







版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Bernice_lying
# YOLO:You only look once#
方法如其名,仅需看一次图像,即可预测存在的物体和相对应的坐标位置,它追求“秒识”体验,有着“fast & accurate”的检测表现。它的建模思想是将检测问题转化为回归问题。
官方源码: http://pjreddie.com/yolo/下面将介绍YOLO系列第一部YOLOv1:
## YOLO-v1【参考】
- https://blog.csdn.net/qq_14845119/article/details/53612362
- https://blog.csdn.net/hrsstudy/article/details/70305791(图文详细解说)
- https://zhuanlan.zhihu.com/p/24916786?utm_source=qq&utm_medium=social
使用来自于完整图像的特征来预测每一个bounding box,也就是在一张图像上完成所有bounding box对于所有class的预测。
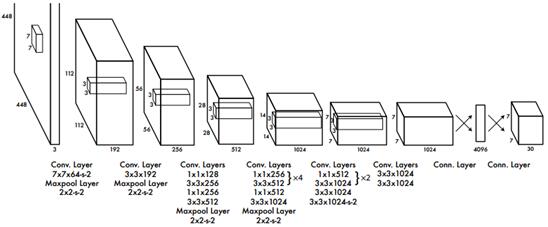
图1 YOLOv1检测网络结构
【网络设计】
- 卷积层实现特征提取,全连接层实现输出类别和坐标预测;
- 共有24层卷积网络+2全连接层;
- 网络模块参考GoogLeNet网络Inception结构,但仅使用1×1压缩层+3×3卷积层组合模块;
- 网络输出7×7×30的张量用于最终的分类和位置预测。
- 卷积层和使用Leaky rectified linear activation(LReLU)激活函数:
if x>0, g(x)=x, g(x)=0.1x for else;
【技术细节(检测部分)】
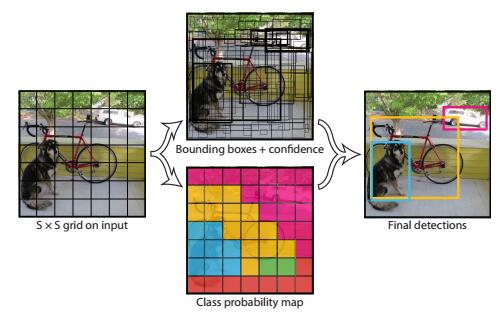
图2 图像网格化示意
在特征提取网络获取全图特征信息后,会得到一个大小为M×N的特征图,我们对这张特征图进行网格化,变成S×S的网格形式,如上图2所示。并且将每个 真实物体的中心落在其中一个 cell中心点,也就是让这个cell来负责这个物体的检测(体现一种grid和object的一一对应关系)。那么每个cell具体是如何预测的呢?
每个cell的预测内容:
(1)B个bounding boxes,包含box的坐标预测和置信度预测。
坐标预测包含box的中心点坐标(x,y),它们的度量相对于grid cell边界而言,和宽高w,h,它们是相对于整个图像而言度量的。
这里的置信度指的是box包含一个物体且这个box预测的有多准的程度,即Pr(Object)*IOU_truth&pred。若cell中不存在物体,置信度得分为0,否则将等于预测的box和任一存在的真实标注之间的IOU值。
(2)C个条件类别概率,即Pr(Class_i|Object),它表示当cell存在一个物体时,这个物体为第i类的条件概率。
在测试时,将使用条件类别概率与box置信度的乘积结果来获得一个类别敏感的置信度得分,它既包含bounding box预测的类别概率信息,又包含是否存在object和位置预测的准确度信息:

综上,整个S×S的grid进行的预测应为:S×S×(B×5+C),以张量形式保存,论文中S=7,B=2,C=20(PASCAL VOC),因此最终预测是7×7×30。

图3 网格化张量预测

图4 张量示意

图5 类别预测示意

图6 全图类别预测示意
这里大家可能会有一个疑问:B个bounding boxes的预测能力,即到底能预测几个,并且物体类别时不一样还是一样的?
博主的答复:一个cell既然给定了B个bounding boxes,那么就可以支持B个物体的预测,但是这B个物体必须是同一类的。为什么?因为一个cell智能得到1×30的张量,张量中的后20个是20个类别,由于类间竞争,这20类得分不同,但是对于这B个不同的boxes,这20个得分都是一样的。无论与B各boxes中的哪个物体存在的置信度相乘,20类中最大值依旧每个bounding box乘积结果的最大值。因此只能预测同一类别。
【损失函数】
损失函数类型:sum-squared error,即均方误差和。
存在的问题:与最大化平均精度不同步
- 不合理的设定:定位误差与分类误差等权重;
- 可能大部分cell不包含物体,对应的置信度得分为0,对训练而言,梯度更新受到这类大量的负样本影响,导致训练模型不稳定,或提前收敛;
- 大小物体的预测也是等权重,这时小box的误差偏差会大于大box的误差偏差;
- 设置参数lamda_coord=5,增加坐标预测的损失;
- 设置参数lamda_noobj=0.5,减少不包含物体的box的置信度预测损失;
- 预测w,h时,用平方根法来替换直接的w,h预测,即预测sqrt(w),sqrt(h);

图7 不同w,h预测策略对比
上图像说明的是:在相同偏移量情况下,要让小物体的偏移误差相对大物体大一些,这样才能更加公平。
另外补充:
bounding box predictor与object之间的一一对应问题:选择与GT的IOU得分最高的一个,作为“负责”的predictor。也就是说,每个predictor能更好地预测certain sizes, aspect ratios, classes of object,并能改进overall recall。
最终的损失函数是一个多部件损失函数:
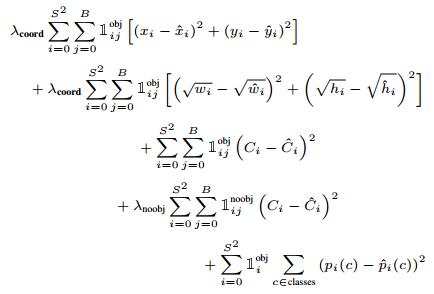

PS:这张图中第一个篮框坐标预测部分,x,y部分打错了,具体看上一张图的对应部分。
注意:损失函数只在cell中存在物体时实行分类误差惩罚,在对存在物体对应的负责的预测器实行定位误差的惩罚。
【后处理】
NMS

图8 NMS操作动图

图9 检测处理后续流程
【优点】
- 快:将检测问题转化为回归问题,使用单个网络实现目标检测,整个流程包装在一个单网络模型中,实现end-to-end快速检测任务;
- 避免FP:可充分利用全图信息,在预测时有着充裕的目标上下文信息,而无局部限制,并且与Faster系列相比,背景false positive少;
- 学的强泛化性特征:能学到高度抽象泛化性的物体表征信息,可迁移到其他邻域中(如艺术品类)。
- 精度上略低于Faster系列:它使用了多次下采样,选取较粗略的特征来做预测,并且直接基于数据来预测box,对于尺度和长宽比参数泛化性较弱;
- 空间局限性:一个cell只能预测B个物体,且这B个物体只能是同一类。对于密集物体和小物体检测效果也不佳;
- 定位效果不够好:大小物体预测时还是等权重的,不可否认的,小物体IOU度量误差会相对大物体小。
【实验结果】






YOLO系列第一部分理解就到此为止,欢迎大家下面提问,YOLOv2和v3接下来在后面的博文中会继续补充。/*2018.04.12*/
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Bernice_lying















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









