







一.基础概念
CAP理论由如下三点组成:
1.一致性(Consistency):等同于所有节点访问同一份(意味着所有的数据节点里面的数据要是一致的)最新的(意味着这些一致的数据他们不能都是错误的)数据副本;
2.可用性(Availability):每次请求都能获取到非错的响应,但不能保证获取的数据为最新数据(意味着给我一个成功的相应即可);
3.分区容错性(Partition Tolerance):以实际效果而言,分区相当于对通信的时限要求,系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。(更易懂的解释:分区容忍性是尽管任意数量的消息被节点间的网络丢失或延迟,也就是时间出现问题了,数据会丢失,网络会丢包,但是系统仍然正常运行)
关键点:对于一个分布式系统来说,不可能同时满足C、A、P三点,如下图所以,C、A、P三者是没有交集的:
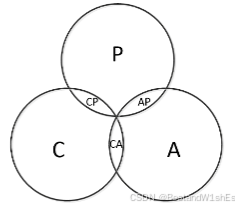
二.理论理解
1.CAP理论的 C 不等于 事务ACID特性中的C:
(1)事务的一致性,指的是一致性状态,比如A给B转一百块,A和B的总金额在事务前、事务中、事务后的都是一样的,这里是两个值之间的关系;
(2)CAP理论中的C理解为副本一致性,是一个值的关系,即所有副本给出的结果都一致;
2.什么原因造成C、A、P三者不能共存的?
(1)在没有网络分区和网络波动的情况下,我们无需为了P而舍弃C或A,而出现网络分区或网络波动时,为了保证P,就要舍弃C和A中的一个;
(2)暂时不考虑目前已有的保障分布式一致性的算法(Quorum Replication、Consensus算法)等任何技术的前提下,先假设有三个副本,我们对三个副本的操作有两种方案:
1)一写的方案,向三个副本写入,只要一个副本返回写入成功即认为成功:
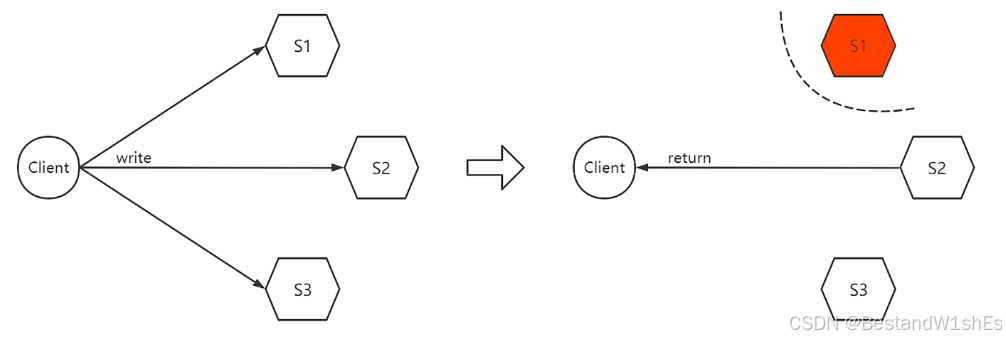
从上图分析:Client向三个Server写入数据,其中只有Server2有返回数据,Client就任务写入成功了,并且可以进行接下来的操作,但是如下在发送的过程中,Server1和其他节点的网络都中断了,那么它的值就根Server2、Server3出现了不一致,这个时候我们的C的一致性就没办法保证了,但是因为Client没有因为Server1的网络分区故障而影响它接下来的执行步骤,所以说它的可用性是得到了保障的。
简单来说就是:一写的情况下,只要一个副本写入成功即可返回写入成功,出现网络分区后,三台机器的数据就可能出现不一致,无法保证C,但因为可以正常返回写入成功,A依旧可以保证。
2)三写的方案,向三个副本写入,三个副本都返回写入成功才认为成功:
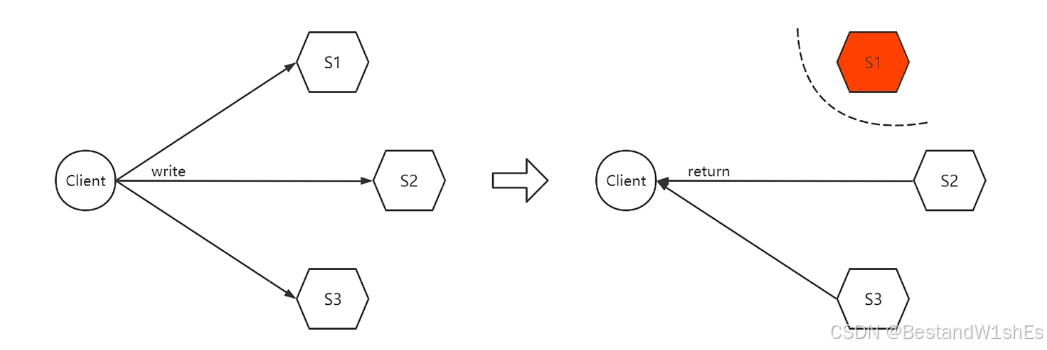
从上图分析:Client向三个Server发送写请求,但是只有三个Server同时返回写入成功,Client才会认为写入成功并进行接下来操作,Server1出现了网络分区的故障后,Client就收不到Server1返回的写入成功的标志,那么最后是一个报错的标志,没有保证可用性,但是因为Server2和Server3的写入,最后也会被撤销,所以保证了一致性。
简单来说就是:三写的情况下,要三个副本都写入成功才可返回成功,出现网络分区后,无法实现这最终会返回报错,所以没有保证A,但保证了C。
总结:
在分布式环境下,P是一定存在的(因为我们很难完全避免在分布式网络中出现网络分区故障),一旦出现了网络分区,那么一致性和可用性就一定要抛弃一个,这就意味着我们的系统通常是一个AP或者CP的系统。
三.用CAP理论分析分布式数据库
1.对于NoSQL数据库,更加注重可用性,所以就会是一个AP系统;
2.对于分布式关系型数据库,必须要保证一致性,所以就会是一个CP系统,但分布式关系型数据库仍有高可用性需求,虽然达不到CAP理论中的100%可用性,但一般都具备五个9(99.999%)以上的高可用,我们可以把分布式关系型数据库看作 CP+HA 的系统,也由此产生了两个广泛应用的指标:
(1)RPO(Recovery Point Objective):恢复点目标,指数据库在灾难发生后会丢失多长时间的数据,分布式关系型数据库RPO=0;(PRO对应的就是CAP理论中的C,如果我的副本得到了所有最新数据,只要我的副本没有全军覆没,总会有一个副本保留下最新的数据,那么我的RPO就等于0,代表我们没有丢失任何数据)
(2)RTO(Recovery Time Objective):恢复时间目标,指数据库在灾难发生后到整个系统恢复正常所需要的时间,分布式关系型数据库RTO<几分钟。(因为我们分布式数据库没有具备CAP理论中的百分之一百可用性,所以说分布式关系数据库的RTO不能为零,但是因为我们保证了high availability,我们做了一些主备切换、重新选主的过程,我们还是可以恢复正常的服务的,所以说分布式关系数据库的RTO通常会小于几分钟,像OceanBase、TiDB 一些基于paxos 或者raft 的协议的分布式关系数据库,他们的RTO都小于30s,通常这个RTO都是我们可以接受的
四.辩证看待CAP理论
CAP理论可谓是分布式领域一个“臭名昭著”的理论,有以下两点原因:
1.它是一个证明你不能做什么的理论,就像能量守恒一样,不允许你设计出永动机来,CAP理论也从原理上面限制了分布式系统设计者设计不出一个完美的分布式系统;
2.它的C和A条件都太过极端,很多了解不够深入的设计者就喜欢生搬硬套,搞得像C和A选择了一个就必须完全抛弃另一个一样,实际上,我们在设计一个系统时,更多的是要选择C和A中的一个,对其进行“降级”,以此进行妥协,也就是trade off的一个过程。
五.CAP视角看目前成熟的分布式方案
Quorum Replication:
1.它有三个关键字:N(副本数),W(写入成功副本数),R(读取成功副本数);
2.它的关键点就是 W+R > N,这就意味着永远都有一个副本是最新且正确的,在N等于3的情况下,有两中常见设计:
(1)N=3,W=1,R=3(写可用AP,读一致CP),比如一个记录流水的系统,流水是源源不断产生,要持续记录的,所以不能容忍吸入的阻塞,所以写入追求可用性,而我读取流水可以容忍暂时的失败,但是我不可以容忍我读取到的数据是不正确的或者是老旧的,所以读取追求一致性;
(2)N=3,W=3,R=1(写一致CP,读可用AP),比如一个电子商务系统,商家去修改商品的金额,商家修改金额可以暂时的失败或者是被阻塞,相对的,电子商务系统会面对很多购买者用户读取商品金额的请求,这些请求的压力比较大,所以说一定要保证他们的可用性,并且尽量的去把这个压力负载到所有的副本上面,所以说R就需要等于1,这个时候读就是追求一个可用性状态。
共识算法:
副本之间有交互,会选取出一个leader提供读写,单leader没有出现故障的情况下,它的C和A都是可以保证的,如果leader宕了选一个新leader,只有选举的短暂过程不可用,所以说公司算法是一个CP+HA的状态。

















 148
148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









