







 该博客详细介绍了如何使用SVM实现线性高斯分类,通过实验分析了Perceptron算法的错误率不变性,并探讨了不同核函数(线性、多项式、RBF、Sigmoid)在SVM中的应用和性能评估,展示了优化代码及其结果。
该博客详细介绍了如何使用SVM实现线性高斯分类,通过实验分析了Perceptron算法的错误率不变性,并探讨了不同核函数(线性、多项式、RBF、Sigmoid)在SVM中的应用和性能评估,展示了优化代码及其结果。
实验3:利用SVM实现线性高斯分类
hw3.1
-
Perceptron:
Consider running the Perceptron algorithm on some sequence of examples S (an example is a data point and its label). Let S′ be the same set of examples as S , but presented in a different
-
a) Does the Perceptron algorithm necessarily make the same number of mistakes on S as it does on S′
结论:一样
首先我们知道感知机的误差定义准则为:
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/6091ab51069a8bdf6d8b234e87b4f098.png)
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/4d1c242aafb8be1182c1b6561b484b64.png) 表示所有错误分类样本的集合。某个特定的错误的分类的样本对误差函数的贡献为样本被错误分类的区域中
表示所有错误分类样本的集合。某个特定的错误的分类的样本对误差函数的贡献为样本被错误分类的区域中 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/1c7a330b82678d6b033d9748f5120af9.png) 的线性函数,正确分类的误差函数为零。因此,总的误差函数是分段线性的。
的线性函数,正确分类的误差函数为零。因此,总的误差函数是分段线性的。现在对误差函数使用随机梯度下降算法。得到权重
的变化为:![[公式]](https://i-blog.csdnimg.cn/blog_migrate/1c7a330b82678d6b033d9748f5120af9.png%5E%7B%5Ctau+%2B+1%7D+%3D+w%5E%7B%5Ctau%7D+-+%5Ceta%5Cnabla+E_%7BP%28w%29%7D+%3D++w%5E%7B%5Ctau%7D+%2B+%5Ceta+%5Cphi_%7Bn%7Dt_%7Bn%7D+%5Ctag%7B4%7D)
[公式] 下面基于以上原理进行证明,错误数是相同的
取超平面为
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/f6ec4415642b9b9f134f2c84bbaa7370.png) ,使
,使 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/8fa65cb44662381fd9a0394cf087225f.png)
(此处做了两件事,一是将
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/5ec70aae36c2aca7059a8eb114436bd4.png) 加入了
加入了 的矩阵,即回归,二是将组合后的矩阵归一化)
因为对于有限的
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/86b6b41a263bf69acb42f0764c13bc76.png) .均有
.均有![[公式]](https://i-blog.csdnimg.cn/blog_migrate/a85654363ab05e568ffbe5bba1a4a711.png)
所以存在
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/d341466d38dd48a1ae4ec52e5f200e61.png) ,使得
,使得![[公式]](https://i-blog.csdnimg.cn/blog_migrate/95e72a4b486a01a0659aa84c89657f50.png) (1)
(1)感知器算法中,从
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/33a88bcee55ef561d8a31ab6c6b8c4e5.png) 开始,若输入实例被误分,则更新权重,令
开始,若输入实例被误分,则更新权重,令 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/a9fc4227de233250ca228291537c946e.png) 是第
是第 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/9d4a1163d2eb1bb72228d1279049c2d8.png) 个误分实例之前的扩充权重向量,即
个误分实例之前的扩充权重向量,即 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/a9fc4227de233250ca228291537c946e.png%3D%28w_%7Bk-1%7D%5E%7BT%7D%2Cb_%7Bk-1%7D%29%5E%7BT%7D)
则第k个误分实例的条件是
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/e00eaf14a7674f5e38f03ef516a0659f.png) (2)
(2)而我们知道,若
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/369a8b49e7d5ba2343d87fac4b838efc.png) 被 误分,则 和
被 误分,则 和 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/111cf5c2cf1cc54e0b93080ff933d2e8.png) 的更新是
的更新是即
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/581fd8d2b124ee6f60a174769f2c360e.png) (3)
(3)下面证明俩不等式:
(4)
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/84d9df6a37cc90329f676fe2555177aa.png) **
**由(1)和(3)可得
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/429232cd1ee9a16d0350c057465d9fb7.png)
由此递推可得 (4)
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/41cbfc09740640c3a8f0c44418b9a81c.png)
(5)
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/b4cbce766e6b3923d037ed02e5799f29.png) **
**由(2)和(3)得
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/421c3f4e9911985825f19b0eab800dd7.png)
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/ad931ff5b62e76f485d957739f204535.png)
-
b) If so, why? If not, show such an S and S′ where the Perceptron algorithm makes a different number of mistakes on S′ than it does on S
上题已证
-
-
自己的一些问题:
-
在用感知机的时候,对偶形式为啥比原始形式高效?
-
hw3.2
-
A proposed kernel Consider the following kernel function:

image-20201012220743793 -
a) Prove this is a legal kernel. That is, describe an implicit mapping Φ : such that K x, x′ x′) = x ) Φ( x′x′). (You may assume the instance space X is finite.)
要证明核矩阵是合法的,只需要证明
由题意知:
且对于映射:
 ,若
,若 。所以假设输入空间X是一个有限维度的向量,则
。所以假设输入空间X是一个有限维度的向量,则
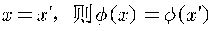
显然,K矩阵满足:
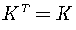 ,是对称矩阵。
,是对称矩阵。不妨去K矩阵为10阶方阵:
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2393
2393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









