图。
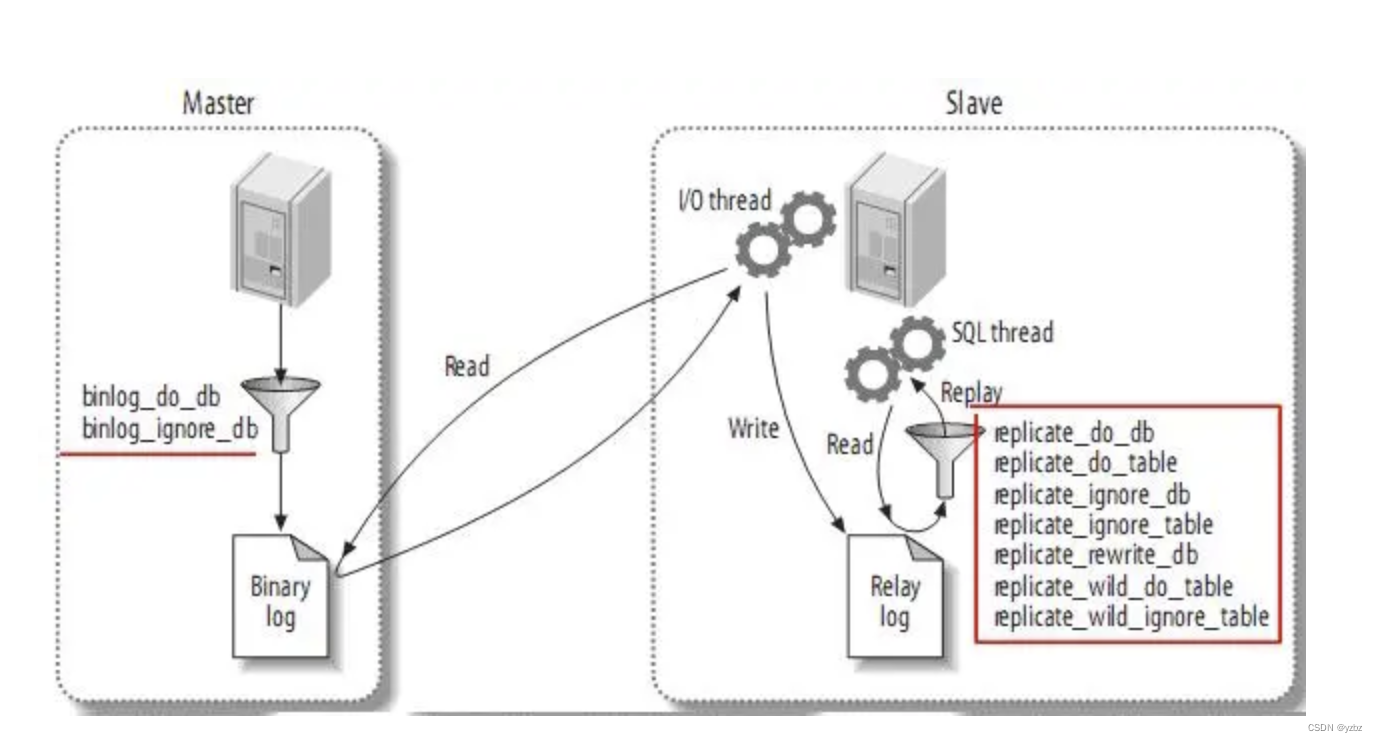
首先,我们需要了解Kafka的设计目标和应用场景。Kafka旨在提供高吞吐量、低延迟的消息传输服务,通常用作实时数据流处理、日志聚合和事件驱动架构等领域。相比于其他数据库系统,Kafka采用了一种完全不同的数据复制策略,即基于发布/订阅模型,而非主从同步。
主从概述
主从同步是一种常见的数据复制方式,其中一个节点作为主节点,负责写操作,并将写入的数据同步到所有从节点上。从节点只能读取数据,无法写入任何数据。这种方式通常用于关系型数据库系统中,以提高数据可用性和防止单点故障。
但是,对于Kafka而言,主从同步并不适合其设计目标和应用场景。因为Kafka的核心特性是分布式多副本复制机制,其中每个副本都可以独立地读写数据,而不必通过主节点进行同步。这种方式可以大大提高数据的可用性和可靠性,因为即使某个节点宕机,其他副本仍然可以接管其工作,保证数据的正常传输。
二者差别
此外,Kafka还采用了一种分区机制,将每个主题分成多个分区,每个分区可以独立地进行读写操作。这种机制与主从同步是不兼容的。
因为在主从同步中,所有的写操作都需要通过主节点进行同步,而无法并行处理多个分区的数据。
最后,Kafka还采用了一种异步复制机制,即不保证数据的实时同步。这种方式虽然可能会导致数据的延迟和不一致性,但它能够大大提高系统的吞吐量和性能,使得Kafka可以处理海量的实时数据流。
总结
综上所述,尽管主从同步是一种常见的数据复制方式,但它不适合Kafka的设计目标和应用场景。Kafka采用了一种完全不同的数据复制策略,即基于发布/订阅模型和分布式多副本复制机制,并通过分区和异步复制等机制来提高系统的吞吐量和可用性。















 156
156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









