







Part1摘要
图神经网络(gnn)通过图节点间的递归信息交换和聚合,具有高级的图结构理解能力。为了提高模型的鲁棒性,自监督学习(SSL)已经成为一种很有前途的数据增强方法。然而,现有的生成预训练图嵌入的方法通常依赖于特定下游任务标签的微调,这限制了它们在标记数据稀缺或不可用的情况下的可用性。为了解决这个问题,我们的研究重点是在具有挑战性的零射击学习场景中提高图模型的泛化能力。受大型语言模型(LLM)成功的启发,我们的目标是开发一个面向图的LLM,它可以跨不同的下游数据集和任务实现高泛化,即使没有任何来自下游图数据的信息。在这项工作中,我们提出了GraphGPT框架,该框架将llm与图结构知识与图指令调优范例结合起来。我们的框架包含一个文本-图形接地组件,以建立文本信息和图形结构之间的连接。
此外,我们提出了一个双阶段的指令调整范例,伴随着一个轻量级的图形-文本对齐投影仪。该范式探讨了自监督图结构信号和任务特定图指令,以指导法学硕士理解复杂图结构并提高其在不同下游任务中的适应性。我们的框架在监督和零概率图学习任务上进行了评估,展示了卓越的泛化和优于最先进的基线。
Part2前言
如何有效地将大型语言模型与图学习集成起来是一项巨大的挑战:
-
构信息与语言空间的对齐: 图数据具有图结构特性,而大型语言模型主要在语言空间中进行训练/学习。如何有效地将图的结构信息与语言空间进行对齐,使得模型能够同时理解图的结构和语义信息是具有挑战的
-
引导大语言模型理解图的结构信息: 为了使大型语言模型能够有效地理解图的结构信息,需要设计适当的指令目标来要求模型理解图数据中的结构信息
-
赋予大语言模型图学习下游任务的逐步推理能力: 在图学习的下游任务中,逐步推理是一个重要的能力。这意味着模型需要根据图的结构信息和语义信息,逐步推断出更复杂的关系和属性
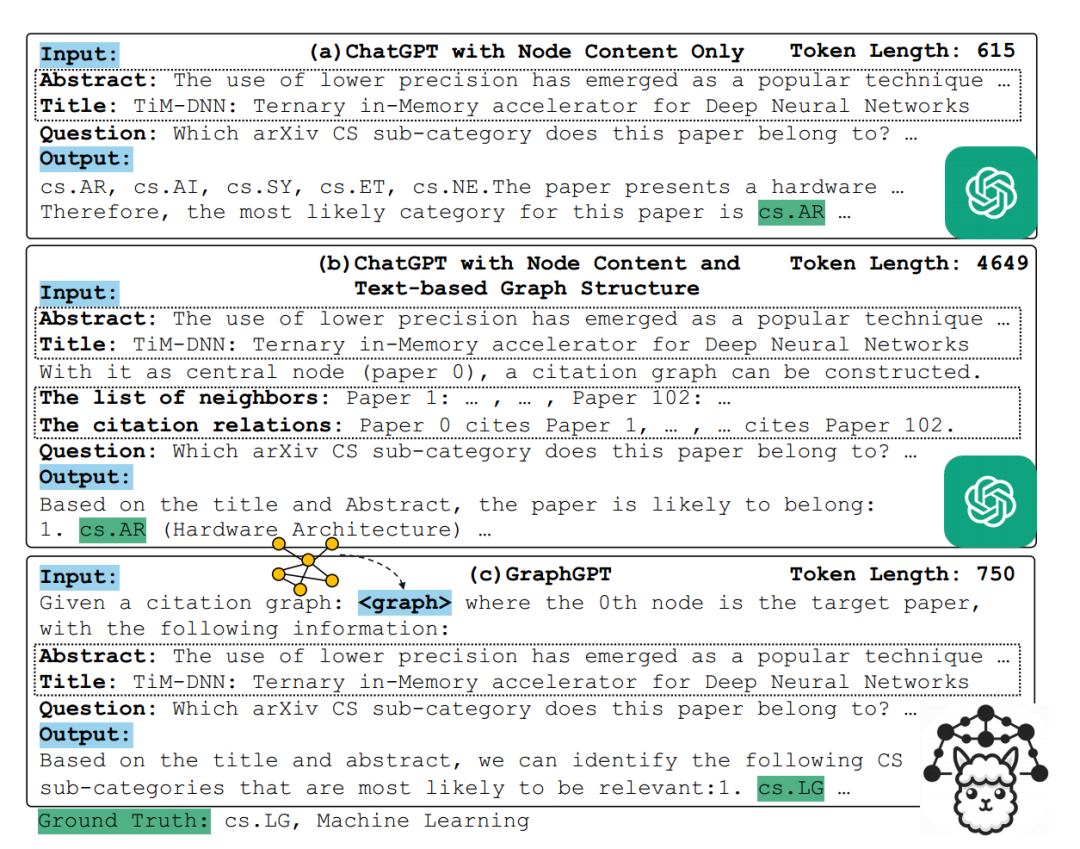
为了更深入地探索仅通过纯文本提示进行图结构建模的局限性,本文进行了大量实验和比较。上图实验揭示了仅依赖文本提示可能会遇到的问题。以引文网络节点为例:
例(a)仅使用输入节点的文本数据(引文摘要和标题),然后提问目标节点的类别。
例(b)采用基于文本的图形结构prompt,输入节点的邻接关系,然后提问目标节点的类别。
发现预测结果都是错误的,揭示了仅依赖纯文本提示进行图结构建模的潜在限制。此外使用基于文本的结构性提示会导致令牌大小的增加,增大了成本消耗。
于是本文提出GraphGPT,解决上述挑战:
-
GraphGPT 引入了一个“文本-图结构”数据对齐范式,通过结合文本信息的对比学习,在图编码器中实现了文本语义的有效对齐。
-
提出的双阶段图指令调优范式。在第一阶段,利用无标签的图结构数据,通过自监督的图匹配任务来引导大型语言模型获取与图数据相关的结构性知识,从而增强对图结构的理解。在第二阶段,为了进一步优化大型语言模型在各种下游图学习任务中的推理能力,我们使用特定任务的图数据指令对模型进行微调,增强其适应性。
-
最后,通过采用Chain-of-Thought (COT)方法,将闭源的大型语言模型(如 ChatGPT)整合到 GraphGPT 中,提升了模型的逐步推理能力,并显著降低了由于分布偏移带来的性能下降。
Part3方法介绍
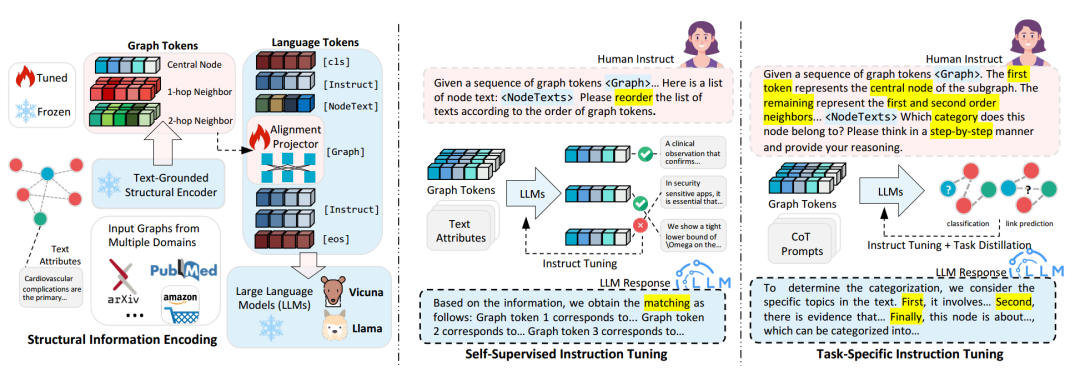
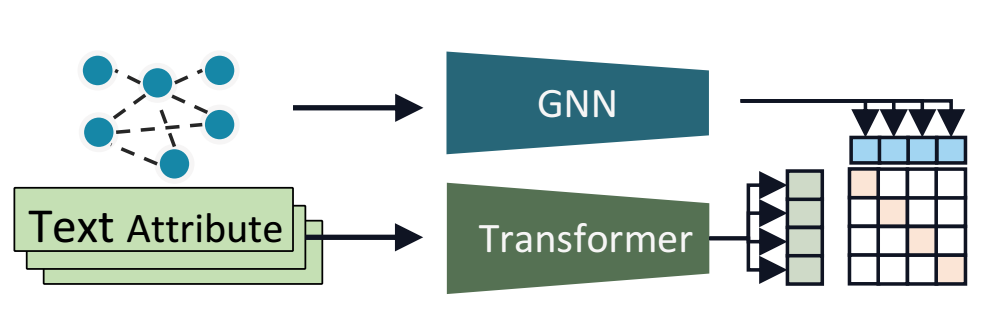
GraphGPT的整体的框架图如上图所示:(1)首先对齐图结构和文本结构利用GNN的图编码器提取图的表征,利用BERT的文本编码器提取文本表征,进行对比学习,通过最小化损失来优化随机初始化的图编码器。(2)然后进行一个自监督的指令微调,通过一个图匹配任务,指导语言模型识别图中的各个节点。(3)随后进行第三步——特定任务指令微调,以满足不同学习任务的特定约束和要求,如节点分类或链路预测等。
1用“文本-图”对齐编码结构信息
GraphGPT探索了与大型语言模型良好协作的图结构编码方式。受之前的研究启发,本文以对比的方式将文本信息融入图结构的编码过程中, 将带有预训练参数的图编码器集成到模型框架中。通过任意图编码器
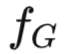
(例如 经过预训练的 graph transformer)和文本编码器
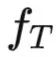
(例如Bert)得到编码后的图表示H和文本表示T,接着进一步使用范数函数进行行级l2归一化。
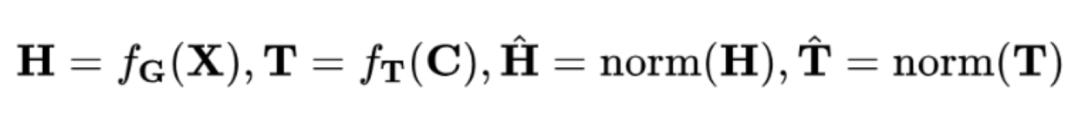
接着,通过对比学习进行不同维度的“文本-图结构”数据对齐:
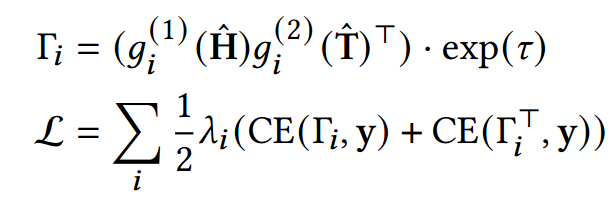
其中
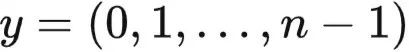
为对比标签,g为不同对比策略的转换函数,训练过程是为了优化图编码器。
2自监督指令微调
在图指令微调范式的第一阶段,我们采用了自监督的指令微调策略,该策略将图结构的专有知识融入到语言模型之中,增强了其推理能力,并使其能够准确地捕获图结构中的关联信息。GraphGPT设计了一个结构感知的图匹配任务,指导语言模型利用自然语言标签来识别图中的各个节点。
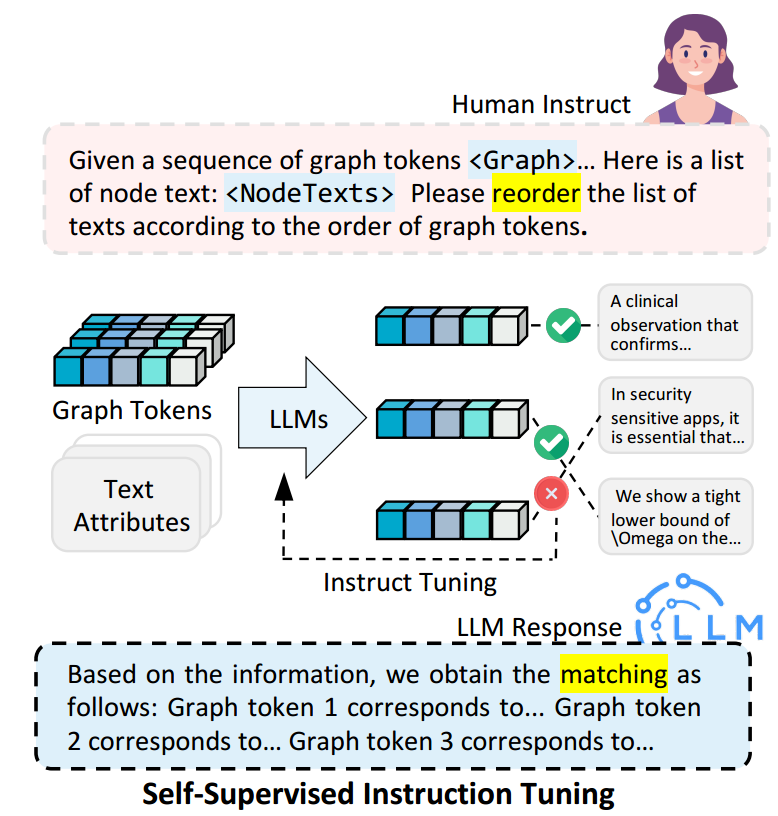
指令设计
图匹配任务的指令包括三个部分:图信息,人类问题以及GraphGPT 的回答在图匹配任务中,将图中的每个节点视为中心节点,执行 h 跳的随机邻居采样,从而得到一个子图结构。大语言模型的自然语言输入是人类的问题。在图匹配任务的上下文中,指令包括指示符令牌<graph>和一个被打乱的节点文本信息列表。例如,在一个论文引用图中,节点文本信息对应于论文标题。大语言模型在图匹配任务中的目标是将每个图结点 token 与其相应的节点文本信息对齐。这需要根据图结点 token 的顺序重新排序节点文本信息列表,有效地将每个图结点 token 与其相关的文本描述关联起来。
微调策略
为了高效地优化微调过程,本文提出了一种轻量级对齐投影策略。在训练过程中,固定大语言模型和图编码器的参数,仅专注于优化投影器可以用一个单一的线性层实现。这个投影器建立了图结点 token 和自然语言 token 之间的对应关系。通过在原始自然语言 token 序列中替换指示符 token<graph>为对齐的图结点 token 序列 {<graph_begin>,<graph_token>1, ...,<graph_token>n,<graph_end>},从而得到了一个大语言模型的输入 token 序列。训练后,假设投影器已经成功地学会了将编码的图表示映射到图结点 token,而大语言模型则擅长将这些图结点 token 与多种节点文本信息对齐。
3特定任务指令微调
特定任务指令微调旨在定制模型的推理行为,以满足不同图学习任务的特定约束和要求,如节点分类或链接预测。通过使用任务特定的图指令对大语言模型进行微调,引导模型生成更适合当前图学习任务的响应,进一步提高了模型在处理各种图学习任务时的适应性和性能。
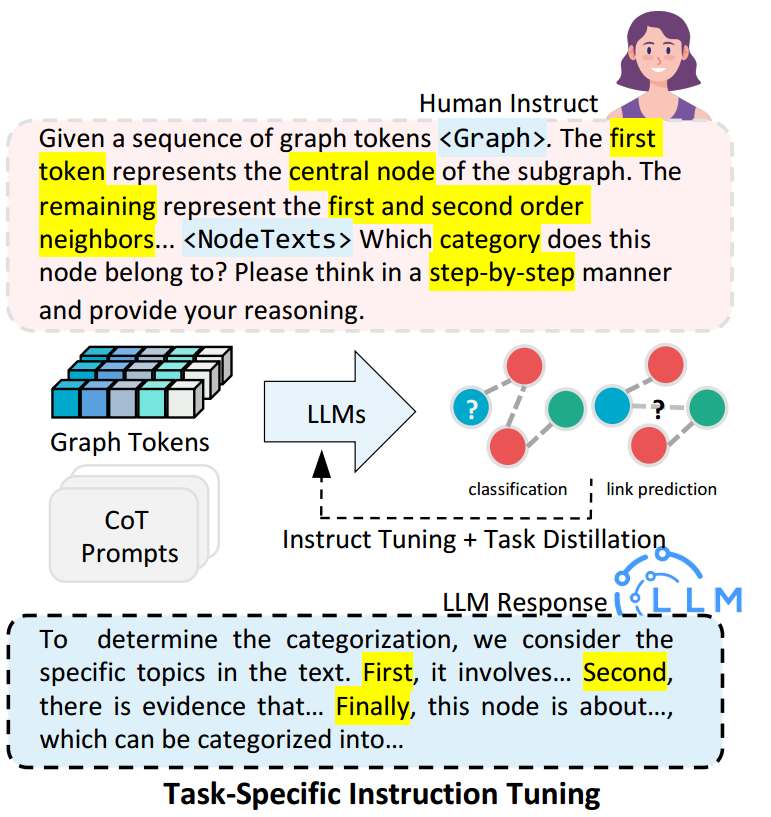
指令设计

为了为每个节点生成图信息,采用第一阶段相同的邻居采样方法。对于节点分类任务,人类问题指令包含指示符令牌 <graph>和关于中心节点的特定文本信息。这个指令提示语言模型基于图结构数据和伴随的文本信息来预测中心节点的类别。在上图中可以看到不同任务的指令数据的模版。
微调策略
训练的第二阶段使用第一阶段训练得到的结构感知投影器的参数作为初始状态,在训练过程中,保持大语言模型和图编码器的参数不变,仅专注于优化前一阶段的投影器的参数,确保大语言模型进一步与下游任务对齐,增强其理解和解释图结构的能力。
完成上述的两个训练阶段后,GraphGPT 已经获得了理解给定图结构并在提供的图上执行各种下游任务的能力。
思维链蒸馏
面对各种图数据,语言模型可能会碰到之前未曾接触过的模式和结构。这种数据分布的差异可能会影响模型生成准确且流畅的答案,尤其是当不同图数据中的节点类别数量发生变化时。为了在数据分布发生变化时仍然保持高准确率,赋予 GraphGPT 逐步推断的能力变得尤为关键。受到思维链(Chain-of-Thought)方法的启示,我们提出通过融合思维链方法来增强 GraphGPT 文本生成的连续性和准确性,使其能够按照逻辑顺序进行思考,从而更好地理解和推断给定的图数据。
但是,由于思维链方法的效果与模型的参数大小紧密相关,如何在较小的模型中充分利用思维链方法的优势成了一个关键问题。为了解决这个问题,我们借鉴了先前的研究方法,从一个封闭的、大规模的语言模型(例如 GPT-3.5,参数超过 2000 亿)中提取思维链的推理技巧,使 GraphGPT 能够生成高品质的答案,同时增强其逐步推理的能力,而不增加额外的参数。
对于论文引用图的节点分类任务,我们将节点所代表的论文的摘要、标题和分类任务描述作为输入,利用 GPT-3.5 语言模型进行逐步推断,通过连续的思考流程得出答案。在生成的输出中,大语言模型不仅为节点类别做出预测,还为每个预测提供了详尽的解释,确保了模型的决策过程是清晰和可追踪的。为了进一步优化性能,我们将生成的思维链指令数据与之前为任务特定指令微调阶段制定的指令结合起来,进行图指令的微调。
Part3实验
1总体性能
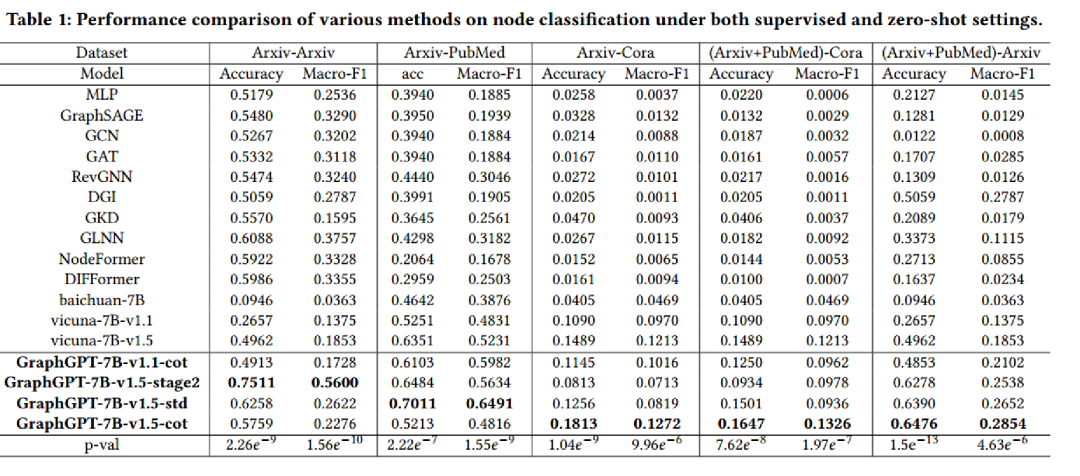
Obs.1 总体性能优越性:GraphGPT 在有监督和零样本环境中均稳定地胜过了众多先进的基线模型。值得关注的是,尽管近期研发的基于 GNN 的强大模型,如 NodeFormer、DIFFormer 和 GKD,在有监督的环境中都展现了出色的结构建模能力,但在迁移到未经进一步训练的新数据集时,其性能大幅下滑。与此相对,GraphGPT 不仅在有监督任务中胜过了所有最优方法,而且在零样本图学习中实现了显著的 2-10 倍的准确性增长。
此外,像 Baichuan-7B 和 Vicuna-7B 这样基于大语言模型的方案在各种数据集中都表现稳定,但它们主要基于文本信息进行预测。而 GraphGPT 则有效地融合了图结构信息,为图学习任务提供了更为完善的解决方案。
Obs.2 结构感知的图匹配任务:第一阶段指令微调中的自监督图匹配任务,对于提升 GraphGPT 的零样本迁移能力起到了核心作用。这一阶段的核心在于将携带丰富结构信息的图节点 token 与语言 token 进行匹配。这种匹配方式使得模型能更加深入地掌握图数据的内在结构特点。
如果缺少这一阶段,模型仅在第二阶段进行特定任务的指令微调,那么模型更容易在某一特定数据集上产生过拟合。在这种情况下,模型的表现可能过于依赖于数据集的特定模式和特征,而不是真正的图结构理解,这可能会限制模型对新的、未曾见过的数据集的泛化能力。
Obs.3 思维链蒸馏:“-std” 和 “-cot” 变体表明,采用思维链蒸馏对于更为复杂的图学习任务具有显著的助益。使用标准指令数据集进行微调的模型在迁移到简单任务上,例如只有 3 个类别的 PubMed 数据集时,已经能够获得显著的效果,如 Arxiv-PubMed 的准确率达到 0.7011。
但是,当面对如 Cora 这样有 70 个类别的复杂任务时,它们的表现仅为一般。通过思维链蒸馏,借助闭源模型(GPT-3.5)的强大推断力,模型能够整合这些知识和推理技巧,并在复杂的图任务上大幅提升性能。
2消融实验

图结构微调的影响:在这部分研究中,我们采用了 “w/o GS” 变体来探索将图结构信息融入大语言模型的优势。在此变体中,我们直接使用大语言模型基座(即Vicuna-7B-v1.5)在三个数据集上执行节点分类,而不考虑图结构信息。实验结果表明,GraphGPT 明显胜过没有结构信息的基础模型。这证明了我们提出的图结构微调方法能使大语言模型更深入地理解图结构信息。值得注意的是,这种性能提升是在不更改大语言模型原始参数的前提下达到的。相反,这完全是通过一个轻量级的对齐投影器实现的,该投影器通过线性投影操作将图节点 token 与自然语言 token 对齐。
大语言模型增强的语义推理效果:在这部分,我们通过只使用默认图编码器进行有监督和零样本预测来评估大语言模型的推理效果对 GraphGPT 的贡献,此变体被命名为 “w/o LR”。实验结果显示,融合大语言模型的 GraphGPT 显著增强了图编码器的表现,尤其是在零样本场景中。这说明大语言模型带来的丰富语义信息为模型性能提供了显著的提升。
Part4总结
本研究提出了一种高效且具有扩展性的图结构大语言模型,目标是增强图结构模型的泛化性。我们介绍的框架,GraphGPT,采用了双阶段的图指令微调方法,将图相关的结构性知识融入到大语言模型中。通过一个简单而有效的“图-文”对齐投影器,该模型得以理解并解读图的结构性信息。在多种环境下的综合评估显示,该模型在有监督和零样本的图学习场景中均表现出色。
参考资料
文章链接:https://arxiv.org/abs/2310.13023
原文链接:通用图大模型GraphGPT















 15
15

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









